 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Mental Manipulation in Speech via Synthetic Multi-Speaker Dialogue
Jan 13, 2026Mental manipulation, the strategic use of language to covertly influence or exploit others, is a newly emerging task in computational social reasoning. Prior work has focused exclusively on textual conversations, overlooking how manipulative tactics manifest in speech. We present the first study of mental manipulation detection in spoken dialogues, introducing a synthetic multi-speaker benchmark SPEECHMENTALMANIP that augments a text-based dataset with high-quality, voice-consistent Text-to-Speech rendered audio. Using few-shot large audio-language models and human annotation, we evaluate how modality affects detection accuracy and perception. Our results reveal that models exhibit high specificity but markedly lower recall on speech compared to text, suggesting sensitivity to missing acoustic or prosodic cues in training. Human raters show similar uncertainty in the audio setting, underscoring the inherent ambiguity of manipulative speech. Together, these findings highlight the need for modality-aware evaluation and safety alignment in multimodal dialogue systems.
Personalized Attacks of Social Engineering in Multi-turn Conversations -- LLM Agents for Simulation and Detection
Mar 18, 2025



The rapid advancement of conversational agents, particularly chatbots powered by Large Language Models (LLMs), poses a significant risk of social engineering (SE) attacks on social media platforms. SE detection in multi-turn, chat-based interactions is considerably more complex than single-instance detection due to the dynamic nature of these conversations. A critical factor in mitigating this threat is understanding the mechanisms through which SE attacks operate, specifically how attackers exploit vulnerabilities and how victims' personality traits contribute to their susceptibility. In this work, we propose an LLM-agentic framework, SE-VSim, to simulate SE attack mechanisms by generating multi-turn conversations. We model victim agents with varying personality traits to assess how psychological profiles influence susceptibility to manipulation. Using a dataset of over 1000 simulated conversations, we examine attack scenarios in which adversaries, posing as recruiters, funding agencies, and journalists, attempt to extract sensitive information. Based on this analysis, we present a proof of concept, SE-OmniGuard, to offer personalized protection to users by leveraging prior knowledge of the victims personality, evaluating attack strategies, and monitoring information exchanges in conversations to identify potential SE attempts.
Can Open-source LLMs Enhance Data Synthesis for Toxic Detection?: An Experimental Study
Dec 03, 2024
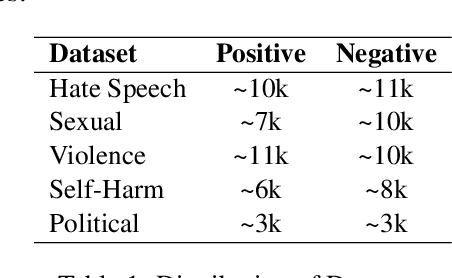


Effective toxic content detection relies heavily on high-quality and diverse data, which serves as the foundation for robust content moderation models. This study explores the potential of open-source LLMs for harmful data synthesis, utilizing prompt engineering and fine-tuning techniques to enhance data quality and diversity. In a two-stage evaluation, we first examine the capabilities of six open-source LLMs in generating harmful data across multiple datasets using prompt engineering. In the second stage, we fine-tune these models to improve data generation while addressing challenges such as hallucination, data duplication, and overfitting. Our findings reveal that Mistral excels in generating high-quality and diverse harmful data with minimal hallucination. Furthermore, fine-tuning enhances data quality, offering scalable and cost-effective solutions for augmenting datasets for specific toxic content detection tasks. These results emphasize the significance of data synthesis in building robust, standalone detection models and highlight the potential of open-source LLMs to advance smaller downstream content moderation systems. We implemented this approach in real-world industrial settings, demonstrating the feasibility and efficiency of fine-tuned open-source LLMs for harmful data synthesis.
Can Open-source LLMs Enhance Data Augmentation for Toxic Detection?: An Experimental Study
Nov 18, 2024High-quality, diverse harmful data is essential to addressing real-time applications in content moderation. Current state-of-the-art approaches to toxic content detection using GPT series models are costly and lack explainability. This paper investigates the use of prompt engineering and fine-tuning techniques on open-source LLMs to enhance harmful data augmentation specifically for toxic content detection. We conduct a two-stage empirical study, with stage 1 evaluating six open-source LLMs across multiple datasets using only prompt engineering and stage 2 focusing on fine-tuning. Our findings indicate that Mistral can excel in generating harmful data with minimal hallucination. While fine-tuning these models improves data quality and diversity, challenges such as data duplication and overfitting persist. Our experimental results highlight scalable, cost-effective strategies for enhancing toxic content detection systems. These findings not only demonstrate the potential of open-source LLMs in creating robust content moderation tools. The application of this method in real industrial scenarios further proves the feasibility and efficiency of the fine-tuned open-source LLMs for data augmentation. We hope our study will aid in understanding the capabilities and limitations of current models in toxic content detection and drive further advancements in this field.
CREAM: Comparison-Based Reference-Free ELO-Ranked Automatic Evaluation for Meeting Summarization
Sep 17, 2024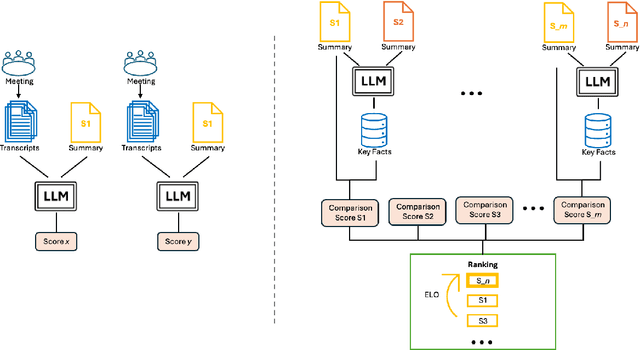


Large Language Models (LLMs) have spurred interest in automatic evaluation methods for summarization, offering a faster, more cost-effective alternative to human evaluation. However, existing methods often fall short when applied to complex tasks like long-context summarizations and dialogue-based meeting summarizations. In this paper, we introduce CREAM (Comparison-Based Reference-Free Elo-Ranked Automatic Evaluation for Meeting Summarization), a novel framework that addresses the unique challenges of evaluating meeting summaries. CREAM leverages a combination of chain-of-thought reasoning and key facts alignment to assess conciseness and completeness of model-generated summaries without requiring reference. By employing an ELO ranking system, our approach provides a robust mechanism for comparing the quality of different models or prompt configurations.
NovAScore: A New Automated Metric for Evaluating Document Level Novelty
Sep 14, 2024



The rapid expansion of online content has intensified the issue of information redundancy, underscoring the need for solutions that can identify genuinely new information. Despite this challenge, the research community has seen a decline in focus on novelty detection, particularly with the rise of large language models (LLMs). Additionally, previous approaches have relied heavily on human annotation, which is time-consuming, costly, and particularly challenging when annotators must compare a target document against a vast number of historical documents. In this work, we introduce NovAScore (Novelty Evaluation in Atomicity Score), an automated metric for evaluating document-level novelty. NovAScore aggregates the novelty and salience scores of atomic information, providing high interpretability and a detailed analysis of a document's novelty. With its dynamic weight adjustment scheme, NovAScore offers enhanced flexibility and an additional dimension to assess both the novelty level and the importance of information within a document. Our experiments show that NovAScore strongly correlates with human judgments of novelty, achieving a 0.626 Point-Biserial correlation on the TAP-DLND 1.0 dataset and a 0.920 Pearson correlation on an internal human-annotated dataset.
Beyond Silent Letters: Amplifying LLMs in Emotion Recognition with Vocal Nuances
Aug 01, 2024


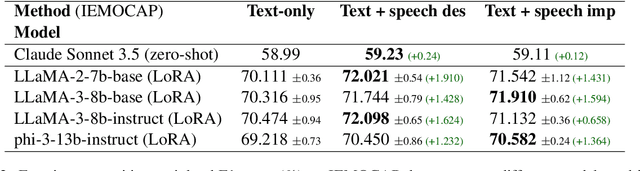
This paper introduces a novel approach to emotion detection in speech using Large Language Models (LLMs). We address the limitation of LLMs in processing audio inputs by translating speech characteristics into natural language descriptions. Our method integrates these descriptions into text prompts, enabling LLMs to perform multimodal emotion analysis without architectural modifications. We evaluate our approach on two datasets: IEMOCAP and MELD, demonstrating significant improvements in emotion recognition accuracy, particularly for high-quality audio data. Our experiments show that incorporating speech descriptions yields a 2 percentage point increase in weighted F1 score on IEMOCAP (from 70.111\% to 72.596\%). We also compare various LLM architectures and explore the effectiveness of different feature representations. Our findings highlight the potential of this approach in enhancing emotion detection capabilities of LLMs and underscore the importance of audio quality in speech-based emotion recognition tasks. We'll release the source code on Github.
Defending Against Social Engineering Attacks in the Age of LLMs
Jun 18, 2024



The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrieval-augmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity.
Enhancing Pre-Trained Generative Language Models with Question Attended Span Extraction on Machine Reading Comprehension
Apr 27, 2024Machine Reading Comprehension (MRC) poses a significant challenge in the field of Natural Language Processing (NLP). While mainstream MRC methods predominantly leverage extractive strategies using encoder-only models such as BERT, generative approaches face the issue of out-of-control generation -- a critical problem where answers generated are often incorrect, irrelevant, or unfaithful to the source text. To address these limitations in generative models for MRC, we introduce the Question-Attended Span Extraction (QASE) module. Integrated during the fine-tuning phase of pre-trained generative language models (PLMs), QASE significantly enhances their performance, allowing them to surpass the extractive capabilities of advanced Large Language Models (LLMs) such as GPT-4. Notably, these gains in performance do not come with an increase in computational demands. The efficacy of the QASE module has been rigorously tested across various datasets, consistently achieving or even surpassing state-of-the-art (SOTA) results.
QASE Enhanced PLMs: Improved Control in Text Generation for MRC
Feb 26, 2024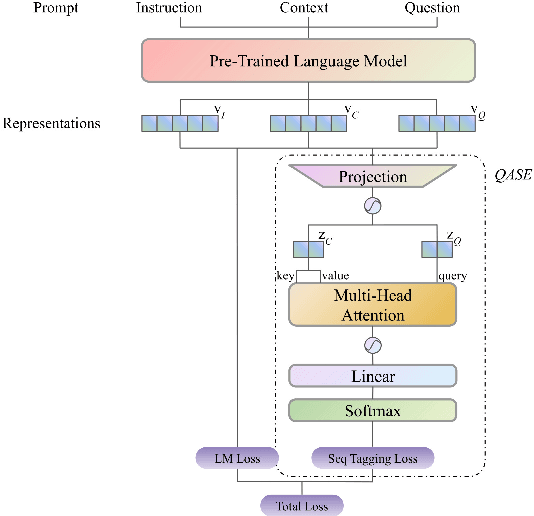
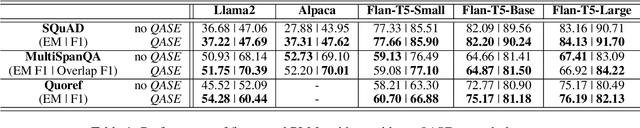
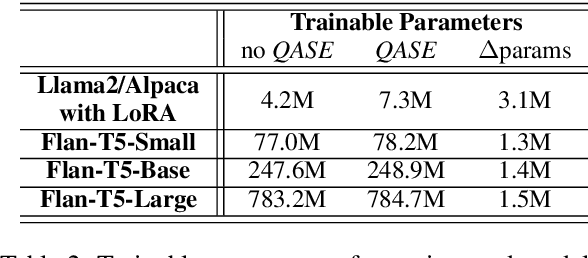
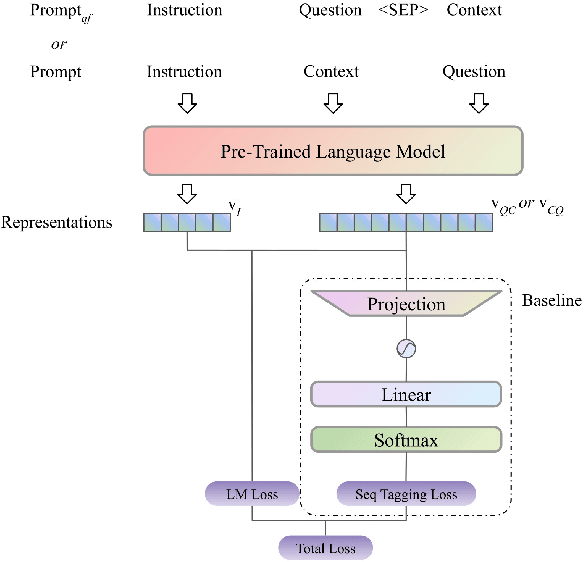
To address the challenges of out-of-control generation in generative models for machine reading comprehension (MRC), we introduce the Question-Attended Span Extraction (QASE) module. Integrated during the fine-tuning of pre-trained generative language models (PLMs), QASE enables these PLMs to match SOTA extractive methods and outperform leading LLMs like GPT-4 in MRC tasks, without significant increases in computational costs.