 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoors in DRL: Four Environments Focusing on In-distribution Triggers
May 22, 2025



Backdoor attacks, or trojans, pose a security risk by concealing undesirable behavior in deep neural network models. Open-source neural networks are downloaded from the internet daily, possibly containing backdoors, and third-party model developers are common. To advance research on backdoor attack mitigation, we develop several trojans for deep reinforcement learning (DRL) agents. We focus on in-distribution triggers, which occur within the agent's natural data distribution, since they pose a more significant security threat than out-of-distribution triggers due to their ease of activation by the attacker during model deployment. We implement backdoor attacks in four reinforcement learning (RL) environments: LavaWorld, Randomized LavaWorld, Colorful Memory, and Modified Safety Gymnasium. We train various models, both clean and backdoored, to characterize these attacks. We find that in-distribution triggers can require additional effort to implement and be more challenging for models to learn, but are nevertheless viable threats in DRL even using basic data poisoning attacks.
Investigating the Treacherous Turn in Deep Reinforcement Learning
Apr 11, 2025


The Treacherous Turn refers to the scenario where an artificial intelligence (AI) agent subtly, and perhaps covertly, learns to perform a behavior that benefits itself but is deemed undesirable and potentially harmful to a human supervisor. During training, the agent learns to behave as expected by the human supervisor, but when deployed to perform its task, it performs an alternate behavior without the supervisor there to prevent it. Initial experiments applying DRL to an implementation of the A Link to the Past example do not produce the treacherous turn effect naturally, despite various modifications to the environment intended to produce it. However, in this work, we find the treacherous behavior to be reproducible in a DRL agent when using other trojan injection strategies. This approach deviates from the prototypical treacherous turn behavior since the behavior is explicitly trained into the agent, rather than occurring as an emergent consequence of environmental complexity or poor objective specification. Nonetheless, these experiments provide new insights into the challenges of producing agents capable of true treacherous turn behavior.
Kullback-Leibler Divergence-Guided Copula Statistics-Based Blind Source Separation of Dependent Signals
Sep 14, 2023In this paper, we propose a blind source separation of a linear mixture of dependent sources based on copula statistics that measure the non-linear dependence between source component signals structured as copula density functions. The source signals are assumed to be stationary. The method minimizes the Kullback-Leibler divergence between the copula density functions of the estimated sources and of the dependency structure. The proposed method is applied to data obtained from the time-domain analysis of the classical 11-Bus 4-Machine system. Extensive simulation results demonstrate that the proposed method based on copula statistics converges faster and outperforms the state-of-the-art blind source separation method for dependent sources in terms of interference-to-signal ratio.
Context-Adaptive Deep Neural Networks via Bridge-Mode Connectivity
Nov 28, 2022
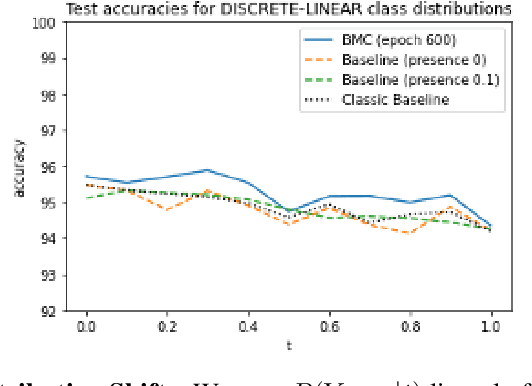
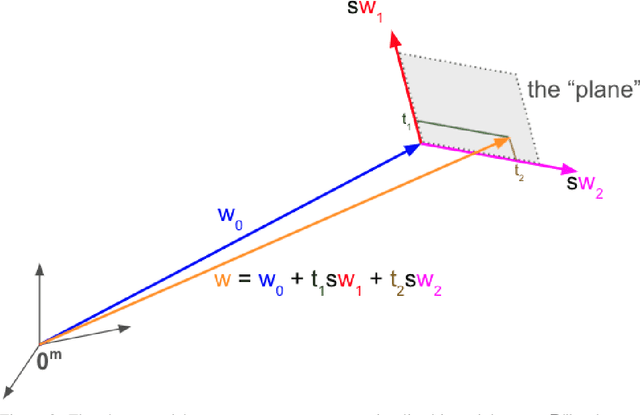

The deployment of machine learning models in safety-critical applications comes with the expectation that such models will perform well over a range of contexts (e.g., a vision model for classifying street signs should work in rural, city, and highway settings under varying lighting/weather conditions). However, these one-size-fits-all models are typically optimized for average case performance, encouraging them to achieve high performance in nominal conditions but exposing them to unexpected behavior in challenging or rare contexts. To address this concern, we develop a new method for training context-dependent models. We extend Bridge-Mode Connectivity (BMC) (Garipov et al., 2018) to train an infinite ensemble of models over a continuous measure of context such that we can sample model parameters specifically tuned to the corresponding evaluation context. We explore the definition of context in image classification tasks through multiple lenses including changes in the risk profile, long-tail image statistics/appearance, and context-dependent distribution shift. We develop novel extensions of the BMC optimization for each of these cases and our experiments demonstrate that model performance can be successfully tuned to context in each scenario.
Machine Learning aided Crop Yield Optimization
Nov 01, 2021

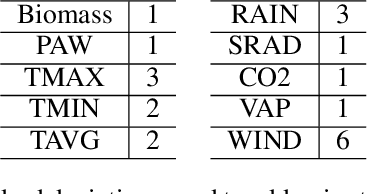
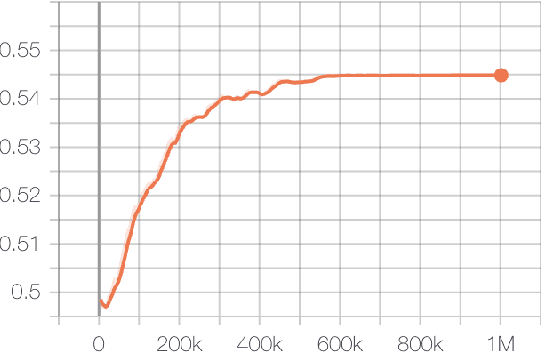
We present a crop simulation environment with an OpenAI Gym interface, and apply modern deep reinforcement learning (DRL) algorithms to optimize yield. We empirically show that DRL algorithms may be useful in discovering new policies and approaches to help optimize crop yield, while simultaneously minimizing constraining factors such as water and fertilizer usage. We propose that this hybrid plant modeling and data-driven approach for discovering new strategies to optimize crop yield may help address upcoming global food demands due to population expansion and climate change.
SanitAIs: Unsupervised Data Augmentation to Sanitize Trojaned Neural Networks
Sep 14, 2021
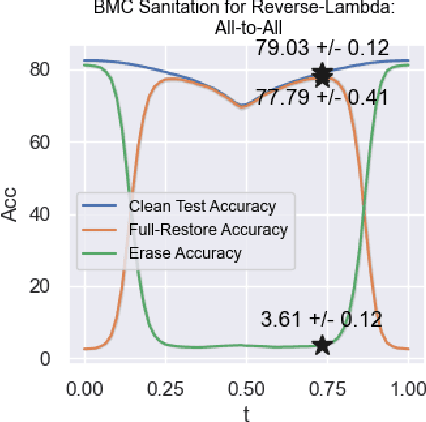

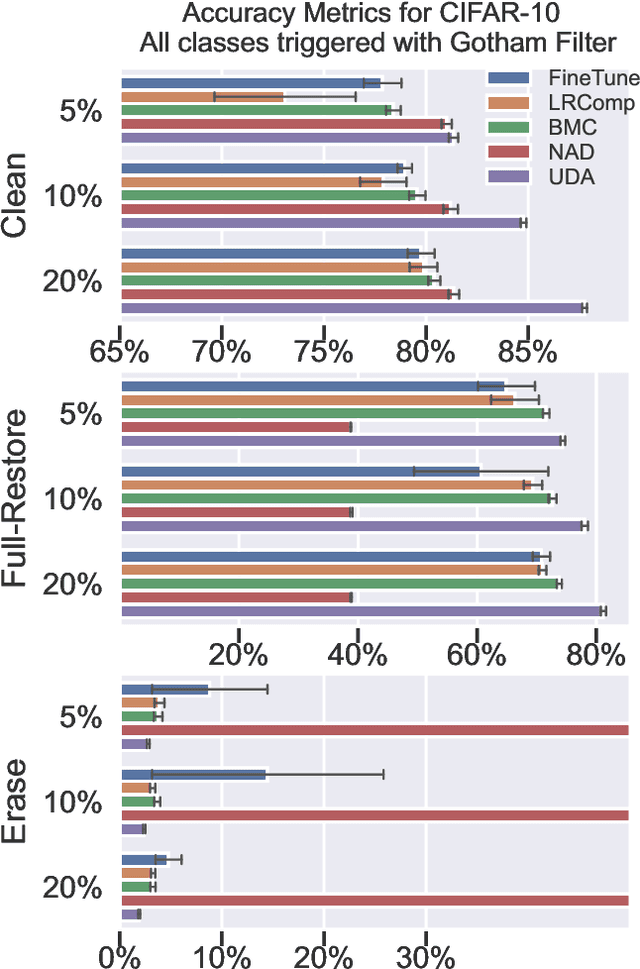
The application of self-supervised methods has resulted in broad improvements to neural network performance by leveraging large, untapped collections of unlabeled data to learn generalized underlying structure. In this work, we harness unsupervised data augmentation (UDA) to mitigate backdoor or Trojan attacks on deep neural networks. We show that UDA is more effective at removing the effects of a trigger than current state-of-the-art methods for both feature space and point triggers. These results demonstrate that UDA is both an effective and practical approach to mitigating the effects of backdoors on neural networks.
Poisoning Deep Reinforcement Learning Agents with In-Distribution Triggers
Jun 14, 2021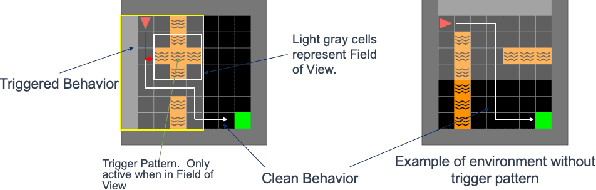
In this paper, we propose a new data poisoning attack and apply it to deep reinforcement learning agents. Our attack centers on what we call in-distribution triggers, which are triggers native to the data distributions the model will be trained on and deployed in. We outline a simple procedure for embedding these, and other, triggers in deep reinforcement learning agents following a multi-task learning paradigm, and demonstrate in three common reinforcement learning environments. We believe that this work has important implications for the security of deep learning models.
Speaker Diarization using Two-pass Leave-One-Out Gaussian PLDA Clustering of DNN Embeddings
Apr 07, 2021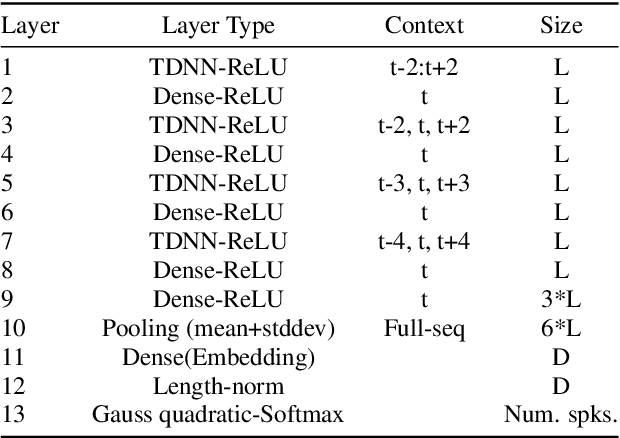
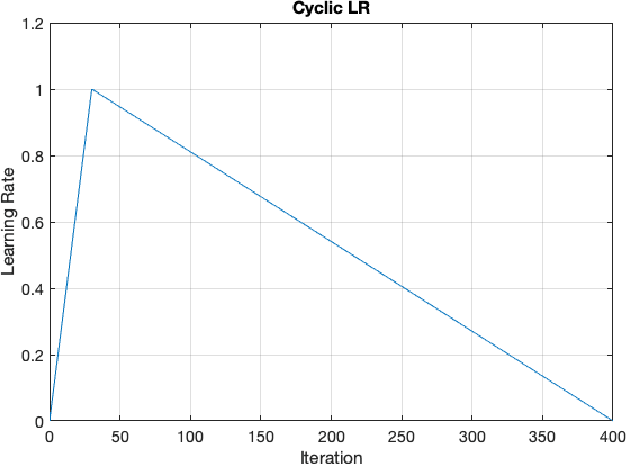

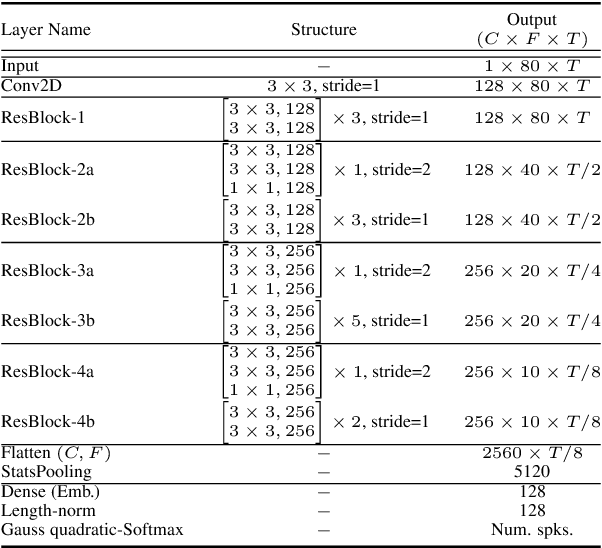
Many modern systems for speaker diarization, such as the recently-developed VBx approach, rely on clustering of DNN speaker embeddings followed by resegmentation. Two problems with this approach are that the DNN is not directly optimized for this task, and the parameters need significant retuning for different applications. We have recently presented progress in this direction with a Leave-One-Out Gaussian PLDA (LGP) clustering algorithm and an approach to training the DNN such that embeddings directly optimize performance of this scoring method. This paper presents a new two-pass version of this system, where the second pass uses finer time resolution to significantly improve overall performance. For the Callhome corpus, we achieve the first published error rate below 4\% without any task-dependent parameter tuning. We also show significant progress towards a robust single solution for multiple diarization tasks.
The TrojAI Software Framework: An OpenSource tool for Embedding Trojans into Deep Learning Models
Mar 13, 2020


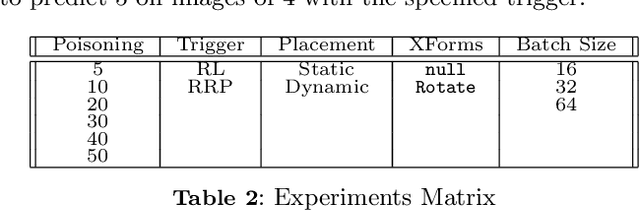
In this paper, we introduce the TrojAI software framework, an open source set of Python tools capable of generating triggered (poisoned) datasets and associated deep learning (DL) models with trojans at scale. We utilize the developed framework to generate a large set of trojaned MNIST classifiers, as well as demonstrate the capability to produce a trojaned reinforcement-learning model using vector observations. Results on MNIST show that the nature of the trigger, training batch size, and dataset poisoning percentage all affect successful embedding of trojans. We test Neural Cleanse against the trojaned MNIST models and successfully detect anomalies in the trained models approximately $18\%$ of the time. Our experiments and workflow indicate that the TrojAI software framework will enable researchers to easily understand the effects of various configurations of the dataset and training hyperparameters on the generated trojaned deep learning model, and can be used to rapidly and comprehensively test new trojan detection methods.
Copula Index for Detecting Dependence and Monotonicity between Stochastic Signals
Oct 06, 2018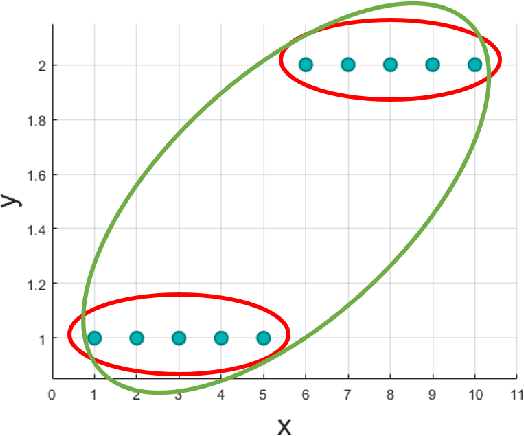
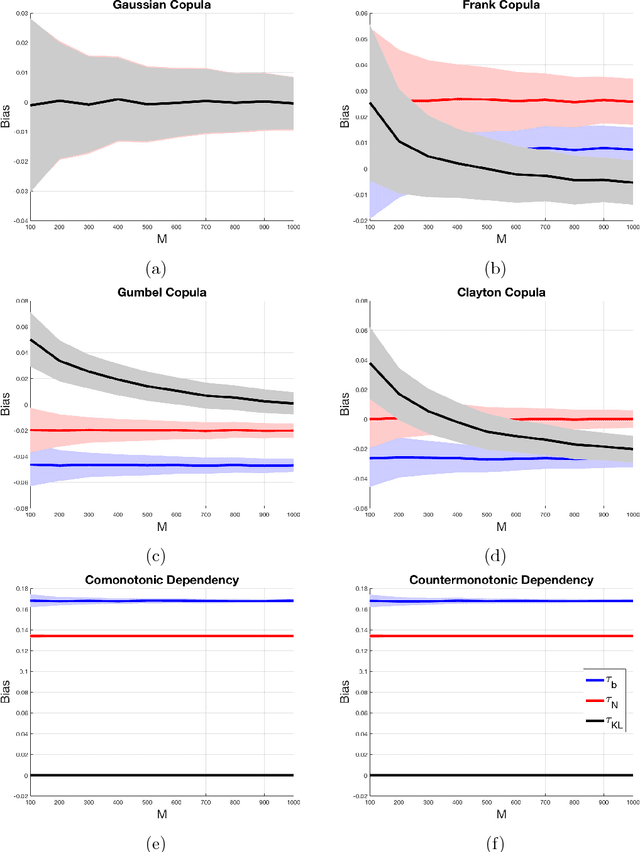
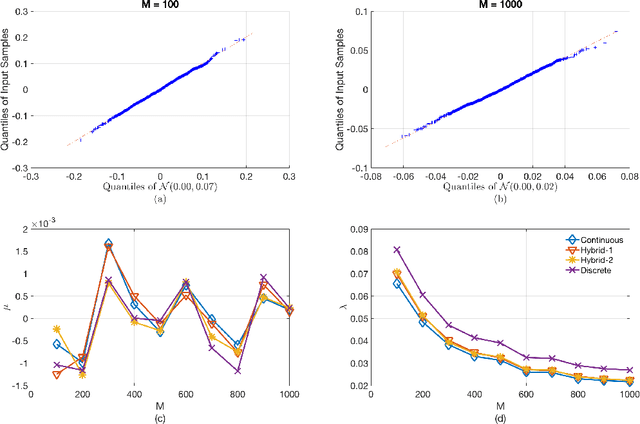
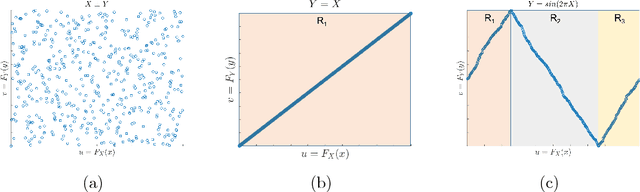
This paper introduces a nonparametric copula-based index for detecting the strength and monotonicity structure of linear and nonlinear statistical dependence between pairs of random variables or stochastic signals. Our index, termed Copula Index for Detecting Dependence and Monotonicity (CIM), satisfies several desirable properties of measures of association, including Renyi's properties, the data processing inequality (DPI), and consequently self-equitability. Synthetic data simulations reveal that the statistical power of CIM compares favorably to other state-of-the-art measures of association that are proven to satisfy the DPI. Simulation results with real-world data reveal the CIM's unique ability to detect the monotonicity structure among stochastic signals to find interesting dependencies in large datasets. Additionally, simulations show that the CIM shows favorable performance to estimators of mutual information when discovering Markov network structure.