 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcurrency without Model Changes: Future-based Asynchronous Function Calling for LLMs
May 14, 2026Function calling, also known as tool use, is a core capability of modern LLM agents but is typically constrained by synchronous execution semantics. Under these semantics, LLM decoding is blocked until each function call completes, resulting in increasing end-to-end latency. In this work, we introduce AsyncFC, a pure execution-layer framework that decouples LLM decoding from function execution, enabling overlap between model decoding and function execution as well as inter-function parallelism when dependencies permit. AsyncFC layers over existing models and unmodified function implementations, requiring no fine-tuning or changes to the standard synchronous function-calling protocol. Across standard function-calling benchmarks and adapted software engineering benchmarks, AsyncFC significantly reduces end-to-end task completion time while preserving task accuracy. Furthermore, these results reveal that LLMs possess a native capability to reason over symbolic futures that represent unresolved execution results, enabling an asynchronous paradigm for model-tool interaction.
Stranger Danger! Identifying and Avoiding Unpredictable Pedestrians in RL-based Social Robot Navigation
Jul 08, 2024
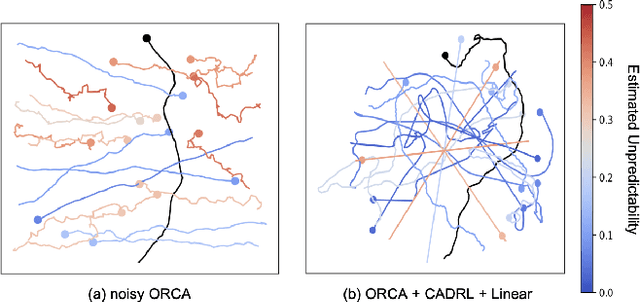


Reinforcement learning (RL) methods for social robot navigation show great success navigating robots through large crowds of people, but the performance of these learning-based methods tends to degrade in particularly challenging or unfamiliar situations due to the models' dependency on representative training data. To ensure human safety and comfort, it is critical that these algorithms handle uncommon cases appropriately, but the low frequency and wide diversity of such situations present a significant challenge for these data-driven methods. To overcome this challenge, we propose modifications to the learning process that encourage these RL policies to maintain additional caution in unfamiliar situations. Specifically, we improve the Socially Attentive Reinforcement Learning (SARL) policy by (1) modifying the training process to systematically introduce deviations into a pedestrian model, (2) updating the value network to estimate and utilize pedestrian-unpredictability features, and (3) implementing a reward function to learn an effective response to pedestrian unpredictability. Compared to the original SARL policy, our modified policy maintains similar navigation times and path lengths, while reducing the number of collisions by 82% and reducing the proportion of time spent in the pedestrians' personal space by up to 19 percentage points for the most difficult cases. We also describe how to apply these modifications to other RL policies and demonstrate that some key high-level behaviors of our approach transfer to a physical robot.
POET: Training Neural Networks on Tiny Devices with Integrated Rematerialization and Paging
Jul 15, 2022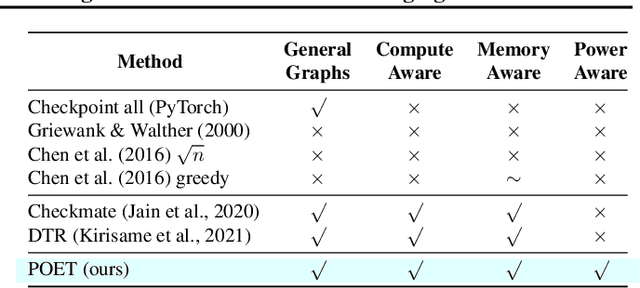
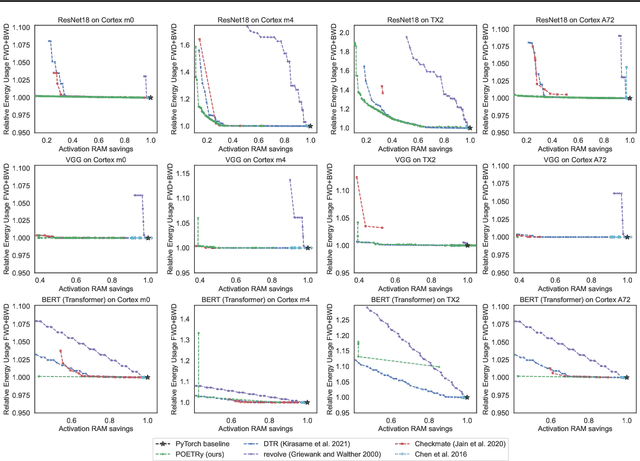
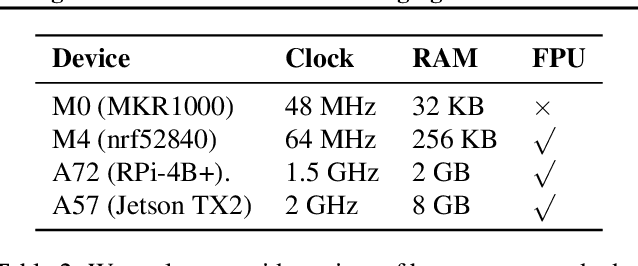
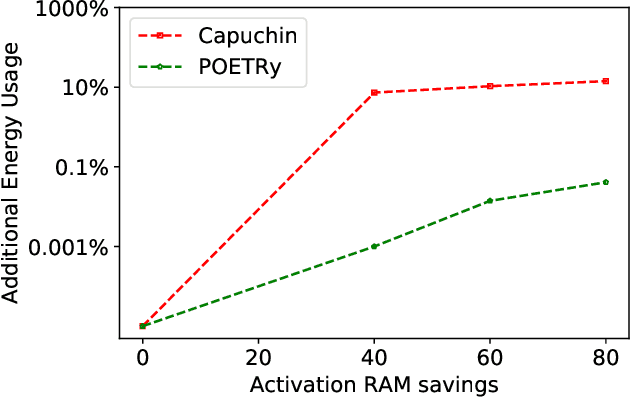
Fine-tuning models on edge devices like mobile phones would enable privacy-preserving personalization over sensitive data. However, edge training has historically been limited to relatively small models with simple architectures because training is both memory and energy intensive. We present POET, an algorithm to enable training large neural networks on memory-scarce battery-operated edge devices. POET jointly optimizes the integrated search search spaces of rematerialization and paging, two algorithms to reduce the memory consumption of backpropagation. Given a memory budget and a run-time constraint, we formulate a mixed-integer linear program (MILP) for energy-optimal training. Our approach enables training significantly larger models on embedded devices while reducing energy consumption while not modifying mathematical correctness of backpropagation. We demonstrate that it is possible to fine-tune both ResNet-18 and BERT within the memory constraints of a Cortex-M class embedded device while outperforming current edge training methods in energy efficiency. POET is an open-source project available at https://github.com/ShishirPatil/poet
New Directions: Wireless Robotic Materials
Aug 15, 2017

We describe opportunities and challenges with wireless robotic materials. Robotic materials are multi-functional composites that tightly integrate sensing, actuation, computation and communication to create smart composites that can sense their environment and change their physical properties in an arbitrary programmable manner. Computation and communication in such materials are based on miniature, possibly wireless, devices that are scattered in the material and interface with sensors and actuators inside the material. Whereas routing and processing of information within the material build upon results from the field of sensor networks, robotic materials are pushing the limits of sensor networks in both size (down to the order of microns) and numbers of devices (up to the order of millions). In order to solve the algorithmic and systems challenges of such an approach, which will involve not only computer scientists, but also roboticists, chemists and material scientists, the community requires a common platform - much like the "Mote" that bootstrapped the widespread adoption of the field of sensor networks - that is small, provides ample of computation, is equipped with basic networking functionalities, and preferably can be powered wirelessly.