 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient and Explainable Transformer-Based Few-Shot Learning for Modeling Electricity Consumption Profiles Across Thousands of Domains
Aug 15, 2024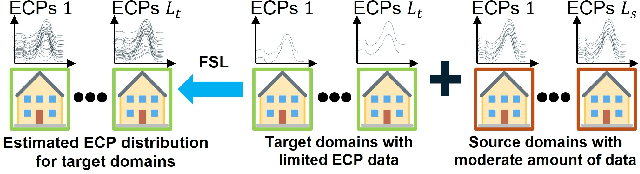
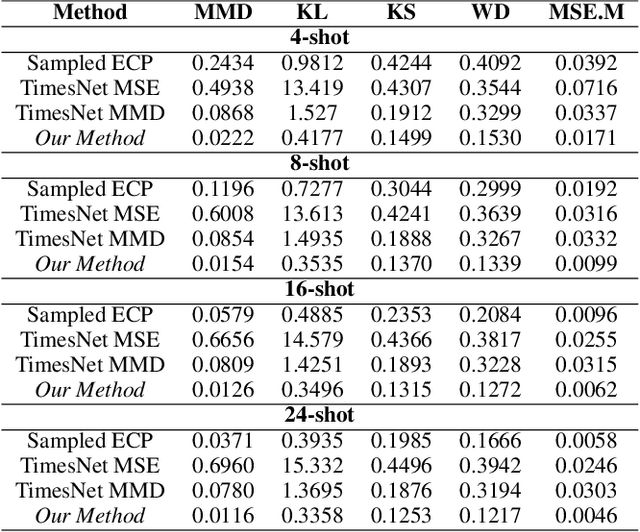
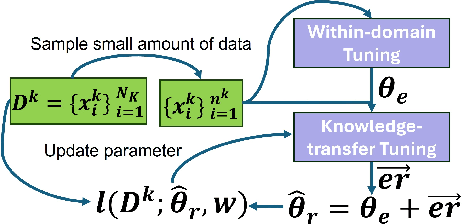
Electricity Consumption Profiles (ECPs) are crucial for operating and planning power distribution systems, especially with the increasing numbers of various low-carbon technologies such as solar panels and electric vehicles. Traditional ECP modeling methods typically assume the availability of sufficient ECP data. However, in practice, the accessibility of ECP data is limited due to privacy issues or the absence of metering devices. Few-shot learning (FSL) has emerged as a promising solution for ECP modeling in data-scarce scenarios. Nevertheless, standard FSL methods, such as those used for images, are unsuitable for ECP modeling because (1) these methods usually assume several source domains with sufficient data and several target domains. However, in the context of ECP modeling, there may be thousands of source domains with a moderate amount of data and thousands of target domains. (2) Standard FSL methods usually involve cumbersome knowledge transfer mechanisms, such as pre-training and fine-tuning, whereas ECP modeling requires more lightweight methods. (3) Deep learning models often lack explainability, hindering their application in industry. This paper proposes a novel FSL method that exploits Transformers and Gaussian Mixture Models (GMMs) for ECP modeling to address the above-described issues. Results show that our method can accurately restore the complex ECP distribution with a minimal amount of ECP data (e.g., only 1.6\% of the complete domain dataset) while it outperforms state-of-the-art time series modeling methods, maintaining the advantages of being both lightweight and interpretable. The project is open-sourced at https://github.com/xiaweijie1996/TransformerEM-GMM.git.
MOMAland: A Set of Benchmarks for Multi-Objective Multi-Agent Reinforcement Learning
Jul 23, 2024



Many challenging tasks such as managing traffic systems, electricity grids, or supply chains involve complex decision-making processes that must balance multiple conflicting objectives and coordinate the actions of various independent decision-makers (DMs). One perspective for formalising and addressing such tasks is multi-objective multi-agent reinforcement learning (MOMARL). MOMARL broadens reinforcement learning (RL) to problems with multiple agents each needing to consider multiple objectives in their learning process. In reinforcement learning research, benchmarks are crucial in facilitating progress, evaluation, and reproducibility. The significance of benchmarks is underscored by the existence of numerous benchmark frameworks developed for various RL paradigms, including single-agent RL (e.g., Gymnasium), multi-agent RL (e.g., PettingZoo), and single-agent multi-objective RL (e.g., MO-Gymnasium). To support the advancement of the MOMARL field, we introduce MOMAland, the first collection of standardised environments for multi-objective multi-agent reinforcement learning. MOMAland addresses the need for comprehensive benchmarking in this emerging field, offering over 10 diverse environments that vary in the number of agents, state representations, reward structures, and utility considerations. To provide strong baselines for future research, MOMAland also includes algorithms capable of learning policies in such settings.
PGT: A Progressive Method for Training Models on Long Videos
Mar 21, 2021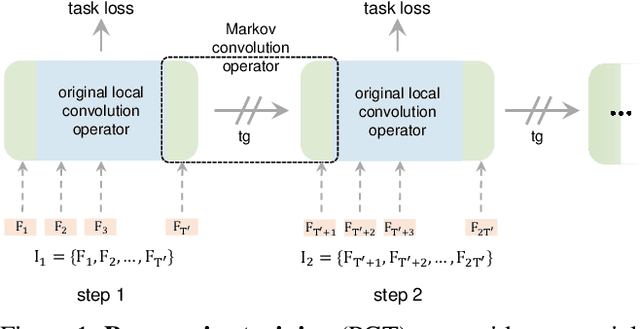
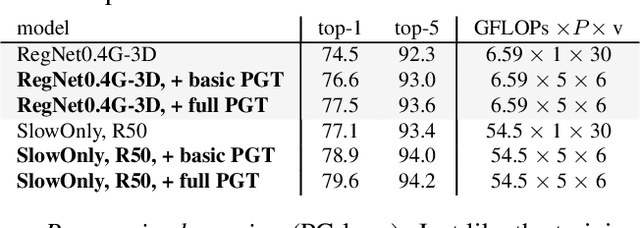
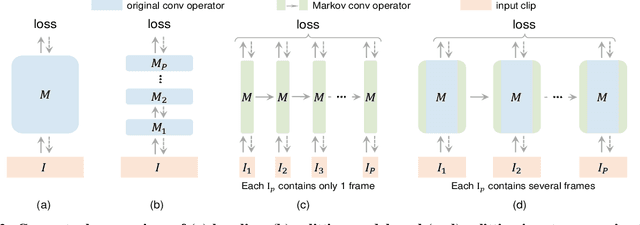
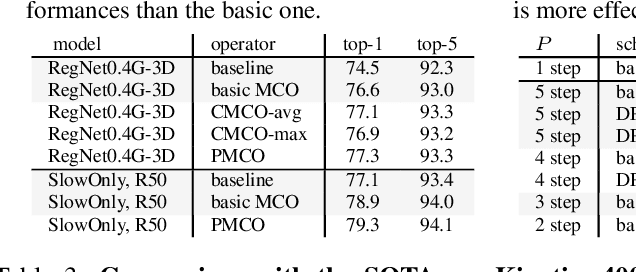
Convolutional video models have an order of magnitude larger computational complexity than their counterpart image-level models. Constrained by computational resources, there is no model or training method that can train long video sequences end-to-end. Currently, the main-stream method is to split a raw video into clips, leading to incomplete fragmentary temporal information flow. Inspired by natural language processing techniques dealing with long sentences, we propose to treat videos as serial fragments satisfying Markov property, and train it as a whole by progressively propagating information through the temporal dimension in multiple steps. This progressive training (PGT) method is able to train long videos end-to-end with limited resources and ensures the effective transmission of information. As a general and robust training method, we empirically demonstrate that it yields significant performance improvements on different models and datasets. As an illustrative example, the proposed method improves SlowOnly network by 3.7 mAP on Charades and 1.9 top-1 accuracy on Kinetics with negligible parameter and computation overhead. Code is available at https://github.com/BoPang1996/PGT.
* CVPR21, Oral
Dynamic Fusion with Intra- and Inter- Modality Attention Flow for Visual Question Answering
Dec 13, 2018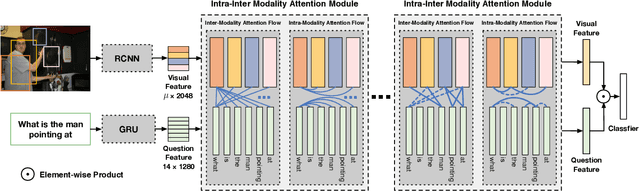

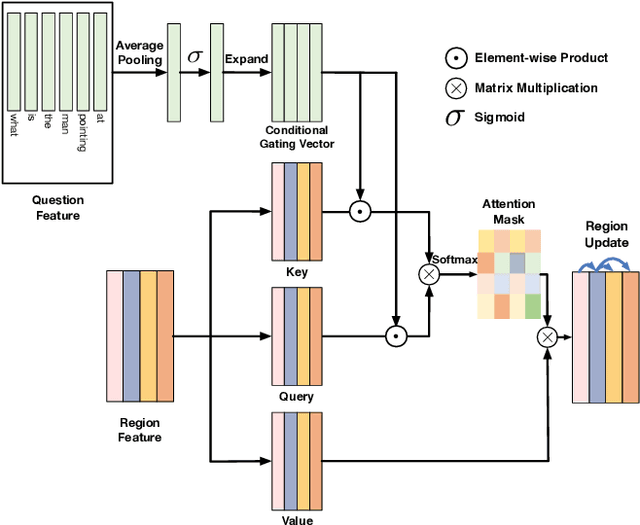
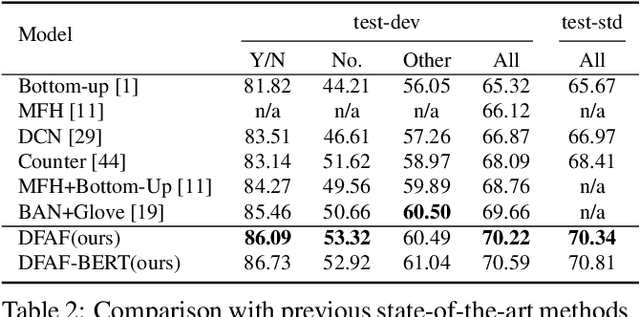
Learning effective fusion of multi-modality features is at the heart of visual question answering. We propose a novel method of dynamically fusing multi-modal features with intra- and inter-modality information flow, which alternatively pass dynamic information between and across the visual and language modalities. It can robustly capture the high-level interactions between language and vision domains, thus significantly improves the performance of visual question answering. We also show that the proposed dynamic intra-modality attention flow conditioned on the other modality can dynamically modulate the intra-modality attention of the target modality, which is vital for multimodality feature fusion. Experimental evaluations on the VQA 2.0 dataset show that the proposed method achieves state-of-the-art VQA performance. Extensive ablation studies are carried out for the comprehensive analysis of the proposed method.
Estimating 6D Pose From Localizing Designated Surface Keypoints
Dec 04, 2018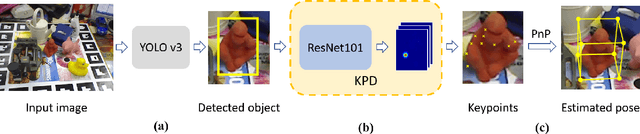


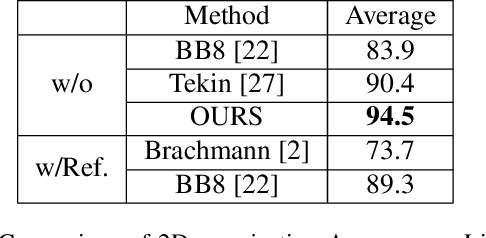
In this paper, we present an accurate yet effective solution for 6D pose estimation from an RGB image. The core of our approach is that we first designate a set of surface points on target object model as keypoints and then train a keypoint detector (KPD) to localize them. Finally a PnP algorithm can recover the 6D pose according to the 2D-3D relationship of keypoints. Different from recent state-of-the-art CNN-based approaches that rely on a time-consuming post-processing procedure, our method can achieve competitive accuracy without any refinement after pose prediction. Meanwhile, we obtain a 30% relative improvement in terms of ADD accuracy among methods without using refinement. Moreover, we succeed in handling heavy occlusion by selecting the most confident keypoints to recover the 6D pose. For the sake of reproducibility, we will make our code and models publicly available soon.