 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of Image Collection Method Using YOLO and Siamese Network
Oct 16, 2024
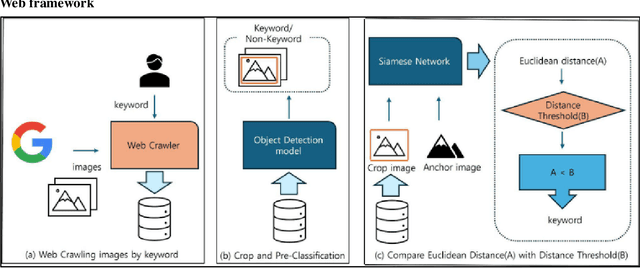
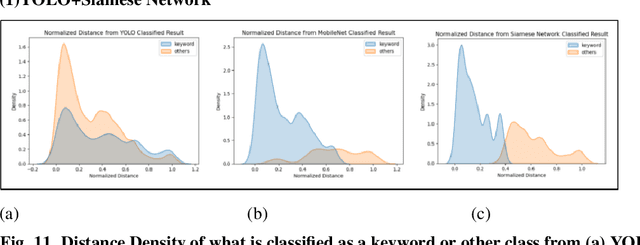
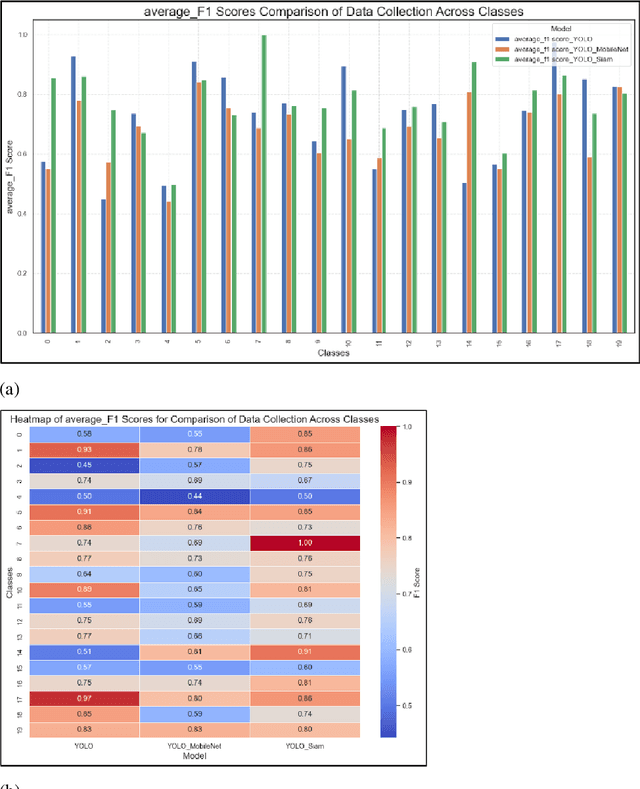
As we enter the era of big data, collecting high-quality data is very important. However, collecting data by humans is not only very time-consuming but also expensive. Therefore, many scientists have devised various methods to collect data using computers. Among them, there is a method called web crawling, but the authors found that the crawling method has a problem in that unintended data is collected along with the user. The authors found that this can be filtered using the object recognition model YOLOv10. However, there are cases where data that is not properly filtered remains. Here, image reclassification was performed by additionally utilizing the distance output from the Siamese network, and higher performance was recorded than other classification models. (average \_f1 score YOLO+MobileNet 0.678->YOLO+SiameseNet 0.772)) The user can specify a distance threshold to adjust the balance between data deficiency and noise-robustness. The authors also found that the Siamese network can achieve higher performance with fewer resources because the cropped images are used for object recognition when processing images in the Siamese network. (Class 20 mean-based f1 score, non-crop+Siamese(MobileNetV3-Small) 80.94 -> crop preprocessing+Siamese(MobileNetV3-Small) 82.31) In this way, the image retrieval system that utilizes two consecutive models to reduce errors can save users' time and effort, and build better quality data faster and with fewer resources than before.