 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforcement Learning-Based Model for Mapping and Goal-Directed Navigation Using Multiscale Place Fields
Jan 07, 2026Autonomous navigation in complex and partially observable environments remains a central challenge in robotics. Several bio-inspired models of mapping and navigation based on place cells in the mammalian hippocampus have been proposed. This paper introduces a new robust model that employs parallel layers of place fields at multiple spatial scales, a replay-based reward mechanism, and dynamic scale fusion. Simulations show that the model improves path efficiency and accelerates learning compared to single-scale baselines, highlighting the value of multiscale spatial representations for adaptive robot navigation.
CREAM: Comparison-Based Reference-Free ELO-Ranked Automatic Evaluation for Meeting Summarization
Sep 17, 2024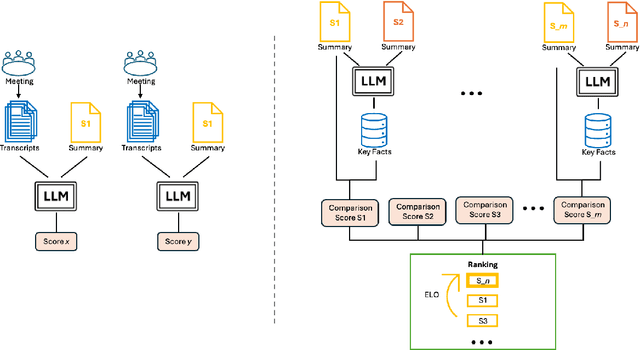


Large Language Models (LLMs) have spurred interest in automatic evaluation methods for summarization, offering a faster, more cost-effective alternative to human evaluation. However, existing methods often fall short when applied to complex tasks like long-context summarizations and dialogue-based meeting summarizations. In this paper, we introduce CREAM (Comparison-Based Reference-Free Elo-Ranked Automatic Evaluation for Meeting Summarization), a novel framework that addresses the unique challenges of evaluating meeting summaries. CREAM leverages a combination of chain-of-thought reasoning and key facts alignment to assess conciseness and completeness of model-generated summaries without requiring reference. By employing an ELO ranking system, our approach provides a robust mechanism for comparing the quality of different models or prompt configurations.
NovAScore: A New Automated Metric for Evaluating Document Level Novelty
Sep 14, 2024



The rapid expansion of online content has intensified the issue of information redundancy, underscoring the need for solutions that can identify genuinely new information. Despite this challenge, the research community has seen a decline in focus on novelty detection, particularly with the rise of large language models (LLMs). Additionally, previous approaches have relied heavily on human annotation, which is time-consuming, costly, and particularly challenging when annotators must compare a target document against a vast number of historical documents. In this work, we introduce NovAScore (Novelty Evaluation in Atomicity Score), an automated metric for evaluating document-level novelty. NovAScore aggregates the novelty and salience scores of atomic information, providing high interpretability and a detailed analysis of a document's novelty. With its dynamic weight adjustment scheme, NovAScore offers enhanced flexibility and an additional dimension to assess both the novelty level and the importance of information within a document. Our experiments show that NovAScore strongly correlates with human judgments of novelty, achieving a 0.626 Point-Biserial correlation on the TAP-DLND 1.0 dataset and a 0.920 Pearson correlation on an internal human-annotated dataset.
Automatic Dialect Density Estimation for African American English
Apr 03, 2022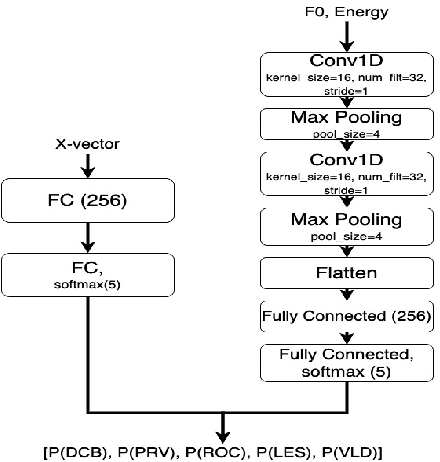
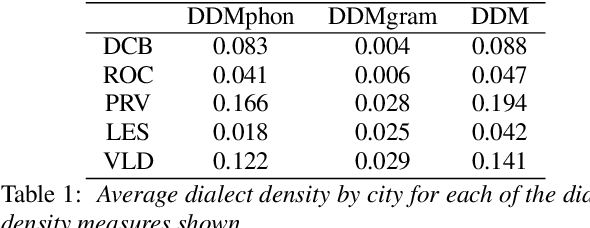
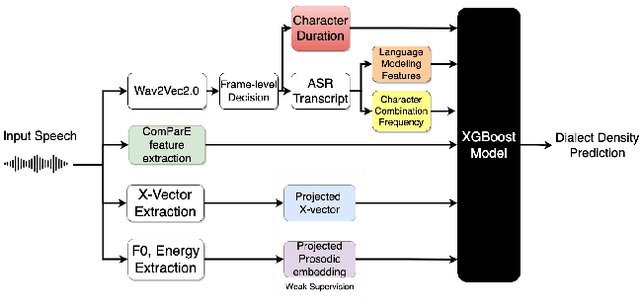
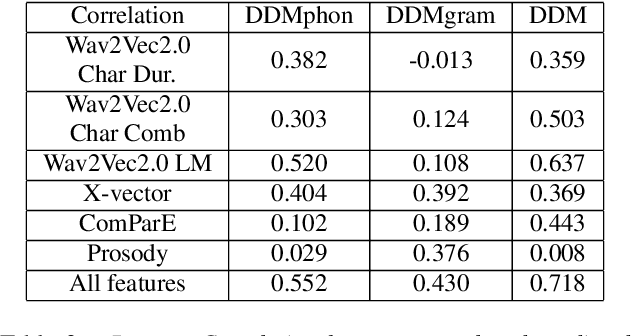
In this paper, we explore automatic prediction of dialect density of the African American English (AAE) dialect, where dialect density is defined as the percentage of words in an utterance that contain characteristics of the non-standard dialect. We investigate several acoustic and language modeling features, including the commonly used X-vector representation and ComParE feature set, in addition to information extracted from ASR transcripts of the audio files and prosodic information. To address issues of limited labeled data, we use a weakly supervised model to project prosodic and X-vector features into low-dimensional task-relevant representations. An XGBoost model is then used to predict the speaker's dialect density from these features and show which are most significant during inference. We evaluate the utility of these features both alone and in combination for the given task. This work, which does not rely on hand-labeled transcripts, is performed on audio segments from the CORAAL database. We show a significant correlation between our predicted and ground truth dialect density measures for AAE speech in this database and propose this work as a tool for explaining and mitigating bias in speech technology.
* 5 pages, 2 figures
LPC Augment: An LPC-Based ASR Data Augmentation Algorithm for Low and Zero-Resource Children's Dialects
Feb 22, 2022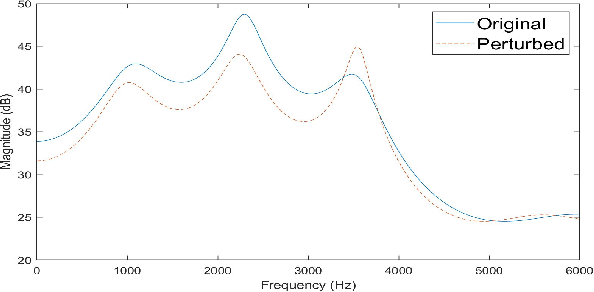
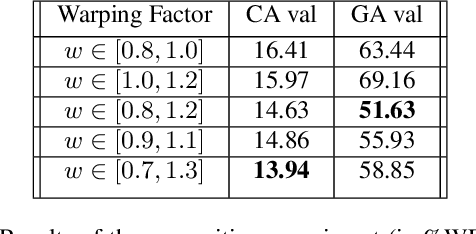
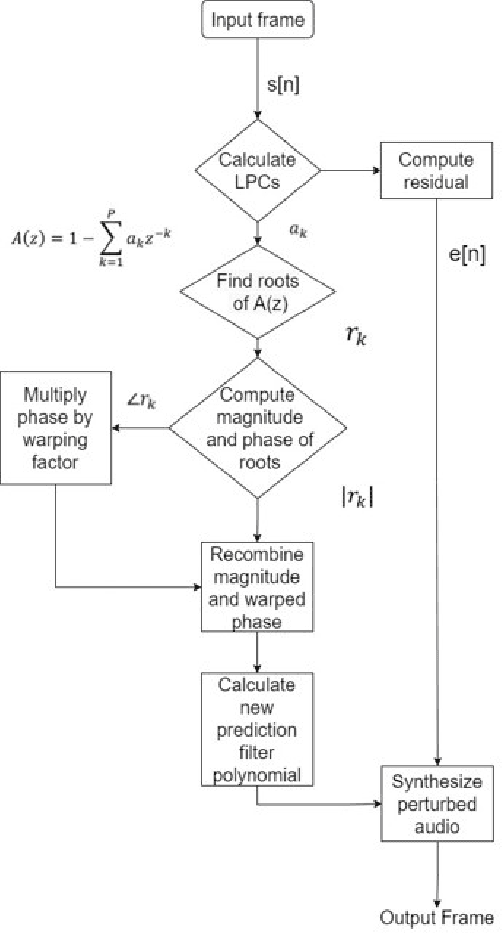
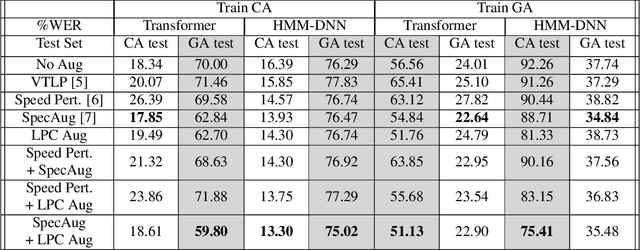
This paper proposes a novel linear prediction coding-based data aug-mentation method for children's low and zero resource dialect ASR. The data augmentation procedure consists of perturbing the formant peaks of the LPC spectrum during LPC analysis and reconstruction. The method is evaluated on two novel children's speech datasets with one containing California English from the Southern CaliforniaArea and the other containing a mix of Southern American English and African American English from the Atlanta, Georgia area. We test the proposed method in training both an HMM-DNN system and an end-to-end system to show model-robustness and demonstrate that the algorithm improves ASR performance, especially for zero resource dialect children's task, as compared to common data augmentation methods such as VTLP, Speed Perturbation, and SpecAugment.
* 5 pages, 2 figures
Can Social Robots Effectively Elicit Curiosity in STEM Topics from K-1 Students During Oral Assessments?
Feb 19, 2022



This paper presents the results of a pilot study that introduces social robots into kindergarten and first-grade classroom tasks. This study aims to understand 1) how effective social robots are in administering educational activities and assessments, and 2) if these interactions with social robots can serve as a gateway into learning about robotics and STEM for young children. We administered a commonly-used assessment (GFTA3) of speech production using a social robot and compared the quality of recorded responses to those obtained with a human assessor. In a comparison done between 40 children, we found no significant differences in the student responses between the two conditions over the three metrics used: word repetition accuracy, number of times additional help was needed, and similarity of prosody to the assessor. We also found that interactions with the robot were successfully able to stimulate curiosity in robotics, and therefore STEM, from a large number of the 164 student participants.
* 6 pages, 2 figures