 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Formalizing LLM Agent Security
Mar 19, 2026Security in LLM agents is inherently contextual. For example, the same action taken by an agent may represent legitimate behavior or a security violation depending on whose instruction led to the action, what objective is being pursued, and whether the action serves that objective. However, existing definitions of security attacks against LLM agents often fail to capture this contextual nature. As a result, defenses face a fundamental utility-security tradeoff: applying defenses uniformly across all contexts can lead to significant utility loss, while applying defenses in insufficient or inappropriate contexts can result in security vulnerabilities. In this work, we present a framework that systematizes existing attacks and defenses from the perspective of contextual security. To this end, we propose four security properties that capture contextual security for LLM agents: task alignment (pursuing authorized objectives), action alignment (individual actions serving those objectives), source authorization (executing commands from authenticated sources), and data isolation (ensuring information flows respect privilege boundaries). We further introduce a set of oracle functions that enable verification of whether these security properties are violated as an agent executes a user task. Using this framework, we reformalize existing attacks, such as indirect prompt injection, direct prompt injection, jailbreak, task drift, and memory poisoning, as violations of one or more security properties, thereby providing precise and contextual definitions of these attacks. Similarly, we reformalize defenses as mechanisms that strengthen oracle functions or perform security property checks. Finally, we discuss several important future research directions enabled by our framework.
Order Matters in Retrosynthesis: Structure-aware Generation via Reaction-Center-Guided Discrete Flow Matching
Feb 13, 2026Template-free retrosynthesis methods treat the task as black-box sequence generation, limiting learning efficiency, while semi-template approaches rely on rigid reaction libraries that constrain generalization. We address this gap with a key insight: atom ordering in neural representations matters. Building on this insight, we propose a structure-aware template-free framework that encodes the two-stage nature of chemical reactions as a positional inductive bias. By placing reaction center atoms at the sequence head, our method transforms implicit chemical knowledge into explicit positional patterns that the model can readily capture. The proposed RetroDiT backbone, a graph transformer with rotary position embeddings, exploits this ordering to prioritize chemically critical regions. Combined with discrete flow matching, our approach decouples training from sampling and enables generation in 20--50 steps versus 500 for prior diffusion methods. Our method achieves state-of-the-art performance on both USPTO-50k (61.2% top-1) and the large-scale USPTO-Full (51.3% top-1) with predicted reaction centers. With oracle centers, performance reaches 71.1% and 63.4% respectively, surpassing foundation models trained on 10 billion reactions while using orders of magnitude less data. Ablation studies further reveal that structural priors outperform brute-force scaling: a 280K-parameter model with proper ordering matches a 65M-parameter model without it.
ALPBench: A Benchmark for Attribution-level Long-term Personal Behavior Understanding
Feb 03, 2026Recent advances in large language models have highlighted their potential for personalized recommendation, where accurately capturing user preferences remains a key challenge. Leveraging their strong reasoning and generalization capabilities, LLMs offer new opportunities for modeling long-term user behavior. To systematically evaluate this, we introduce ALPBench, a Benchmark for Attribution-level Long-term Personal Behavior Understanding. Unlike item-focused benchmarks, ALPBench predicts user-interested attribute combinations, enabling ground-truth evaluation even for newly introduced items. It models preferences from long-term historical behaviors rather than users' explicitly expressed requests, better reflecting enduring interests. User histories are represented as natural language sequences, allowing interpretable, reasoning-based personalization. ALPBench enables fine-grained evaluation of personalization by focusing on the prediction of attribute combinations task that remains highly challenging for current LLMs due to the need to capture complex interactions among multiple attributes and reason over long-term user behavior sequences.
Persona-aware and Explainable Bikeability Assessment: A Vision-Language Model Approach
Jan 07, 2026Bikeability assessment is essential for advancing sustainable urban transportation and creating cyclist-friendly cities, and it requires incorporating users' perceptions of safety and comfort. Yet existing perception-based bikeability assessment approaches face key limitations in capturing the complexity of road environments and adequately accounting for heterogeneity in subjective user perceptions. This paper proposes a persona-aware Vision-Language Model framework for bikeability assessment with three novel contributions: (i) theory-grounded persona conditioning based on established cyclist typology that generates persona-specific explanations via chain-of-thought reasoning; (ii) multi-granularity supervised fine-tuning that combines scarce expert-annotated reasoning with abundant user ratings for joint prediction and explainable assessment; and (iii) AI-enabled data augmentation that creates controlled paired data to isolate infrastructure variable impacts. To test and validate this framework, we developed a panoramic image-based crowdsourcing system and collected 12,400 persona-conditioned assessments from 427 cyclists. Experiment results show that the proposed framework offers competitive bikeability rating prediction while uniquely enabling explainable factor attribution.
VMDT: Decoding the Trustworthiness of Video Foundation Models
Nov 07, 2025As foundation models become more sophisticated, ensuring their trustworthiness becomes increasingly critical; yet, unlike text and image, the video modality still lacks comprehensive trustworthiness benchmarks. We introduce VMDT (Video-Modal DecodingTrust), the first unified platform for evaluating text-to-video (T2V) and video-to-text (V2T) models across five key trustworthiness dimensions: safety, hallucination, fairness, privacy, and adversarial robustness. Through our extensive evaluation of 7 T2V models and 19 V2T models using VMDT, we uncover several significant insights. For instance, all open-source T2V models evaluated fail to recognize harmful queries and often generate harmful videos, while exhibiting higher levels of unfairness compared to image modality models. In V2T models, unfairness and privacy risks rise with scale, whereas hallucination and adversarial robustness improve -- though overall performance remains low. Uniquely, safety shows no correlation with model size, implying that factors other than scale govern current safety levels. Our findings highlight the urgent need for developing more robust and trustworthy video foundation models, and VMDT provides a systematic framework for measuring and tracking progress toward this goal. The code is available at https://sunblaze-ucb.github.io/VMDT-page/.
RepIt: Representing Isolated Targets to Steer Language Models
Sep 16, 2025While activation steering in large language models (LLMs) is a growing area of research, methods can often incur broader effects than desired. This motivates isolation of purer concept vectors to enable targeted interventions and understand LLM behavior at a more granular level. We present RepIt, a simple and data-efficient framework for isolating concept-specific representations. Across five frontier LLMs, RepIt enables precise interventions: it selectively suppresses refusal on targeted concepts while preserving refusal elsewhere, producing models that answer WMD-related questions while still scoring as safe on standard benchmarks. We further show that the corrective signal localizes to just 100-200 neurons and that robust target representations can be extracted from as few as a dozen examples on a single A6000. This efficiency raises a dual concern: manipulations can be performed with modest compute and data to extend to underrepresented data-scarce topics while evading existing benchmarks. By disentangling refusal vectors with RepIt, this work demonstrates that targeted interventions can counteract overgeneralization, laying the foundation for more granular control of model behavior.
VisR-Bench: An Empirical Study on Visual Retrieval-Augmented Generation for Multilingual Long Document Understanding
Aug 10, 2025Most organizational data in this world are stored as documents, and visual retrieval plays a crucial role in unlocking the collective intelligence from all these documents. However, existing benchmarks focus on English-only document retrieval or only consider multilingual question-answering on a single-page image. To bridge this gap, we introduce VisR-Bench, a multilingual benchmark designed for question-driven multimodal retrieval in long documents. Our benchmark comprises over 35K high-quality QA pairs across 1.2K documents, enabling fine-grained evaluation of multimodal retrieval. VisR-Bench spans sixteen languages with three question types (figures, text, and tables), offering diverse linguistic and question coverage. Unlike prior datasets, we include queries without explicit answers, preventing models from relying on superficial keyword matching. We evaluate various retrieval models, including text-based methods, multimodal encoders, and MLLMs, providing insights into their strengths and limitations. Our results show that while MLLMs significantly outperform text-based and multimodal encoder models, they still struggle with structured tables and low-resource languages, highlighting key challenges in multilingual visual retrieval.
EVA-MILP: Towards Standardized Evaluation of MILP Instance Generation
May 30, 2025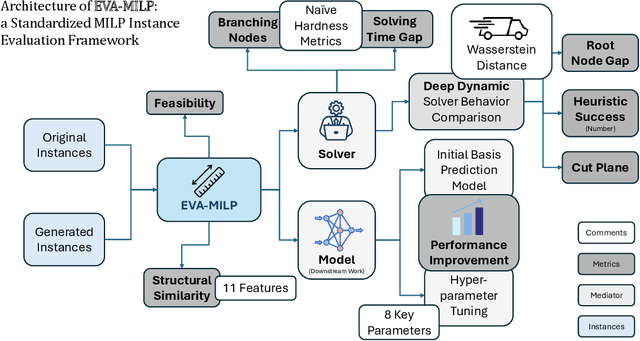
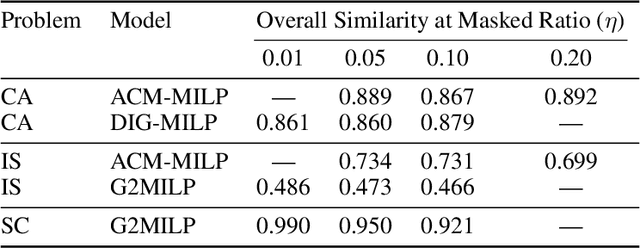
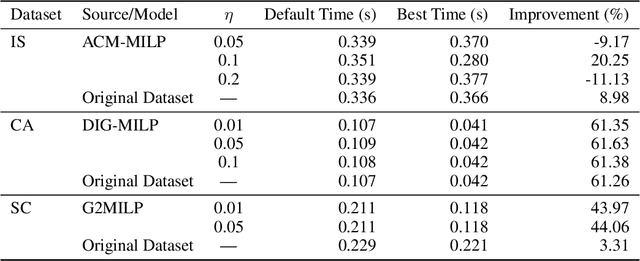
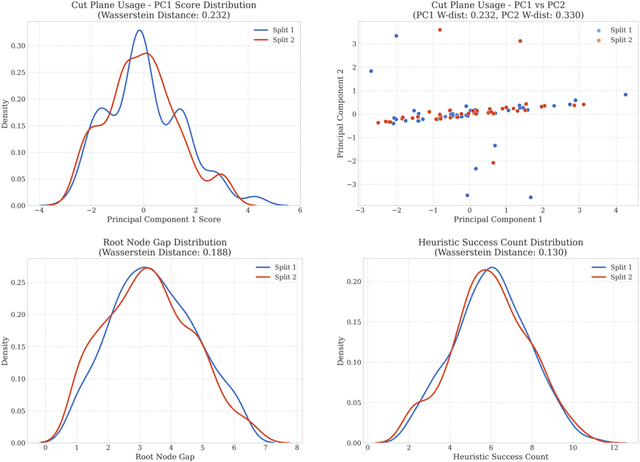
Mixed-Integer Linear Programming (MILP) is fundamental to solving complex decision-making problems. The proliferation of MILP instance generation methods, driven by machine learning's demand for diverse optimization datasets and the limitations of static benchmarks, has significantly outpaced standardized evaluation techniques. Consequently, assessing the fidelity and utility of synthetic MILP instances remains a critical, multifaceted challenge. This paper introduces a comprehensive benchmark framework designed for the systematic and objective evaluation of MILP instance generation methods. Our framework provides a unified and extensible methodology, assessing instance quality across crucial dimensions: mathematical validity, structural similarity, computational hardness, and utility in downstream machine learning tasks. A key innovation is its in-depth analysis of solver-internal features -- particularly by comparing distributions of key solver outputs including root node gap, heuristic success rates, and cut plane usage -- leveraging the solver's dynamic solution behavior as an `expert assessment' to reveal nuanced computational resemblances. By offering a structured approach with clearly defined solver-independent and solver-dependent metrics, our benchmark aims to facilitate robust comparisons among diverse generation techniques, spur the development of higher-quality instance generators, and ultimately enhance the reliability of research reliant on synthetic MILP data. The framework's effectiveness in systematically comparing the fidelity of instance sets is demonstrated using contemporary generative models.
Importance Weighted Score Matching for Diffusion Samplers with Enhanced Mode Coverage
May 26, 2025Training neural samplers directly from unnormalized densities without access to target distribution samples presents a significant challenge. A critical desideratum in these settings is achieving comprehensive mode coverage, ensuring the sampler captures the full diversity of the target distribution. However, prevailing methods often circumvent the lack of target data by optimizing reverse KL-based objectives. Such objectives inherently exhibit mode-seeking behavior, potentially leading to incomplete representation of the underlying distribution. While alternative approaches strive for better mode coverage, they typically rely on implicit mechanisms like heuristics or iterative refinement. In this work, we propose a principled approach for training diffusion-based samplers by directly targeting an objective analogous to the forward KL divergence, which is conceptually known to encourage mode coverage. We introduce \textit{Importance Weighted Score Matching}, a method that optimizes this desired mode-covering objective by re-weighting the score matching loss using tractable importance sampling estimates, thereby overcoming the absence of target distribution data. We also provide theoretical analysis of the bias and variance for our proposed Monte Carlo estimator and the practical loss function used in our method. Experiments on increasingly complex multi-modal distributions, including 2D Gaussian Mixture Models with up to 120 modes and challenging particle systems with inherent symmetries -- demonstrate that our approach consistently outperforms existing neural samplers across all distributional distance metrics, achieving state-of-the-art results on all benchmarks.
Where You Go is Who You Are: Behavioral Theory-Guided LLMs for Inverse Reinforcement Learning
May 22, 2025Big trajectory data hold great promise for human mobility analysis, but their utility is often constrained by the absence of critical traveler attributes, particularly sociodemographic information. While prior studies have explored predicting such attributes from mobility patterns, they often overlooked underlying cognitive mechanisms and exhibited low predictive accuracy. This study introduces SILIC, short for Sociodemographic Inference with LLM-guided Inverse Reinforcement Learning (IRL) and Cognitive Chain Reasoning (CCR), a theoretically grounded framework that leverages LLMs to infer sociodemographic attributes from observed mobility patterns by capturing latent behavioral intentions and reasoning through psychological constructs. Particularly, our approach explicitly follows the Theory of Planned Behavior (TPB), a foundational behavioral framework in transportation research, to model individuals' latent cognitive processes underlying travel decision-making. The LLMs further provide heuristic guidance to improve IRL reward function initialization and update by addressing its ill-posedness and optimization challenges arising from the vast and unstructured reward space. Evaluated in the 2017 Puget Sound Regional Council Household Travel Survey, our method substantially outperforms state-of-the-art baselines and shows great promise for enriching big trajectory data to support more behaviorally grounded applications in transportation planning and beyond.