 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Diarization using Two-pass Leave-One-Out Gaussian PLDA Clustering of DNN Embeddings
Apr 07, 2021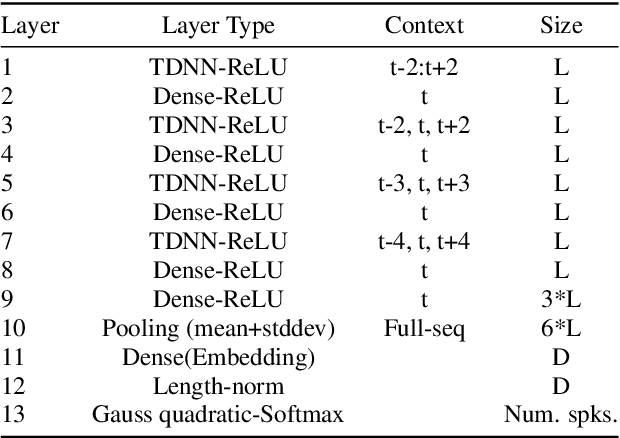

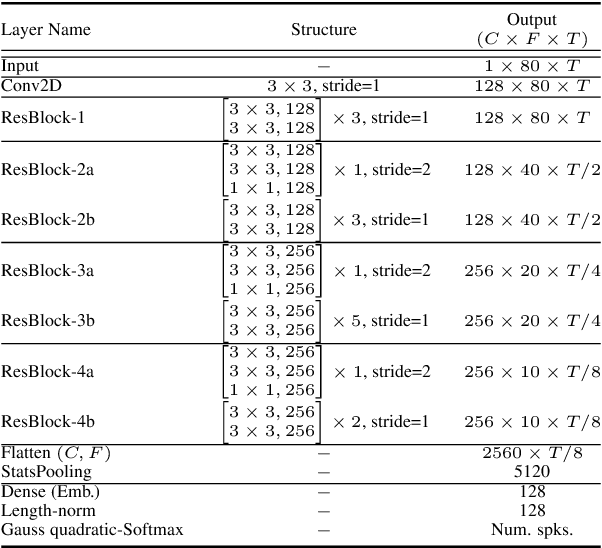
Many modern systems for speaker diarization, such as the recently-developed VBx approach, rely on clustering of DNN speaker embeddings followed by resegmentation. Two problems with this approach are that the DNN is not directly optimized for this task, and the parameters need significant retuning for different applications. We have recently presented progress in this direction with a Leave-One-Out Gaussian PLDA (LGP) clustering algorithm and an approach to training the DNN such that embeddings directly optimize performance of this scoring method. This paper presents a new two-pass version of this system, where the second pass uses finer time resolution to significantly improve overall performance. For the Callhome corpus, we achieve the first published error rate below 4\% without any task-dependent parameter tuning. We also show significant progress towards a robust single solution for multiple diarization tasks.
Variable frame rate-based data augmentation to handle speaking-style variability for automatic speaker verification
Aug 08, 2020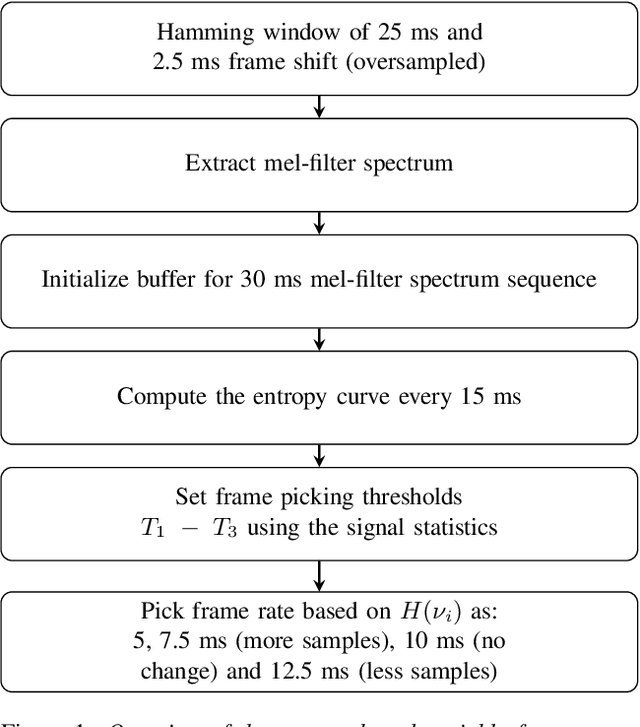
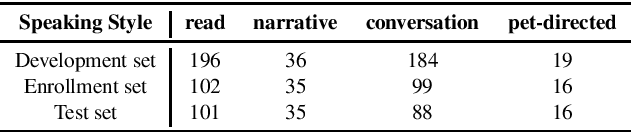
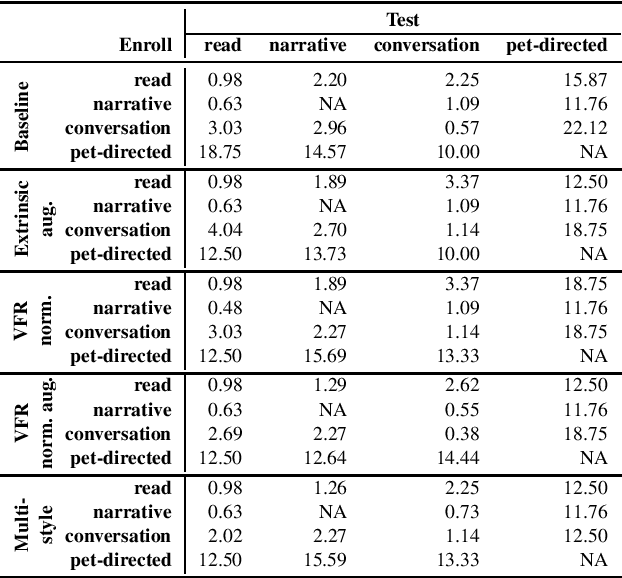
The effects of speaking-style variability on automatic speaker verification were investigated using the UCLA Speaker Variability database which comprises multiple speaking styles per speaker. An x-vector/PLDA (probabilistic linear discriminant analysis) system was trained with the SRE and Switchboard databases with standard augmentation techniques and evaluated with utterances from the UCLA database. The equal error rate (EER) was low when enrollment and test utterances were of the same style (e.g., 0.98% and 0.57% for read and conversational speech, respectively), but it increased substantially when styles were mismatched between enrollment and test utterances. For instance, when enrolled with conversation utterances, the EER increased to 3.03%, 2.96% and 22.12% when tested on read, narrative, and pet-directed speech, respectively. To reduce the effect of style mismatch, we propose an entropy-based variable frame rate technique to artificially generate style-normalized representations for PLDA adaptation. The proposed system significantly improved performance. In the aforementioned conditions, the EERs improved to 2.69% (conversation -- read), 2.27% (conversation -- narrative), and 18.75% (pet-directed -- read). Overall, the proposed technique performed comparably to multi-style PLDA adaptation without the need for training data in different speaking styles per speaker.