 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Against Social Engineering Attacks in the Age of LLMs
Jun 18, 2024



The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrieval-augmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity.
BusTr: Predicting Bus Travel Times from Real-Time Traffic
Jul 02, 2020
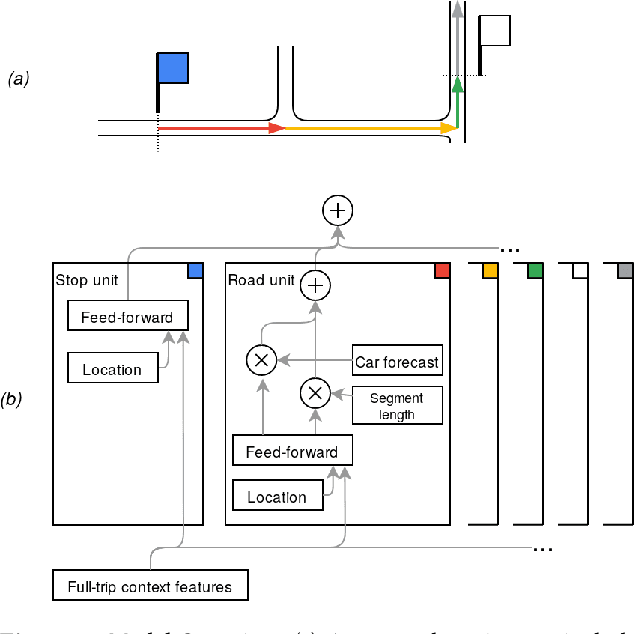

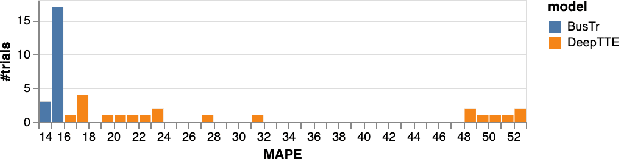
We present BusTr, a machine-learned model for translating road traffic forecasts into predictions of bus delays, used by Google Maps to serve the majority of the world's public transit systems where no official real-time bus tracking is provided. We demonstrate that our neural sequence model improves over DeepTTE, the state-of-the-art baseline, both in performance (-30% MAPE) and training stability. We also demonstrate significant generalization gains over simpler models, evaluated on longitudinal data to cope with a constantly evolving world.
Your Two Weeks of Fame and Your Grandmother's
Apr 19, 2012
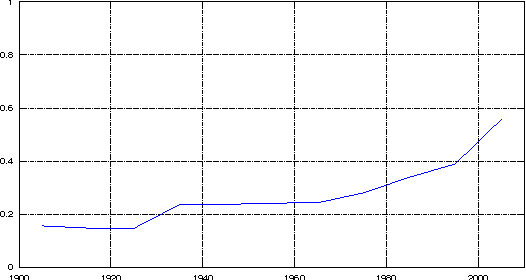
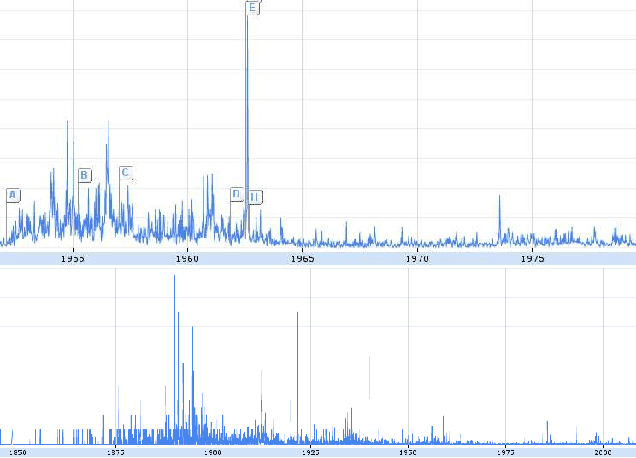
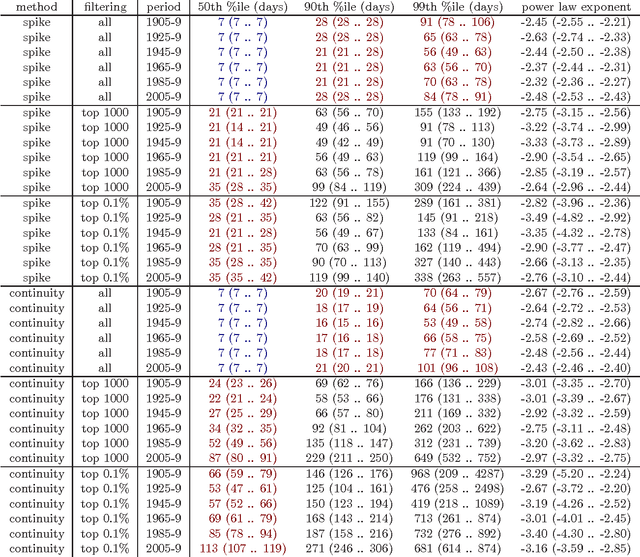
Did celebrity last longer in 1929, 1992 or 2009? We investigate the phenomenon of fame by mining a collection of news articles that spans the twentieth century, and also perform a side study on a collection of blog posts from the last 10 years. By analyzing mentions of personal names, we measure each person's time in the spotlight, using two simple metrics that evaluate, roughly, the duration of a single news story about a person, and the overall duration of public interest in a person. We watched the distribution evolve from 1895 to 2010, expecting to find significantly shortening fame durations, per the much popularly bemoaned shortening of society's attention spans and quickening of media's news cycles. Instead, we conclusively demonstrate that, through many decades of rapid technological and societal change, through the appearance of Twitter, communication satellites, and the Internet, fame durations did not decrease, neither for the typical case nor for the extremely famous, with the last statistically significant fame duration decreases coming in the early 20th century, perhaps from the spread of telegraphy and telephony. Furthermore, while median fame durations stayed persistently constant, for the most famous of the famous, as measured by either volume or duration of media attention, fame durations have actually trended gently upward since the 1940s, with statistically significant increases on 40-year timescales. Similar studies have been done with much shorter timescales specifically in the context of information spreading on Twitter and similar social networking sites. To the best of our knowledge, this is the first massive scale study of this nature that spans over a century of archived data, thereby allowing us to track changes across decades.