 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Generation of Spatial Relations in Text and Image Generative Models
Nov 12, 2024



Understanding spatial relations is a crucial cognitive ability for both humans and AI. While current research has predominantly focused on the benchmarking of text-to-image (T2I) models, we propose a more comprehensive evaluation that includes \textit{both} T2I and Large Language Models (LLMs). As spatial relations are naturally understood in a visuo-spatial manner, we develop an approach to convert LLM outputs into an image, thereby allowing us to evaluate both T2I models and LLMs \textit{visually}. We examined the spatial relation understanding of 8 prominent generative models (3 T2I models and 5 LLMs) on a set of 10 common prepositions, as well as assess the feasibility of automatic evaluation methods. Surprisingly, we found that T2I models only achieve subpar performance despite their impressive general image-generation abilities. Even more surprisingly, our results show that LLMs are significantly more accurate than T2I models in generating spatial relations, despite being primarily trained on textual data. We examined reasons for model failures and highlight gaps that can be filled to enable more spatially faithful generations.
Stranger Danger! Identifying and Avoiding Unpredictable Pedestrians in RL-based Social Robot Navigation
Jul 08, 2024
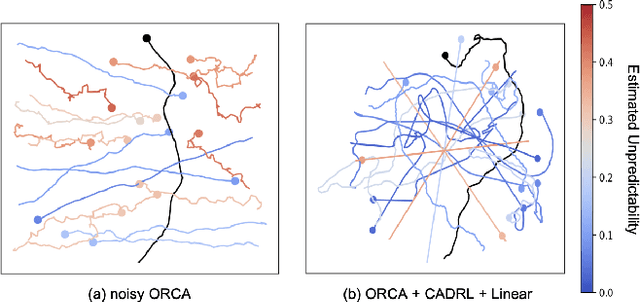


Reinforcement learning (RL) methods for social robot navigation show great success navigating robots through large crowds of people, but the performance of these learning-based methods tends to degrade in particularly challenging or unfamiliar situations due to the models' dependency on representative training data. To ensure human safety and comfort, it is critical that these algorithms handle uncommon cases appropriately, but the low frequency and wide diversity of such situations present a significant challenge for these data-driven methods. To overcome this challenge, we propose modifications to the learning process that encourage these RL policies to maintain additional caution in unfamiliar situations. Specifically, we improve the Socially Attentive Reinforcement Learning (SARL) policy by (1) modifying the training process to systematically introduce deviations into a pedestrian model, (2) updating the value network to estimate and utilize pedestrian-unpredictability features, and (3) implementing a reward function to learn an effective response to pedestrian unpredictability. Compared to the original SARL policy, our modified policy maintains similar navigation times and path lengths, while reducing the number of collisions by 82% and reducing the proportion of time spent in the pedestrians' personal space by up to 19 percentage points for the most difficult cases. We also describe how to apply these modifications to other RL policies and demonstrate that some key high-level behaviors of our approach transfer to a physical robot.
Context-Adaptive Deep Neural Networks via Bridge-Mode Connectivity
Nov 28, 2022
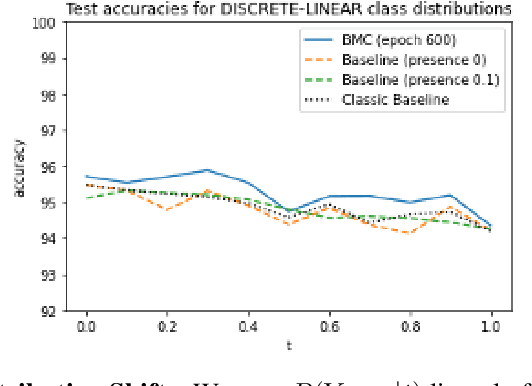
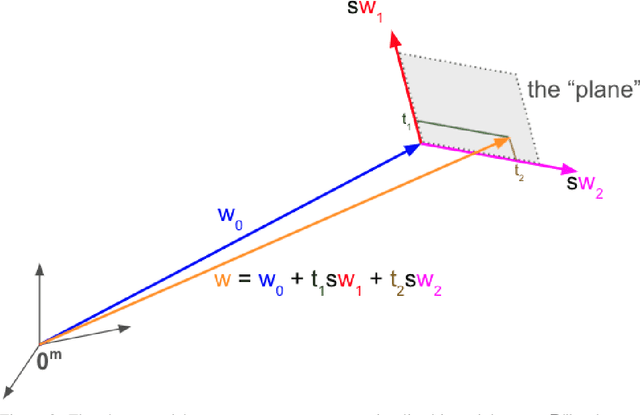

The deployment of machine learning models in safety-critical applications comes with the expectation that such models will perform well over a range of contexts (e.g., a vision model for classifying street signs should work in rural, city, and highway settings under varying lighting/weather conditions). However, these one-size-fits-all models are typically optimized for average case performance, encouraging them to achieve high performance in nominal conditions but exposing them to unexpected behavior in challenging or rare contexts. To address this concern, we develop a new method for training context-dependent models. We extend Bridge-Mode Connectivity (BMC) (Garipov et al., 2018) to train an infinite ensemble of models over a continuous measure of context such that we can sample model parameters specifically tuned to the corresponding evaluation context. We explore the definition of context in image classification tasks through multiple lenses including changes in the risk profile, long-tail image statistics/appearance, and context-dependent distribution shift. We develop novel extensions of the BMC optimization for each of these cases and our experiments demonstrate that model performance can be successfully tuned to context in each scenario.