 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoppelgangers++: Improved Visual Disambiguation with Geometric 3D Features
Dec 08, 2024



Accurate 3D reconstruction is frequently hindered by visual aliasing, where visually similar but distinct surfaces (aka, doppelgangers), are incorrectly matched. These spurious matches distort the structure-from-motion (SfM) process, leading to misplaced model elements and reduced accuracy. Prior efforts addressed this with CNN classifiers trained on curated datasets, but these approaches struggle to generalize across diverse real-world scenes and can require extensive parameter tuning. In this work, we present Doppelgangers++, a method to enhance doppelganger detection and improve 3D reconstruction accuracy. Our contributions include a diversified training dataset that incorporates geo-tagged images from everyday scenes to expand robustness beyond landmark-based datasets. We further propose a Transformer-based classifier that leverages 3D-aware features from the MASt3R model, achieving superior precision and recall across both in-domain and out-of-domain tests. Doppelgangers++ integrates seamlessly into standard SfM and MASt3R-SfM pipelines, offering efficiency and adaptability across varied scenes. To evaluate SfM accuracy, we introduce an automated, geotag-based method for validating reconstructed models, eliminating the need for manual inspection. Through extensive experiments, we demonstrate that Doppelgangers++ significantly enhances pairwise visual disambiguation and improves 3D reconstruction quality in complex and diverse scenarios.
Fine-grained Activities of People Worldwide
Jul 11, 2022

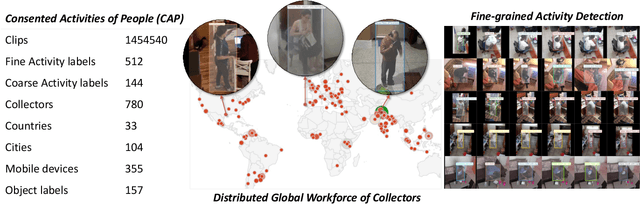
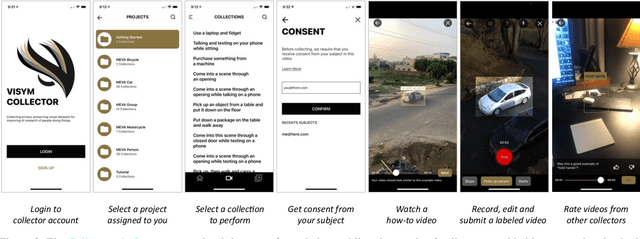
Every day, humans perform many closely related activities that involve subtle discriminative motions, such as putting on a shirt vs. putting on a jacket, or shaking hands vs. giving a high five. Activity recognition by ethical visual AI could provide insights into our patterns of daily life, however existing activity recognition datasets do not capture the massive diversity of these human activities around the world. To address this limitation, we introduce Collector, a free mobile app to record video while simultaneously annotating objects and activities of consented subjects. This new data collection platform was used to curate the Consented Activities of People (CAP) dataset, the first large-scale, fine-grained activity dataset of people worldwide. The CAP dataset contains 1.45M video clips of 512 fine grained activity labels of daily life, collected by 780 subjects in 33 countries. We provide activity classification and activity detection benchmarks for this dataset, and analyze baseline results to gain insight into how people around with world perform common activities. The dataset, benchmarks, evaluation tools, public leaderboards and mobile apps are available for use at visym.github.io/cap.
Key-Nets: Optical Transformation Convolutional Networks for Privacy Preserving Vision Sensors
Sep 11, 2020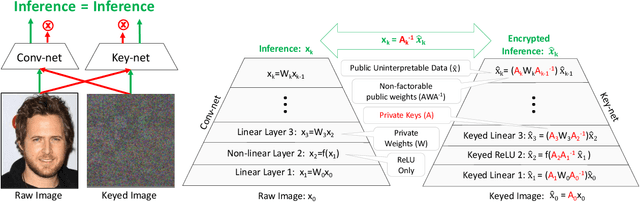
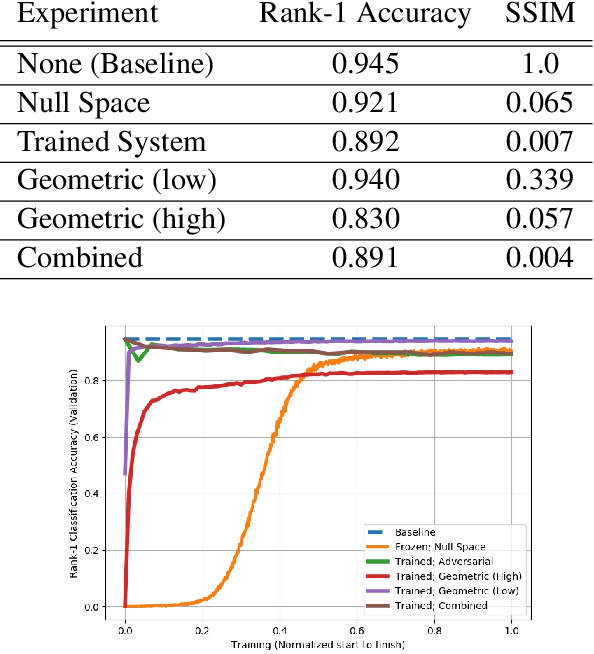

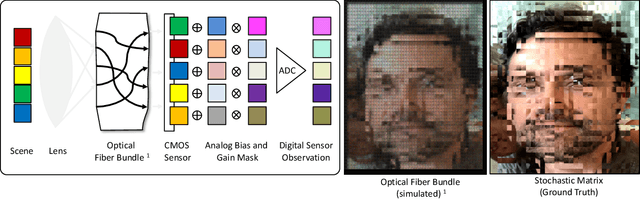
Modern cameras are not designed with computer vision or machine learning as the target application. There is a need for a new class of vision sensors that are privacy preserving by design, that do not leak private information and collect only the information necessary for a target machine learning task. In this paper, we introduce key-nets, which are convolutional networks paired with a custom vision sensor which applies an optical/analog transform such that the key-net can perform exact encrypted inference on this transformed image, but the image is not interpretable by a human or any other key-net. We provide five sufficient conditions for an optical transformation suitable for a key-net, and show that generalized stochastic matrices (e.g. scale, bias and fractional pixel shuffling) satisfy these conditions. We motivate the key-net by showing that without it there is a utility/privacy tradeoff for a network fine-tuned directly on optically transformed images for face identification and object detection. Finally, we show that a key-net is equivalent to homomorphic encryption using a Hill cipher, with an upper bound on memory and runtime that scales quadratically with a user specified privacy parameter. Therefore, the key-net is the first practical, efficient and privacy preserving vision sensor based on optical homomorphic encryption.
Inducing Predictive Uncertainty Estimation for Face Recognition
Sep 01, 2020



Knowing when an output can be trusted is critical for reliably using face recognition systems. While there has been enormous effort in recent research on improving face verification performance, understanding when a model's predictions should or should not be trusted has received far less attention. Our goal is to assign a confidence score for a face image that reflects its quality in terms of recognizable information. To this end, we propose a method for generating image quality training data automatically from 'mated-pairs' of face images, and use the generated data to train a lightweight Predictive Confidence Network, termed as PCNet, for estimating the confidence score of a face image. We systematically evaluate the usefulness of PCNet with its error versus reject performance, and demonstrate that it can be universally paired with and improve the robustness of any verification model. We describe three use cases on the public IJB-C face verification benchmark: (i) to improve 1:1 image-based verification error rates by rejecting low-quality face images; (ii) to improve quality score based fusion performance on the 1:1 set-based verification benchmark; and (iii) its use as a quality measure for selecting high quality (unblurred, good lighting, more frontal) faces from a collection, e.g. for automatic enrolment or display.
Explainable Face Recognition
Aug 03, 2020
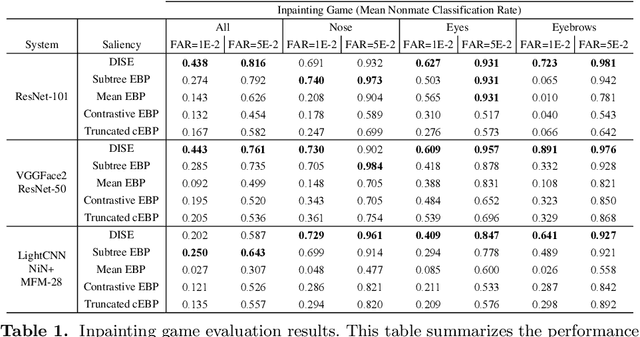

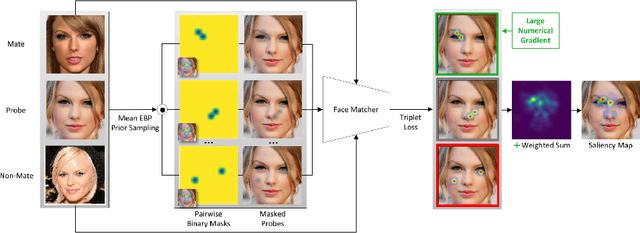
Explainable face recognition is the problem of explaining why a facial matcher matches faces. In this paper, we provide the first comprehensive benchmark and baseline evaluation for explainable face recognition. We define a new evaluation protocol called the ``inpainting game'', which is a curated set of 3648 triplets (probe, mate, nonmate) of 95 subjects, which differ by synthetically inpainting a chosen facial characteristic like the nose, eyebrows or mouth creating an inpainted nonmate. An explainable face matcher is tasked with generating a network attention map which best explains which regions in a probe image match with a mated image, and not with an inpainted nonmate for each triplet. This provides ground truth for quantifying what image regions contribute to face matching. Furthermore, we provide a comprehensive benchmark on this dataset comparing five state of the art methods for network attention in face recognition on three facial matchers. This benchmark includes two new algorithms for network attention called subtree EBP and Density-based Input Sampling for Explanation (DISE) which outperform the state of the art by a wide margin. Finally, we show qualitative visualization of these network attention techniques on novel images, and explore how these explainable face recognition models can improve transparency and trust for facial matchers.
Out the Window: A Crowd-Sourced Dataset for Activity Classification in Security Video
Sep 15, 2019

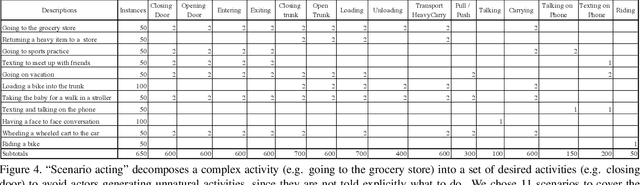
The Out the Window (OTW) dataset is a crowdsourced activity dataset containing 5,668 instances of 17 activities from the NIST Activities in Extended Video (ActEV) challenge. These videos are crowdsourced from workers on the Amazon Mechanical Turk using a novel scenario acting strategy, which collects multiple instances of natural activities per scenario. Turkers are instructed to lean their mobile device against an upper story window overlooking an outdoor space, walk outside to perform a scenario involving people, vehicles and objects, and finally upload the video to us for annotation. Performance evaluation for activity classification on VIRAT Ground 2.0 shows that the OTW dataset provides an 8.3% improvement in mean classification accuracy, and a 12.5% improvement on the most challenging activities involving people with vehicles.
Dataset Augmentation for Pose and Lighting Invariant Face Recognition
Apr 14, 2017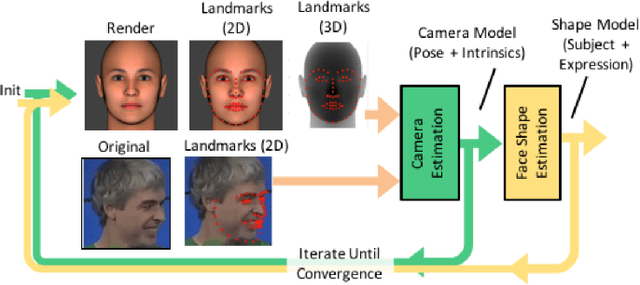



The performance of modern face recognition systems is a function of the dataset on which they are trained. Most datasets are largely biased toward "near-frontal" views with benign lighting conditions, negatively effecting recognition performance on images that do not meet these criteria. The proposed approach demonstrates how a baseline training set can be augmented to increase pose and lighting variability using semi-synthetic images with simulated pose and lighting conditions. The semi-synthetic images are generated using a fast and robust 3-d shape estimation and rendering pipeline which includes the full head and background. Various methods of incorporating the semi-synthetic renderings into the training procedure of a state of the art deep neural network-based recognition system without modifying the structure of the network itself are investigated. Quantitative results are presented on the challenging IJB-A identification dataset using a state of the art recognition pipeline as a baseline.
Template Adaptation for Face Verification and Identification
Apr 06, 2016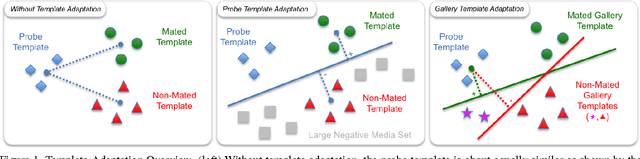
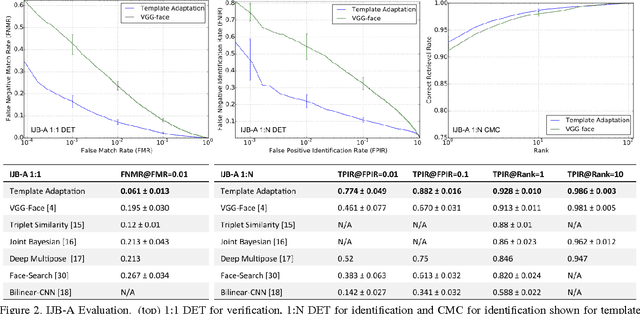

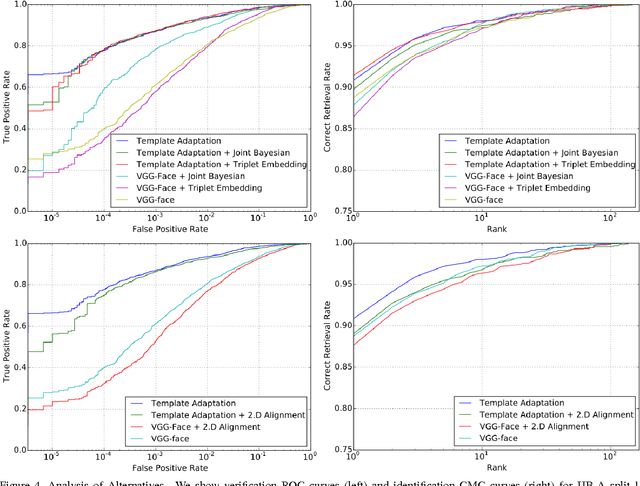
Face recognition performance evaluation has traditionally focused on one-to-one verification, popularized by the Labeled Faces in the Wild dataset for imagery and the YouTubeFaces dataset for videos. In contrast, the newly released IJB-A face recognition dataset unifies evaluation of one-to-many face identification with one-to-one face verification over templates, or sets of imagery and videos for a subject. In this paper, we study the problem of template adaptation, a form of transfer learning to the set of media in a template. Extensive performance evaluations on IJB-A show a surprising result, that perhaps the simplest method of template adaptation, combining deep convolutional network features with template specific linear SVMs, outperforms the state-of-the-art by a wide margin. We study the effects of template size, negative set construction and classifier fusion on performance, then compare template adaptation to convolutional networks with metric learning, 2D and 3D alignment. Our unexpected conclusion is that these other methods, when combined with template adaptation, all achieve nearly the same top performance on IJB-A for template-based face verification and identification.