 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Dataset of Face Manipulations for Development and Evaluation of Forensic Tools
Aug 24, 2022
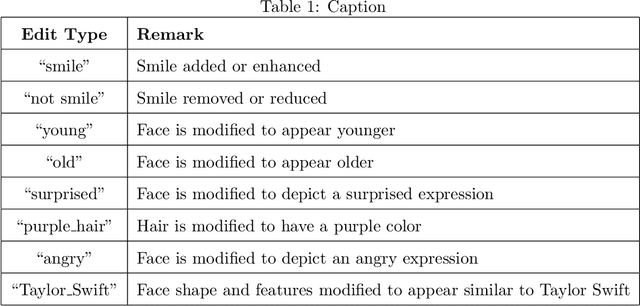


Digital media (e.g., photographs, video) can be easily created, edited, and shared. Tools for editing digital media are capable of doing so while also maintaining a high degree of photo-realism. While many types of edits to digital media are generally benign, others can also be applied for malicious purposes. State-of-the-art face editing tools and software can, for example, artificially make a person appear to be smiling at an inopportune time, or depict authority figures as frail and tired in order to discredit individuals. Given the increasing ease of editing digital media and the potential risks from misuse, a substantial amount of effort has gone into media forensics. To this end, we created a challenge dataset of edited facial images to assist the research community in developing novel approaches to address and classify the authenticity of digital media. Our dataset includes edits applied to controlled, portrait-style frontal face images and full-scene in-the-wild images that may include multiple (i.e., more than one) face per image. The goals of our dataset is to address the following challenge questions: (1) Can we determine the authenticity of a given image (edit detection)? (2) If an image has been edited, can we \textit{localize} the edit region? (3) If an image has been edited, can we deduce (classify) what edit type was performed? The majority of research in image forensics generally attempts to answer item (1), detection. To the best of our knowledge, there are no formal datasets specifically curated to evaluate items (2) and (3), localization and classification, respectively. Our hope is that our prepared evaluation protocol will assist researchers in improving the state-of-the-art in image forensics as they pertain to these challenges.
Key-Nets: Optical Transformation Convolutional Networks for Privacy Preserving Vision Sensors
Sep 11, 2020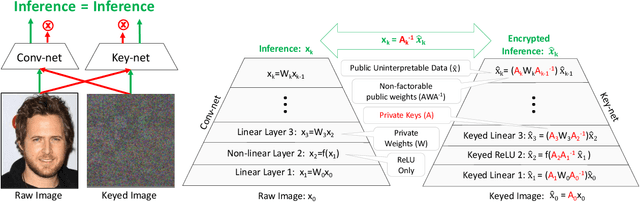
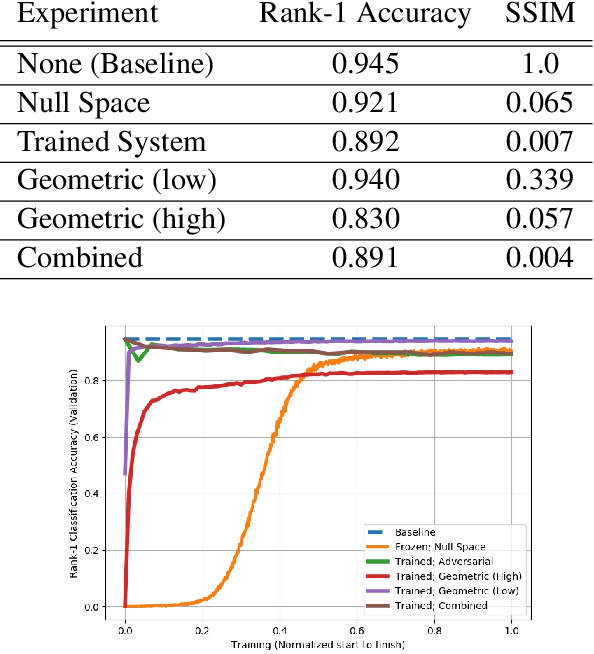

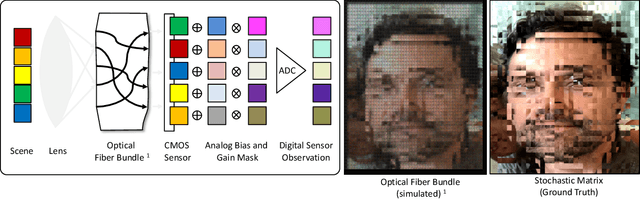
Modern cameras are not designed with computer vision or machine learning as the target application. There is a need for a new class of vision sensors that are privacy preserving by design, that do not leak private information and collect only the information necessary for a target machine learning task. In this paper, we introduce key-nets, which are convolutional networks paired with a custom vision sensor which applies an optical/analog transform such that the key-net can perform exact encrypted inference on this transformed image, but the image is not interpretable by a human or any other key-net. We provide five sufficient conditions for an optical transformation suitable for a key-net, and show that generalized stochastic matrices (e.g. scale, bias and fractional pixel shuffling) satisfy these conditions. We motivate the key-net by showing that without it there is a utility/privacy tradeoff for a network fine-tuned directly on optically transformed images for face identification and object detection. Finally, we show that a key-net is equivalent to homomorphic encryption using a Hill cipher, with an upper bound on memory and runtime that scales quadratically with a user specified privacy parameter. Therefore, the key-net is the first practical, efficient and privacy preserving vision sensor based on optical homomorphic encryption.