 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREAM: Comparison-Based Reference-Free ELO-Ranked Automatic Evaluation for Meeting Summarization
Sep 17, 2024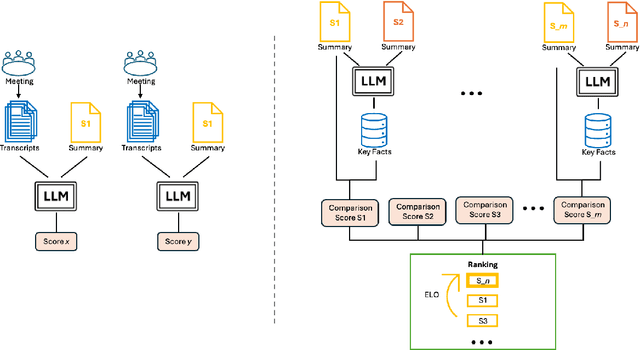


Large Language Models (LLMs) have spurred interest in automatic evaluation methods for summarization, offering a faster, more cost-effective alternative to human evaluation. However, existing methods often fall short when applied to complex tasks like long-context summarizations and dialogue-based meeting summarizations. In this paper, we introduce CREAM (Comparison-Based Reference-Free Elo-Ranked Automatic Evaluation for Meeting Summarization), a novel framework that addresses the unique challenges of evaluating meeting summaries. CREAM leverages a combination of chain-of-thought reasoning and key facts alignment to assess conciseness and completeness of model-generated summaries without requiring reference. By employing an ELO ranking system, our approach provides a robust mechanism for comparing the quality of different models or prompt configurations.
NovAScore: A New Automated Metric for Evaluating Document Level Novelty
Sep 14, 2024The rapid expansion of online content has intensified the issue of information redundancy, underscoring the need for solutions that can identify genuinely new information. Despite this challenge, the research community has seen a decline in focus on novelty detection, particularly with the rise of large language models (LLMs). Additionally, previous approaches have relied heavily on human annotation, which is time-consuming, costly, and particularly challenging when annotators must compare a target document against a vast number of historical documents. In this work, we introduce NovAScore (Novelty Evaluation in Atomicity Score), an automated metric for evaluating document-level novelty. NovAScore aggregates the novelty and salience scores of atomic information, providing high interpretability and a detailed analysis of a document's novelty. With its dynamic weight adjustment scheme, NovAScore offers enhanced flexibility and an additional dimension to assess both the novelty level and the importance of information within a document. Our experiments show that NovAScore strongly correlates with human judgments of novelty, achieving a 0.626 Point-Biserial correlation on the TAP-DLND 1.0 dataset and a 0.920 Pearson correlation on an internal human-annotated dataset.