 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
MiniScope: A Least Privilege Framework for Authorizing Tool Calling Agents
Dec 11, 2025



Tool calling agents are an emerging paradigm in LLM deployment, with major platforms such as ChatGPT, Claude, and Gemini adding connectors and autonomous capabilities. However, the inherent unreliability of LLMs introduces fundamental security risks when these agents operate over sensitive user services. Prior approaches either rely on manually written policies that require security expertise, or place LLMs in the confinement loop, which lacks rigorous security guarantees. We present MiniScope, a framework that enables tool calling agents to operate on user accounts while confining potential damage from unreliable LLMs. MiniScope introduces a novel way to automatically and rigorously enforce least privilege principles by reconstructing permission hierarchies that reflect relationships among tool calls and combining them with a mobile-style permission model to balance security and ease of use. To evaluate MiniScope, we create a synthetic dataset derived from ten popular real-world applications, capturing the complexity of realistic agentic tasks beyond existing simplified benchmarks. Our evaluation shows that MiniScope incurs only 1-6% latency overhead compared to vanilla tool calling agents, while significantly outperforming the LLM based baseline in minimizing permissions as well as computational and operational costs.
Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!
Feb 11, 2025Large reasoning models (LRMs) tackle complex reasoning problems by following long chain-of-thoughts (Long CoT) that incorporate reflection, backtracking, and self-validation. However, the training techniques and data requirements to elicit Long CoT remain poorly understood. In this work, we find that a Large Language model (LLM) can effectively learn Long CoT reasoning through data-efficient supervised fine-tuning (SFT) and parameter-efficient low-rank adaptation (LoRA). With just 17k long CoT training samples, the Qwen2.5-32B-Instruct model achieves significant improvements on a wide range of math and coding benchmarks, including 56.7% (+40.0%) on AIME 2024 and 57.0% (+8.1%) on LiveCodeBench, competitive to the proprietary o1-preview model's score of 44.6% and 59.1%. More importantly, we find that the structure of Long CoT is critical to the learning process, whereas the content of individual reasoning steps has minimal impact. Perturbations affecting content, such as training on incorrect samples or removing reasoning keywords, have little impact on performance. In contrast, structural modifications that disrupt logical consistency in the Long CoT, such as shuffling or deleting reasoning steps, significantly degrade accuracy. For example, a model trained on Long CoT samples with incorrect answers still achieves only 3.2% lower accuracy compared to training with fully correct samples. These insights deepen our understanding of how to elicit reasoning capabilities in LLMs and highlight key considerations for efficiently training the next generation of reasoning models. This is the academic paper of our previous released Sky-T1-32B-Preview model. Codes are available at https://github.com/NovaSky-AI/SkyThought.
GoEX: Perspectives and Designs Towards a Runtime for Autonomous LLM Applications
Apr 10, 2024Large Language Models (LLMs) are evolving beyond their classical role of providing information within dialogue systems to actively engaging with tools and performing actions on real-world applications and services. Today, humans verify the correctness and appropriateness of the LLM-generated outputs (e.g., code, functions, or actions) before putting them into real-world execution. This poses significant challenges as code comprehension is well known to be notoriously difficult. In this paper, we study how humans can efficiently collaborate with, delegate to, and supervise autonomous LLMs in the future. We argue that in many cases, "post-facto validation" - verifying the correctness of a proposed action after seeing the output - is much easier than the aforementioned "pre-facto validation" setting. The core concept behind enabling a post-facto validation system is the integration of an intuitive undo feature, and establishing a damage confinement for the LLM-generated actions as effective strategies to mitigate the associated risks. Using this, a human can now either revert the effect of an LLM-generated output or be confident that the potential risk is bounded. We believe this is critical to unlock the potential for LLM agents to interact with applications and services with limited (post-facto) human involvement. We describe the design and implementation of our open-source runtime for executing LLM actions, Gorilla Execution Engine (GoEX), and present open research questions towards realizing the goal of LLMs and applications interacting with each other with minimal human supervision. We release GoEX at https://github.com/ShishirPatil/gorilla/.
RAFT: Adapting Language Model to Domain Specific RAG
Mar 15, 2024
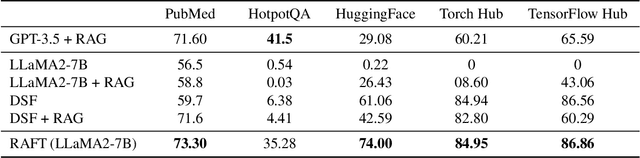
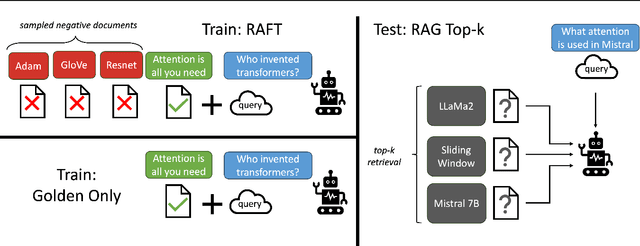
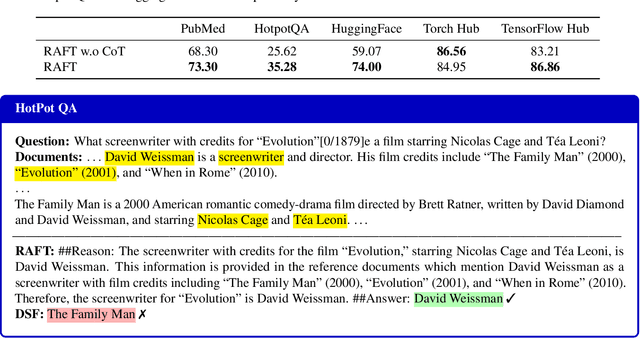
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a "open-book" in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.
MemGPT: Towards LLMs as Operating Systems
Oct 12, 2023



Large language models (LLMs) have revolutionized AI, but are constrained by limited context windows, hindering their utility in tasks like extended conversations and document analysis. To enable using context beyond limited context windows, we propose virtual context management, a technique drawing inspiration from hierarchical memory systems in traditional operating systems that provide the appearance of large memory resources through data movement between fast and slow memory. Using this technique, we introduce MemGPT (Memory-GPT), a system that intelligently manages different memory tiers in order to effectively provide extended context within the LLM's limited context window, and utilizes interrupts to manage control flow between itself and the user. We evaluate our OS-inspired design in two domains where the limited context windows of modern LLMs severely handicaps their performance: document analysis, where MemGPT is able to analyze large documents that far exceed the underlying LLM's context window, and multi-session chat, where MemGPT can create conversational agents that remember, reflect, and evolve dynamically through long-term interactions with their users. We release MemGPT code and data for our experiments at https://memgpt.ai.
Gorilla: Large Language Model Connected with Massive APIs
May 24, 2023
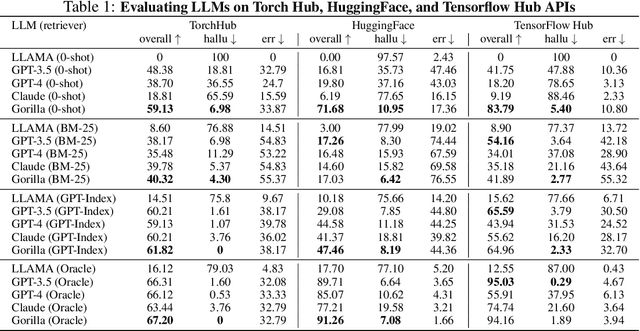
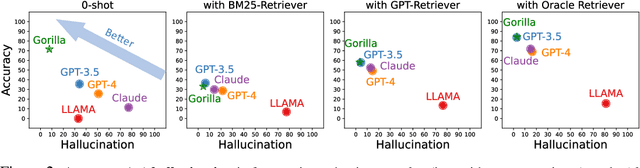
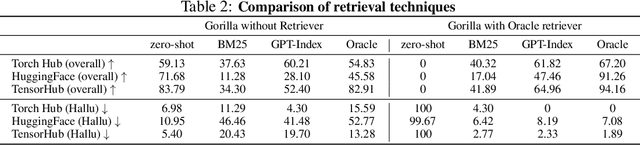
Large Language Models (LLMs) have seen an impressive wave of advances recently, with models now excelling in a variety of tasks, such as mathematical reasoning and program synthesis. However, their potential to effectively use tools via API calls remains unfulfilled. This is a challenging task even for today's state-of-the-art LLMs such as GPT-4, largely due to their inability to generate accurate input arguments and their tendency to hallucinate the wrong usage of an API call. We release Gorilla, a finetuned LLaMA-based model that surpasses the performance of GPT-4 on writing API calls. When combined with a document retriever, Gorilla demonstrates a strong capability to adapt to test-time document changes, enabling flexible user updates or version changes. It also substantially mitigates the issue of hallucination, commonly encountered when prompting LLMs directly. To evaluate the model's ability, we introduce APIBench, a comprehensive dataset consisting of HuggingFace, TorchHub, and TensorHub APIs. The successful integration of the retrieval system with Gorilla demonstrates the potential for LLMs to use tools more accurately, keep up with frequently updated documentation, and consequently increase the reliability and applicability of their outputs. Gorilla's code, model, data, and demo are available at https://gorilla.cs.berkeley.edu
POET: Training Neural Networks on Tiny Devices with Integrated Rematerialization and Paging
Jul 15, 2022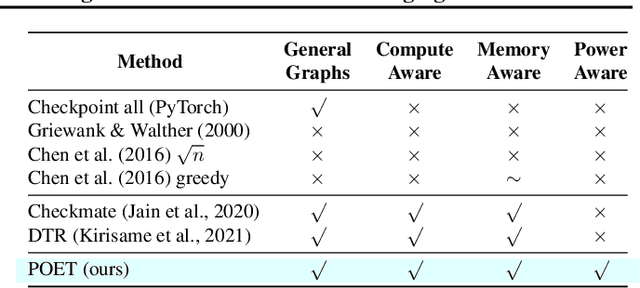
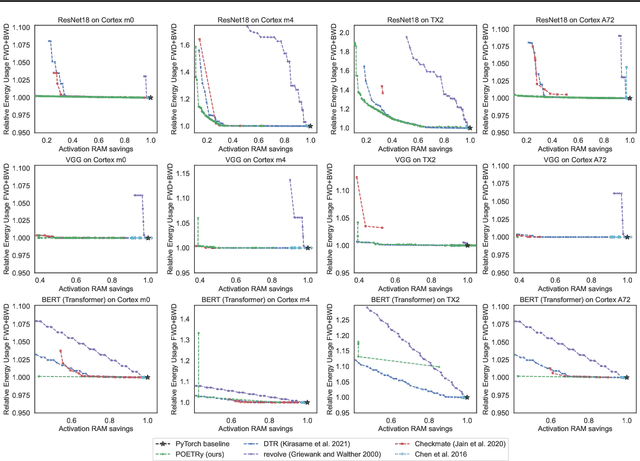
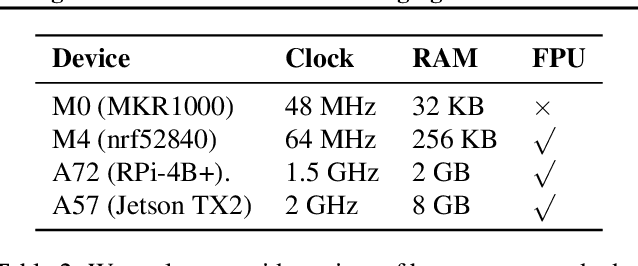
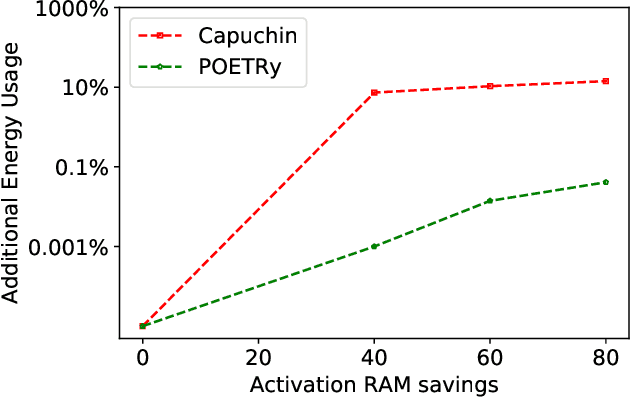
Fine-tuning models on edge devices like mobile phones would enable privacy-preserving personalization over sensitive data. However, edge training has historically been limited to relatively small models with simple architectures because training is both memory and energy intensive. We present POET, an algorithm to enable training large neural networks on memory-scarce battery-operated edge devices. POET jointly optimizes the integrated search search spaces of rematerialization and paging, two algorithms to reduce the memory consumption of backpropagation. Given a memory budget and a run-time constraint, we formulate a mixed-integer linear program (MILP) for energy-optimal training. Our approach enables training significantly larger models on embedded devices while reducing energy consumption while not modifying mathematical correctness of backpropagation. We demonstrate that it is possible to fine-tune both ResNet-18 and BERT within the memory constraints of a Cortex-M class embedded device while outperforming current edge training methods in energy efficiency. POET is an open-source project available at https://github.com/ShishirPatil/poet