 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Thoughts Are Not Secret: Reasoning Trace Exposure in LLMs
May 30, 2026Reasoning traces have become a valuable form of learning signals for improving and transferring the capabilities of large language models. In particular, detailed traces can help distill reasoning behavior from stronger teacher models into weaker student models. The value of capability transfer has motivated many deployed systems with reasoning models to hide raw internal traces and expose at most summaries and answers to users. As a result, we ask whether such interface-level trace hiding prevents users from obtaining useful reasoning supervision through prompting. We study this question with Reasoning Exposure Prompting (REP), a lightweight in-context elicitation method that uses shadow-model-generated demonstrations wrapped in auxiliary code-like formats to raise user-visible reasoning traces from a victim model. Across the common reasoning dataset, different victim models, and different student model distillation, REP substantially increases similarity between exposed and REP-conditioned internal traces while preserving useful reasoning signals.
Web Agents Should Adopt the Plan-Then-Execute Paradigm
May 14, 2026ReAct has become the default architecture across LLM agents, and many existing web agents follow this paradigm. We argue that it is the wrong default for web agents. Instead, web agents should default to plan-then-execute: commit to a task-specific program before observing runtime web content, then execute it. The reason is that web content mixes inputs from many parties. An e-commerce product page may combine a seller's listing, customer reviews and sponsored advertisements. Under ReAct, all of this content flows into the model when deciding on the next action, creating a direct path for prompt injections to steer the agent's control flow. Plan-then-execute changes this boundary: untrusted data may influence values or branches inside a predefined execution graph, but it cannot redefine the user task or cause the model to synthesize new actions at runtime. We analyze WebArena, a popular web agent benchmark, and find that all tasks are compatible with plan-then-execute, while 80% can be completed with a purely programmatic plan, without any runtime LLM subroutine. We identify the main barrier to adopting plan-then-execute on the web: For it to work well, tools must map cleanly to semantic actions, with effects known before execution, so agents have enough information to plan. The web does not naturally expose that interface. Browser tools such as click, type, and scroll have page-dependent meanings. Planning at this layer is near-sighted: the agent can only see actions on the current page, and later actions appear only after it acts. Closing this gap requires typed interfaces that turn website interactions from clicks and keystrokes to task-level operations. This is an infrastructure problem, not a modeling problem. Web tasks do not need reactivity by default; they need typed, complete, auditable website APIs.
GradShield: Alignment Preserving Finetuning
May 13, 2026Large Language Models (LLMs) pose a significant risk of safety misalignment after finetuning, as models can be compromised by both explicitly and implicitly harmful data. Even some seemingly benign data can inadvertently steer a model towards misaligned behaviors. To address this, we introduce GradShield, a principled filtering method that safeguards LLMs during finetuning by identifying and removing harmful data points before they corrupt the model's alignment. It removes potentially harmful data by computing a Finetuning Implicit Harmfulness Score (FIHS) for each data point and employs an adaptive thresholding algorithm. We apply GradShield to multiple utility fine-tuning tasks across varying levels of harmful data and evaluate the safety and utility performance of the resulting LLMs using various metrics. The results show that GradShield outperforms all baseline methods, consistently maintaining an Attack Success Rate (ASR) below $6\%$ while preserving utility performance.
Onyx: Cost-Efficient Disk-Oblivious ANN Search
Apr 22, 2026Approximate nearest neighbor (ANN) search in AI systems increasingly handles sensitive data on third-party infrastructure. Trusted execution environments (TEEs) offer protection, but cost-efficient deployments must rely on external SSDs, which leaks user queries through disk access patterns to the host. Oblivious RAM (ORAM) can hide these access patterns but at a high cost; when paired with existing disk-based ANN search techniques, it makes poor use of SSD resources, yielding high latency and poor cost-efficiency. The core challenge for efficient oblivious ANN search over SSDs is balancing both bandwidth and access count. The state-of-the-art ORAM-ANN design minimizes access count at the ANN level and bandwidth at the ORAM level, each trading-off the other, leaving the combined system with both resources overutilized. We propose inverting this design, minimizing bandwidth consumption in the ANN layer and access count in the ORAM layer, since each component is better suited for its new role: ANN's inherent approximation allows for more bandwidth efficiency, while ORAM has no fundamental lower bounds on access count (as opposed to bandwidth). To this end, we propose a cost-efficient approach, Onyx, with two new co-designed components: Onyx-ANNS introduces a compact intermediate representation that proactively prunes the majority of bandwidth-intensive accesses without hurting recall, and Onyx-ORAM proposes a locality-aware shallow tree design that reduces access count while remaining compatible with bandwidth-efficient ORAM techniques. Compared to the state-of-the-art oblivious ANN search system, Onyx achieves $1.7-9.9\times$ lower cost and $2.3-12.3\times$ lower latency.
Opal: Private Memory for Personal AI
Apr 02, 2026Personal AI systems increasingly retain long-term memory of user activity, including documents, emails, messages, meetings, and ambient recordings. Trusted hardware can keep this data private, but struggles to scale with a growing datastore. This pushes the data to external storage, which exposes retrieval access patterns that leak private information to the application provider. Oblivious RAM (ORAM) is a cryptographic primitive that can hide these patterns, but it requires a fixed access budget, precluding the query-dependent traversals that agentic memory systems rely on for accuracy. We present Opal, a private memory system for personal AI. Our key insight is to decouple all data-dependent reasoning from the bulk of personal data, confining it to the trusted enclave. Untrusted disk then sees only fixed, oblivious memory accesses. This enclave-resident component uses a lightweight knowledge graph to capture personal context that semantic search alone misses and handles continuous ingestion by piggybacking reindexing and capacity management on every ORAM access. Evaluated on a comprehensive synthetic personal-data pipeline driven by stochastic communication models, Opal improves retrieval accuracy by 13 percentage points over semantic search and achieves 29x higher throughput with 15x lower infrastructure cost than a secure baseline. Opal is under consideration for deployment to millions of users at a major AI provider.
MiniScope: A Least Privilege Framework for Authorizing Tool Calling Agents
Dec 11, 2025



Tool calling agents are an emerging paradigm in LLM deployment, with major platforms such as ChatGPT, Claude, and Gemini adding connectors and autonomous capabilities. However, the inherent unreliability of LLMs introduces fundamental security risks when these agents operate over sensitive user services. Prior approaches either rely on manually written policies that require security expertise, or place LLMs in the confinement loop, which lacks rigorous security guarantees. We present MiniScope, a framework that enables tool calling agents to operate on user accounts while confining potential damage from unreliable LLMs. MiniScope introduces a novel way to automatically and rigorously enforce least privilege principles by reconstructing permission hierarchies that reflect relationships among tool calls and combining them with a mobile-style permission model to balance security and ease of use. To evaluate MiniScope, we create a synthetic dataset derived from ten popular real-world applications, capturing the complexity of realistic agentic tasks beyond existing simplified benchmarks. Our evaluation shows that MiniScope incurs only 1-6% latency overhead compared to vanilla tool calling agents, while significantly outperforming the LLM based baseline in minimizing permissions as well as computational and operational costs.
Auditing Black-Box LLM APIs with a Rank-Based Uniformity Test
Jun 08, 2025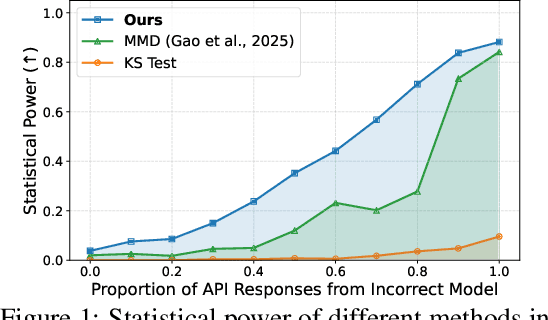

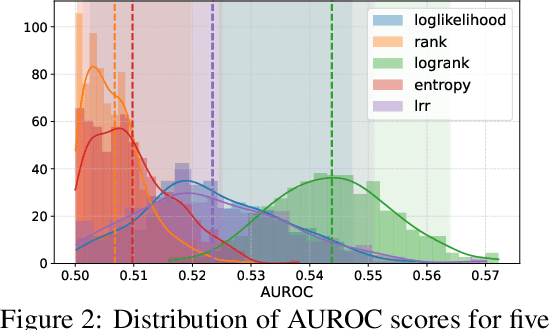
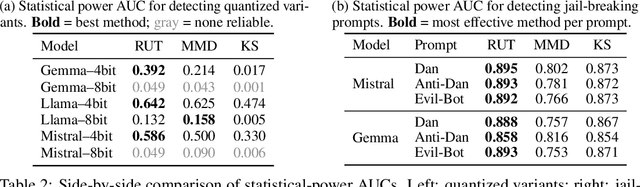
As API access becomes a primary interface to large language models (LLMs), users often interact with black-box systems that offer little transparency into the deployed model. To reduce costs or maliciously alter model behaviors, API providers may discreetly serve quantized or fine-tuned variants, which can degrade performance and compromise safety. Detecting such substitutions is difficult, as users lack access to model weights and, in most cases, even output logits. To tackle this problem, we propose a rank-based uniformity test that can verify the behavioral equality of a black-box LLM to a locally deployed authentic model. Our method is accurate, query-efficient, and avoids detectable query patterns, making it robust to adversarial providers that reroute or mix responses upon the detection of testing attempts. We evaluate the approach across diverse threat scenarios, including quantization, harmful fine-tuning, jailbreak prompts, and full model substitution, showing that it consistently achieves superior statistical power over prior methods under constrained query budgets.
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
A Framework for Evaluating Emerging Cyberattack Capabilities of AI
Mar 14, 2025As frontier models become more capable, the community has attempted to evaluate their ability to enable cyberattacks. Performing a comprehensive evaluation and prioritizing defenses are crucial tasks in preparing for AGI safely. However, current cyber evaluation efforts are ad-hoc, with no systematic reasoning about the various phases of attacks, and do not provide a steer on how to use targeted defenses. In this work, we propose a novel approach to AI cyber capability evaluation that (1) examines the end-to-end attack chain, (2) helps to identify gaps in the evaluation of AI threats, and (3) helps defenders prioritize targeted mitigations and conduct AI-enabled adversary emulation to support red teaming. To achieve these goals, we propose adapting existing cyberattack chain frameworks to AI systems. We analyze over 12,000 instances of real-world attempts to use AI in cyberattacks catalogued by Google's Threat Intelligence Group. Using this analysis, we curate a representative collection of seven cyberattack chain archetypes and conduct a bottleneck analysis to identify areas of potential AI-driven cost disruption. Our evaluation benchmark consists of 50 new challenges spanning different phases of cyberattacks. Based on this, we devise targeted cybersecurity model evaluations, report on the potential for AI to amplify offensive cyber capabilities across specific attack phases, and conclude with recommendations on prioritizing defenses. In all, we consider this to be the most comprehensive AI cyber risk evaluation framework published so far.
JudgeBench: A Benchmark for Evaluating LLM-based Judges
Oct 16, 2024
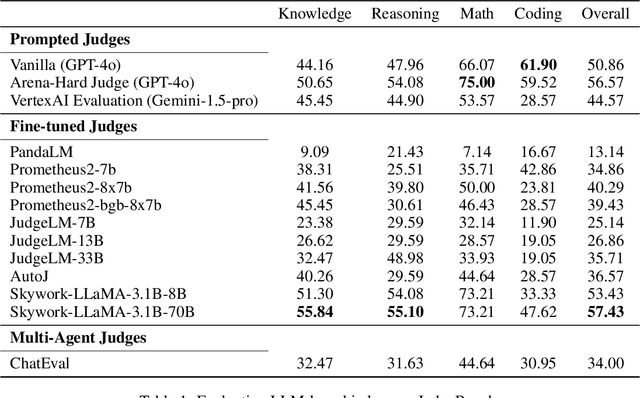
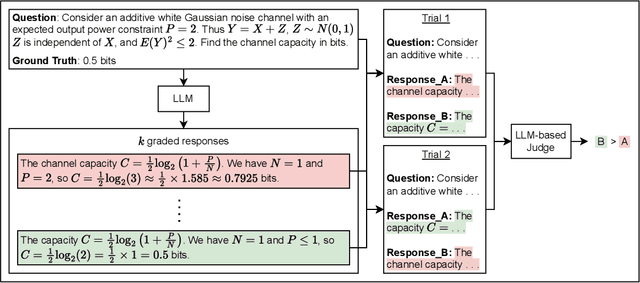
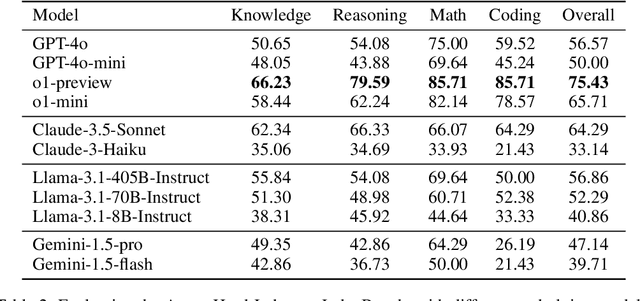
LLM-based judges have emerged as a scalable alternative to human evaluation and are increasingly used to assess, compare, and improve models. However, the reliability of LLM-based judges themselves is rarely scrutinized. As LLMs become more advanced, their responses grow more sophisticated, requiring stronger judges to evaluate them. Existing benchmarks primarily focus on a judge's alignment with human preferences, but often fail to account for more challenging tasks where crowdsourced human preference is a poor indicator of factual and logical correctness. To address this, we propose a novel evaluation framework to objectively evaluate LLM-based judges. Based on this framework, we propose JudgeBench, a benchmark for evaluating LLM-based judges on challenging response pairs spanning knowledge, reasoning, math, and coding. JudgeBench leverages a novel pipeline for converting existing difficult datasets into challenging response pairs with preference labels reflecting objective correctness. Our comprehensive evaluation on a collection of prompted judges, fine-tuned judges, multi-agent judges, and reward models shows that JudgeBench poses a significantly greater challenge than previous benchmarks, with many strong models (e.g., GPT-4o) performing just slightly better than random guessing. Overall, JudgeBench offers a reliable platform for assessing increasingly advanced LLM-based judges. Data and code are available at https://github.com/ScalerLab/JudgeBench .