 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Intra-Speaker Variability in Diarization with Style-Controllable Speech Augmentation
Sep 18, 2025Speaker diarization systems often struggle with high intrinsic intra-speaker variability, such as shifts in emotion, health, or content. This can cause segments from the same speaker to be misclassified as different individuals, for example, when one raises their voice or speaks faster during conversation. To address this, we propose a style-controllable speech generation model that augments speech across diverse styles while preserving the target speaker's identity. The proposed system starts with diarized segments from a conventional diarizer. For each diarized segment, it generates augmented speech samples enriched with phonetic and stylistic diversity. And then, speaker embeddings from both the original and generated audio are blended to enhance the system's robustness in grouping segments with high intrinsic intra-speaker variability. We validate our approach on a simulated emotional speech dataset and the truncated AMI dataset, demonstrating significant improvements, with error rate reductions of 49% and 35% on each dataset, respectively.
Development of Image Collection Method Using YOLO and Siamese Network
Oct 16, 2024
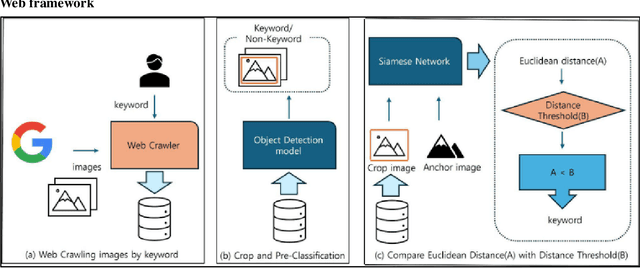
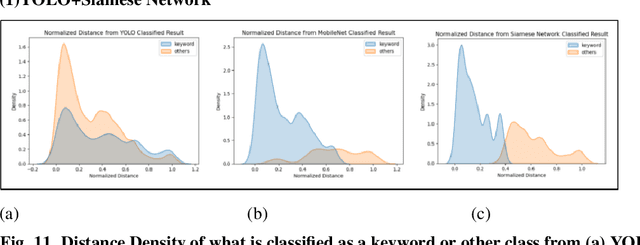
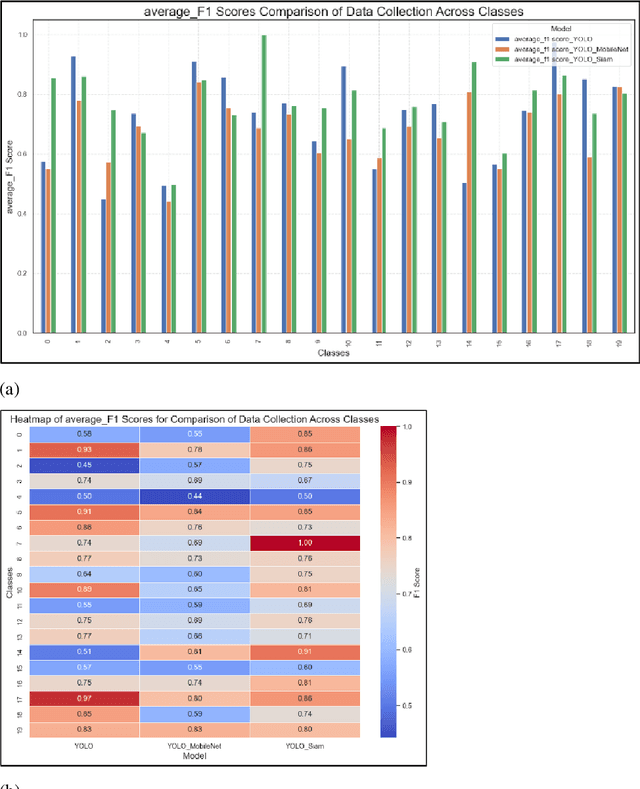
As we enter the era of big data, collecting high-quality data is very important. However, collecting data by humans is not only very time-consuming but also expensive. Therefore, many scientists have devised various methods to collect data using computers. Among them, there is a method called web crawling, but the authors found that the crawling method has a problem in that unintended data is collected along with the user. The authors found that this can be filtered using the object recognition model YOLOv10. However, there are cases where data that is not properly filtered remains. Here, image reclassification was performed by additionally utilizing the distance output from the Siamese network, and higher performance was recorded than other classification models. (average \_f1 score YOLO+MobileNet 0.678->YOLO+SiameseNet 0.772)) The user can specify a distance threshold to adjust the balance between data deficiency and noise-robustness. The authors also found that the Siamese network can achieve higher performance with fewer resources because the cropped images are used for object recognition when processing images in the Siamese network. (Class 20 mean-based f1 score, non-crop+Siamese(MobileNetV3-Small) 80.94 -> crop preprocessing+Siamese(MobileNetV3-Small) 82.31) In this way, the image retrieval system that utilizes two consecutive models to reduce errors can save users' time and effort, and build better quality data faster and with fewer resources than before.
Variable frame rate-based data augmentation to handle speaking-style variability for automatic speaker verification
Aug 08, 2020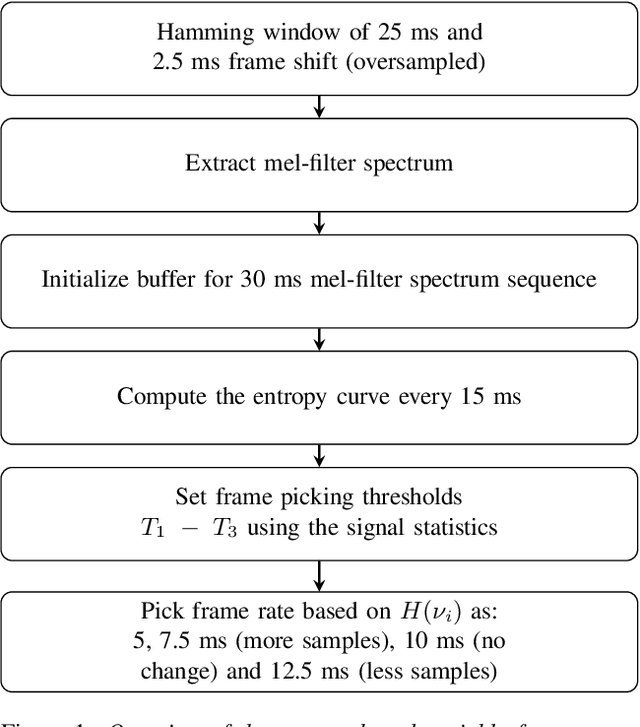
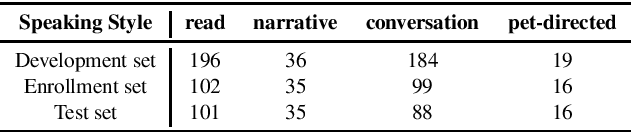
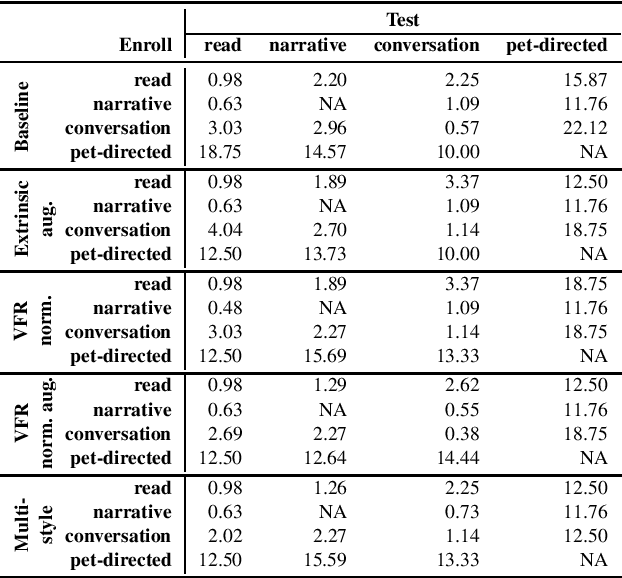
The effects of speaking-style variability on automatic speaker verification were investigated using the UCLA Speaker Variability database which comprises multiple speaking styles per speaker. An x-vector/PLDA (probabilistic linear discriminant analysis) system was trained with the SRE and Switchboard databases with standard augmentation techniques and evaluated with utterances from the UCLA database. The equal error rate (EER) was low when enrollment and test utterances were of the same style (e.g., 0.98% and 0.57% for read and conversational speech, respectively), but it increased substantially when styles were mismatched between enrollment and test utterances. For instance, when enrolled with conversation utterances, the EER increased to 3.03%, 2.96% and 22.12% when tested on read, narrative, and pet-directed speech, respectively. To reduce the effect of style mismatch, we propose an entropy-based variable frame rate technique to artificially generate style-normalized representations for PLDA adaptation. The proposed system significantly improved performance. In the aforementioned conditions, the EERs improved to 2.69% (conversation -- read), 2.27% (conversation -- narrative), and 18.75% (pet-directed -- read). Overall, the proposed technique performed comparably to multi-style PLDA adaptation without the need for training data in different speaking styles per speaker.