 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Against Social Engineering Attacks in the Age of LLMs
Jun 18, 2024



The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrieval-augmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity.
Comprehensive Dataset of Synthetic and Manipulated Overhead Imagery for Development and Evaluation of Forensic Tools
May 09, 2023We present a first of its kind dataset of overhead imagery for development and evaluation of forensic tools. Our dataset consists of real, fully synthetic and partially manipulated overhead imagery generated from a custom diffusion model trained on two sets of different zoom levels and on two sources of pristine data. We developed our model to support controllable generation of multiple manipulation categories including fully synthetic imagery conditioned on real and generated base maps, and location. We also support partial in-painted imagery with same conditioning options and with several types of manipulated content. The data consist of raw images and ground truth annotations describing the manipulation parameters. We also report benchmark performance on several tasks supported by our dataset including detection of fully and partially manipulated imagery, manipulation localization and classification.
Stylometric Detection of AI-Generated Text in Twitter Timelines
Mar 07, 2023



Recent advancements in pre-trained language models have enabled convenient methods for generating human-like text at a large scale. Though these generation capabilities hold great potential for breakthrough applications, it can also be a tool for an adversary to generate misinformation. In particular, social media platforms like Twitter are highly susceptible to AI-generated misinformation. A potential threat scenario is when an adversary hijacks a credible user account and incorporates a natural language generator to generate misinformation. Such threats necessitate automated detectors for AI-generated tweets in a given user's Twitter timeline. However, tweets are inherently short, thus making it difficult for current state-of-the-art pre-trained language model-based detectors to accurately detect at what point the AI starts to generate tweets in a given Twitter timeline. In this paper, we present a novel algorithm using stylometric signals to aid detecting AI-generated tweets. We propose models corresponding to quantifying stylistic changes in human and AI tweets in two related tasks: Task 1 - discriminate between human and AI-generated tweets, and Task 2 - detect if and when an AI starts to generate tweets in a given Twitter timeline. Our extensive experiments demonstrate that the stylometric features are effective in augmenting the state-of-the-art AI-generated text detectors.
Comprehensive Dataset of Face Manipulations for Development and Evaluation of Forensic Tools
Aug 24, 2022


Digital media (e.g., photographs, video) can be easily created, edited, and shared. Tools for editing digital media are capable of doing so while also maintaining a high degree of photo-realism. While many types of edits to digital media are generally benign, others can also be applied for malicious purposes. State-of-the-art face editing tools and software can, for example, artificially make a person appear to be smiling at an inopportune time, or depict authority figures as frail and tired in order to discredit individuals. Given the increasing ease of editing digital media and the potential risks from misuse, a substantial amount of effort has gone into media forensics. To this end, we created a challenge dataset of edited facial images to assist the research community in developing novel approaches to address and classify the authenticity of digital media. Our dataset includes edits applied to controlled, portrait-style frontal face images and full-scene in-the-wild images that may include multiple (i.e., more than one) face per image. The goals of our dataset is to address the following challenge questions: (1) Can we determine the authenticity of a given image (edit detection)? (2) If an image has been edited, can we \textit{localize} the edit region? (3) If an image has been edited, can we deduce (classify) what edit type was performed? The majority of research in image forensics generally attempts to answer item (1), detection. To the best of our knowledge, there are no formal datasets specifically curated to evaluate items (2) and (3), localization and classification, respectively. Our hope is that our prepared evaluation protocol will assist researchers in improving the state-of-the-art in image forensics as they pertain to these challenges.
Efficient Learning by Directed Acyclic Graph For Resource Constrained Prediction
Oct 26, 2015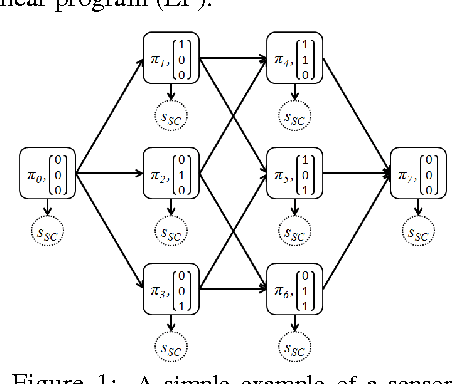
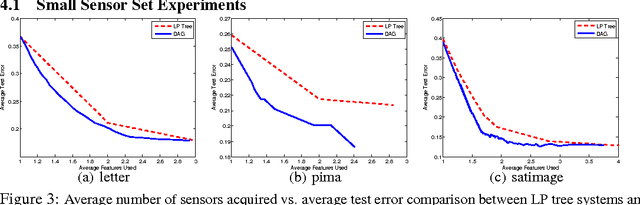
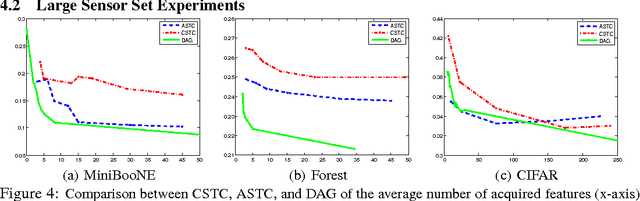
We study the problem of reducing test-time acquisition costs in classification systems. Our goal is to learn decision rules that adaptively select sensors for each example as necessary to make a confident prediction. We model our system as a directed acyclic graph (DAG) where internal nodes correspond to sensor subsets and decision functions at each node choose whether to acquire a new sensor or classify using the available measurements. This problem can be naturally posed as an empirical risk minimization over training data. Rather than jointly optimizing such a highly coupled and non-convex problem over all decision nodes, we propose an efficient algorithm motivated by dynamic programming. We learn node policies in the DAG by reducing the global objective to a series of cost sensitive learning problems. Our approach is computationally efficient and has proven guarantees of convergence to the optimal system for a fixed architecture. In addition, we present an extension to map other budgeted learning problems with large number of sensors to our DAG architecture and demonstrate empirical performance exceeding state-of-the-art algorithms for data composed of both few and many sensors.
Sensor Selection by Linear Programming
Sep 09, 2015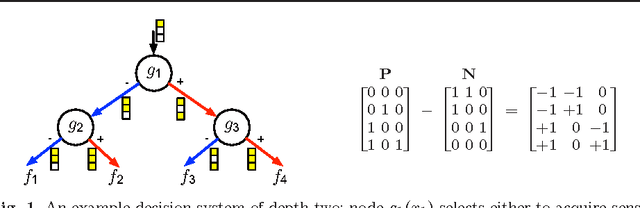

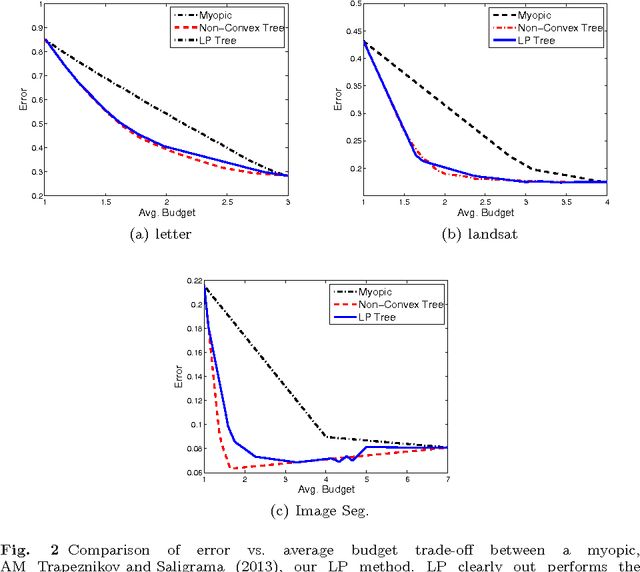
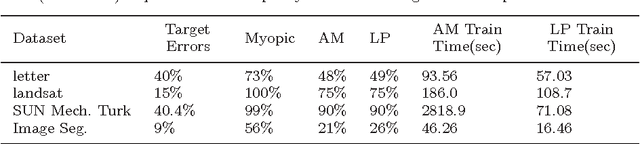
We learn sensor trees from training data to minimize sensor acquisition costs during test time. Our system adaptively selects sensors at each stage if necessary to make a confident classification. We pose the problem as empirical risk minimization over the choice of trees and node decision rules. We decompose the problem, which is known to be intractable, into combinatorial (tree structures) and continuous parts (node decision rules) and propose to solve them separately. Using training data we greedily solve for the combinatorial tree structures and for the continuous part, which is a non-convex multilinear objective function, we derive convex surrogate loss functions that are piecewise linear. The resulting problem can be cast as a linear program and has the advantage of guaranteed convergence, global optimality, repeatability and computational efficiency. We show that our proposed approach outperforms the state-of-art on a number of benchmark datasets.
Multi-Stage Classifier Design
Jan 29, 2013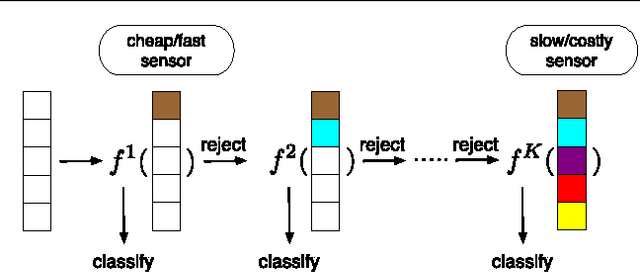

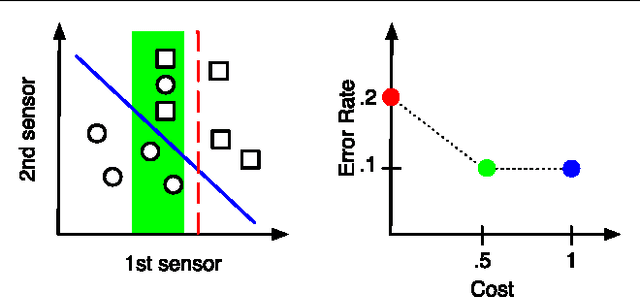
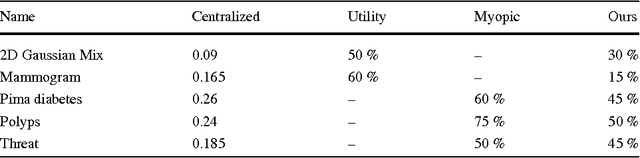
In many classification systems, sensing modalities have different acquisition costs. It is often {\it unnecessary} to use every modality to classify a majority of examples. We study a multi-stage system in a prediction time cost reduction setting, where the full data is available for training, but for a test example, measurements in a new modality can be acquired at each stage for an additional cost. We seek decision rules to reduce the average measurement acquisition cost. We formulate an empirical risk minimization problem (ERM) for a multi-stage reject classifier, wherein the stage $k$ classifier either classifies a sample using only the measurements acquired so far or rejects it to the next stage where more attributes can be acquired for a cost. To solve the ERM problem, we show that the optimal reject classifier at each stage is a combination of two binary classifiers, one biased towards positive examples and the other biased towards negative examples. We use this parameterization to construct stage-by-stage global surrogate risk, develop an iterative algorithm in the boosting framework and present convergence and generalization results. We test our work on synthetic, medical and explosives detection datasets. Our results demonstrate that substantial cost reduction without a significant sacrifice in accuracy is achievable.