 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-uniform Speaker Disentanglement For Depression Detection From Raw Speech Signals
Jun 06, 2023While speech-based depression detection methods that use speaker-identity features, such as speaker embeddings, are popular, they often compromise patient privacy. To address this issue, we propose a speaker disentanglement method that utilizes a non-uniform mechanism of adversarial SID loss maximization. This is achieved by varying the adversarial weight between different layers of a model during training. We find that a greater adversarial weight for the initial layers leads to performance improvement. Our approach using the ECAPA-TDNN model achieves an F1-score of 0.7349 (a 3.7% improvement over audio-only SOTA) on the DAIC-WoZ dataset, while simultaneously reducing the speaker-identification accuracy by 50%. Our findings suggest that identifying depression through speech signals can be accomplished without placing undue reliance on a speaker's identity, paving the way for privacy-preserving approaches of depression detection.
A Step Towards Preserving Speakers' Identity While Detecting Depression Via Speaker Disentanglement
Jun 29, 2022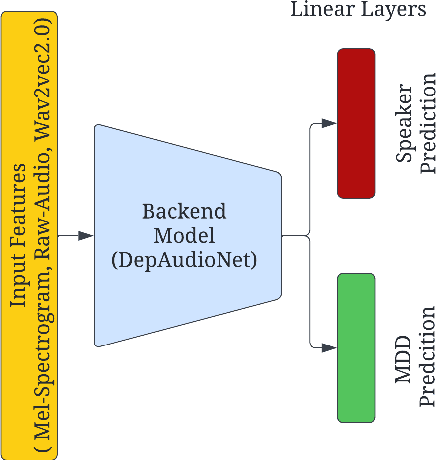
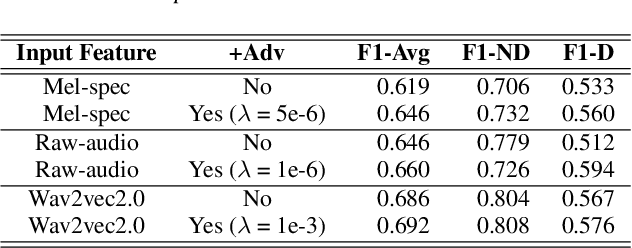


Preserving a patient's identity is a challenge for automatic, speech-based diagnosis of mental health disorders. In this paper, we address this issue by proposing adversarial disentanglement of depression characteristics and speaker identity. The model used for depression classification is trained in a speaker-identity-invariant manner by minimizing depression prediction loss and maximizing speaker prediction loss during training. The effectiveness of the proposed method is demonstrated on two datasets - DAIC-WOZ (English) and CONVERGE (Mandarin), with three feature sets (Mel-spectrograms, raw-audio signals, and the last-hidden-state of Wav2vec2.0), using a modified DepAudioNet model. With adversarial training, depression classification improves for every feature when compared to the baseline. Wav2vec2.0 features with adversarial learning resulted in the best performance (F1-score of 69.2% for DAIC-WOZ and 91.5% for CONVERGE). Analysis of the class-separability measure (J-ratio) of the hidden states of the DepAudioNet model shows that when adversarial learning is applied, the backend model loses some speaker-discriminability while it improves depression-discriminability. These results indicate that there are some components of speaker identity that may not be useful for depression detection and minimizing their effects provides a more accurate diagnosis of the underlying disorder and can safeguard a speaker's identity.
Unsupervised Instance Discriminative Learning for Depression Detection from Speech Signals
Jun 27, 2022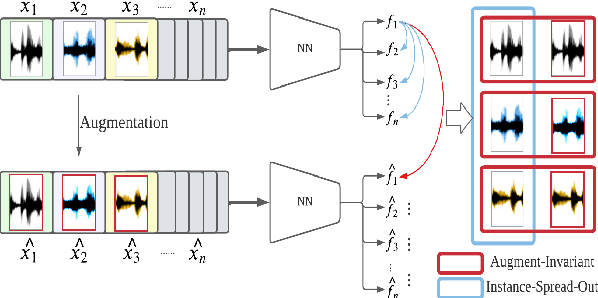
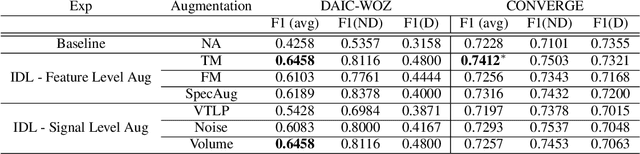
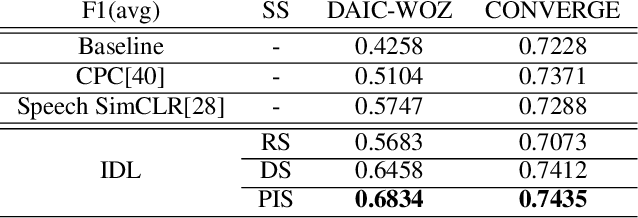
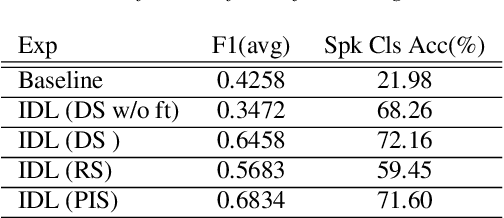
Major Depressive Disorder (MDD) is a severe illness that affects millions of people, and it is critical to diagnose this disorder as early as possible. Detecting depression from voice signals can be of great help to physicians and can be done without any invasive procedure. Since relevant labelled data are scarce, we propose a modified Instance Discriminative Learning (IDL) method, an unsupervised pre-training technique, to extract augment-invariant and instance-spread-out embeddings. In terms of learning augment-invariant embeddings, various data augmentation methods for speech are investigated, and time-masking yields the best performance. To learn instance-spread-out embeddings, we explore methods for sampling instances for a training batch (distinct speaker-based and random sampling). It is found that the distinct speaker-based sampling provides better performance than the random one, and we hypothesize that this result is because relevant speaker information is preserved in the embedding. Additionally, we propose a novel sampling strategy, Pseudo Instance-based Sampling (PIS), based on clustering algorithms, to enhance spread-out characteristics of the embeddings. Experiments are conducted with DepAudioNet on DAIC-WOZ (English) and CONVERGE (Mandarin) datasets, and statistically significant improvements, with p-value 0.0015 and 0.05, respectively, are observed using PIS in the detection of MDD relative to the baseline without pre-training.
Automatic Dialect Density Estimation for African American English
Apr 03, 2022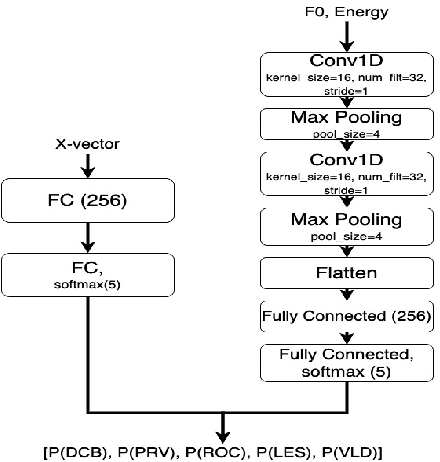
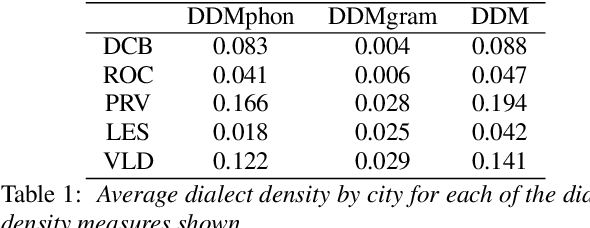
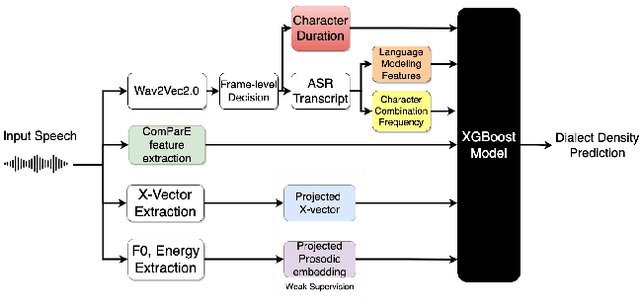
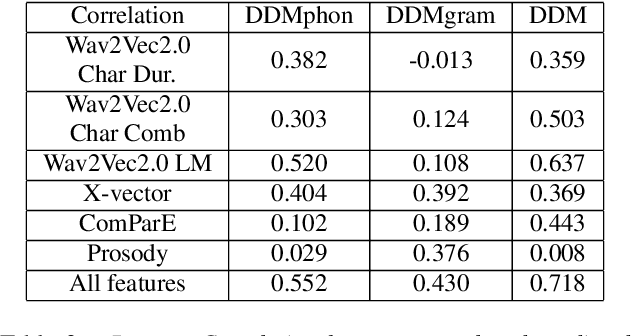
In this paper, we explore automatic prediction of dialect density of the African American English (AAE) dialect, where dialect density is defined as the percentage of words in an utterance that contain characteristics of the non-standard dialect. We investigate several acoustic and language modeling features, including the commonly used X-vector representation and ComParE feature set, in addition to information extracted from ASR transcripts of the audio files and prosodic information. To address issues of limited labeled data, we use a weakly supervised model to project prosodic and X-vector features into low-dimensional task-relevant representations. An XGBoost model is then used to predict the speaker's dialect density from these features and show which are most significant during inference. We evaluate the utility of these features both alone and in combination for the given task. This work, which does not rely on hand-labeled transcripts, is performed on audio segments from the CORAAL database. We show a significant correlation between our predicted and ground truth dialect density measures for AAE speech in this database and propose this work as a tool for explaining and mitigating bias in speech technology.
* 5 pages, 2 figures
FrAUG: A Frame Rate Based Data Augmentation Method for Depression Detection from Speech Signals
Feb 11, 2022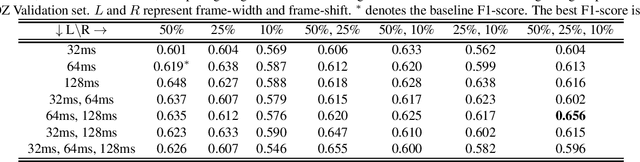
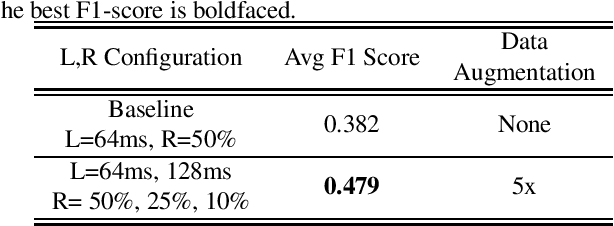
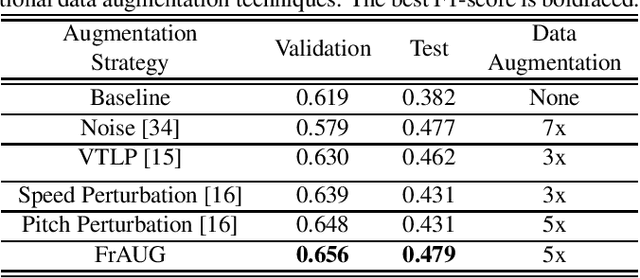
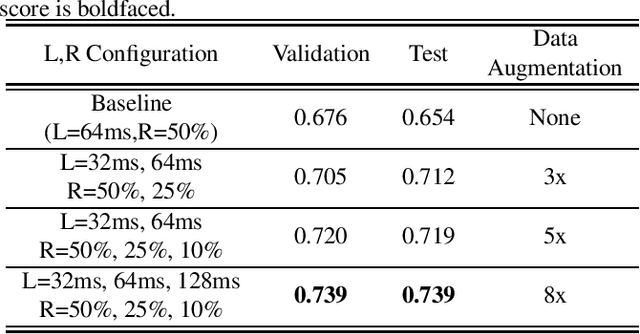
In this paper, a data augmentation method is proposed for depression detection from speech signals. Samples for data augmentation were created by changing the frame-width and the frame-shift parameters during the feature extraction process. Unlike other data augmentation methods (such as VTLP, pitch perturbation, or speed perturbation), the proposed method does not explicitly change acoustic parameters but rather the time-frequency resolution of frame-level features. The proposed method was evaluated using two different datasets, models, and input acoustic features. For the DAIC-WOZ (English) dataset when using the DepAudioNet model and mel-Spectrograms as input, the proposed method resulted in an improvement of 5.97% (validation) and 25.13% (test) when compared to the baseline. The improvements for the CONVERGE (Mandarin) dataset when using the x-vector embeddings with CNN as the backend and MFCCs as input features were 9.32% (validation) and 12.99% (test). Baseline systems do not incorporate any data augmentation. Further, the proposed method outperformed commonly used data-augmentation methods such as noise augmentation, VTLP, Speed, and Pitch Perturbation. All improvements were statistically significant.
Improving accuracy of rare words for RNN-Transducer through unigram shallow fusion
Nov 30, 2020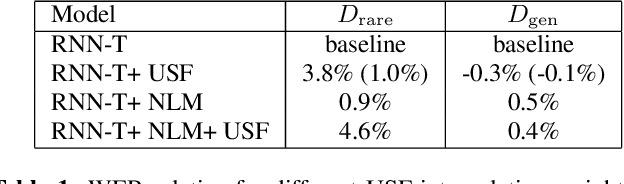

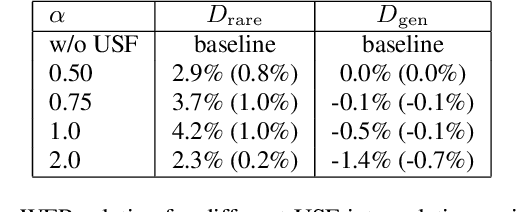
End-to-end automatic speech recognition (ASR) systems, such as recurrent neural network transducer (RNN-T), have become popular, but rare word remains a challenge. In this paper, we propose a simple, yet effective method called unigram shallow fusion (USF) to improve rare words for RNN-T. In USF, we extract rare words from RNN-T training data based on unigram count, and apply a fixed reward when the word is encountered during decoding. We show that this simple method can improve performance on rare words by 3.7% WER relative without degradation on general test set, and the improvement from USF is additive to any additional language model based rescoring. Then, we show that the same USF does not work on conventional hybrid system. Finally, we reason that USF works by fixing errors in probability estimates of words due to Viterbi search used during decoding with subword-based RNN-T.
Variable frame rate-based data augmentation to handle speaking-style variability for automatic speaker verification
Aug 08, 2020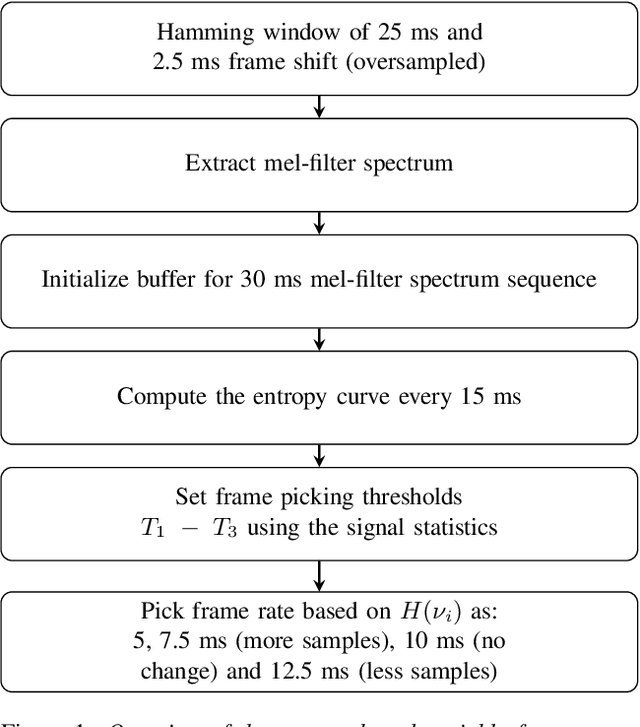
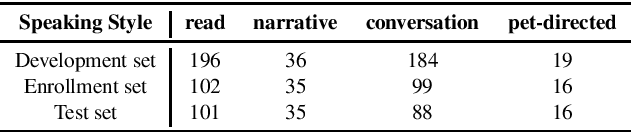
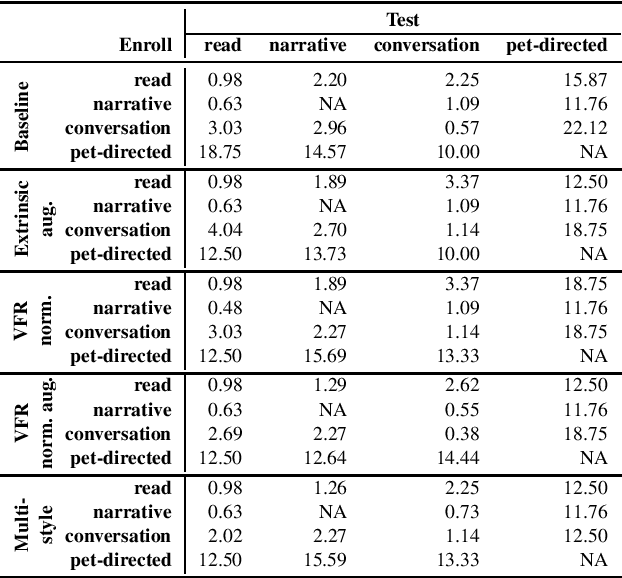
The effects of speaking-style variability on automatic speaker verification were investigated using the UCLA Speaker Variability database which comprises multiple speaking styles per speaker. An x-vector/PLDA (probabilistic linear discriminant analysis) system was trained with the SRE and Switchboard databases with standard augmentation techniques and evaluated with utterances from the UCLA database. The equal error rate (EER) was low when enrollment and test utterances were of the same style (e.g., 0.98% and 0.57% for read and conversational speech, respectively), but it increased substantially when styles were mismatched between enrollment and test utterances. For instance, when enrolled with conversation utterances, the EER increased to 3.03%, 2.96% and 22.12% when tested on read, narrative, and pet-directed speech, respectively. To reduce the effect of style mismatch, we propose an entropy-based variable frame rate technique to artificially generate style-normalized representations for PLDA adaptation. The proposed system significantly improved performance. In the aforementioned conditions, the EERs improved to 2.69% (conversation -- read), 2.27% (conversation -- narrative), and 18.75% (pet-directed -- read). Overall, the proposed technique performed comparably to multi-style PLDA adaptation without the need for training data in different speaking styles per speaker.
Exploring the Use of an Unsupervised Autoregressive Model as a Shared Encoder for Text-Dependent Speaker Verification
Aug 08, 2020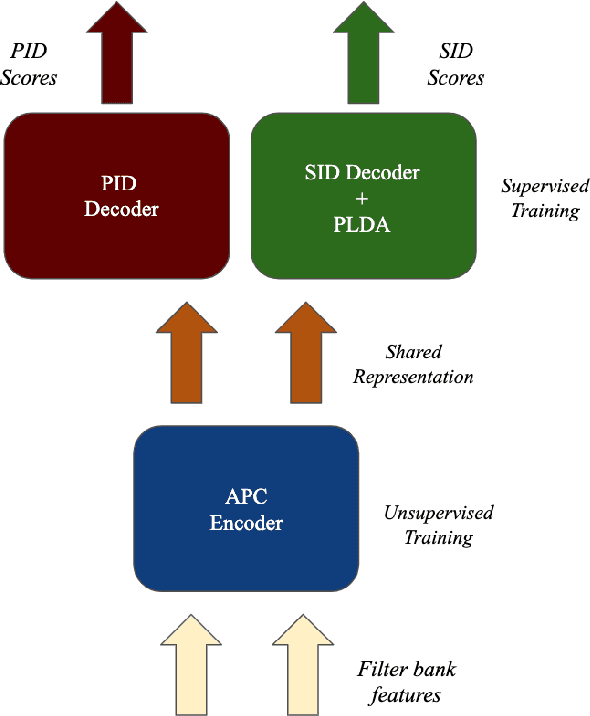
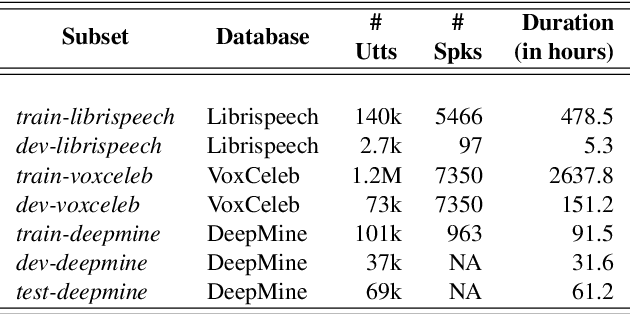
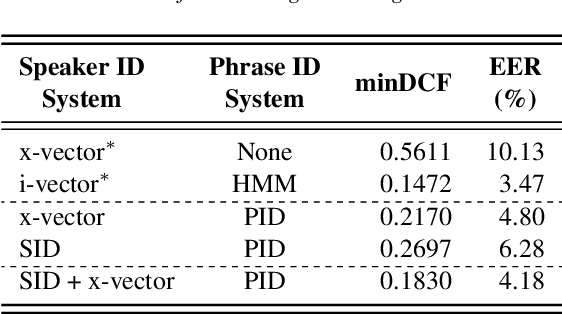
In this paper, we propose a novel way of addressing text-dependent automatic speaker verification (TD-ASV) by using a shared-encoder with task-specific decoders. An autoregressive predictive coding (APC) encoder is pre-trained in an unsupervised manner using both out-of-domain (LibriSpeech, VoxCeleb) and in-domain (DeepMine) unlabeled datasets to learn generic, high-level feature representation that encapsulates speaker and phonetic content. Two task-specific decoders were trained using labeled datasets to classify speakers (SID) and phrases (PID). Speaker embeddings extracted from the SID decoder were scored using a PLDA. SID and PID systems were fused at the score level. There is a 51.9% relative improvement in minDCF for our system compared to the fully supervised x-vector baseline on the cross-lingual DeepMine dataset. However, the i-vector/HMM method outperformed the proposed APC encoder-decoder system. A fusion of the x-vector/PLDA baseline and the SID/PLDA scores prior to PID fusion further improved performance by 15% indicating complementarity of the proposed approach to the x-vector system. We show that the proposed approach can leverage from large, unlabeled, data-rich domains, and learn speech patterns independent of downstream tasks. Such a system can provide competitive performance in domain-mismatched scenarios where test data is from data-scarce domains.