 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetadata-free Georegistration of Ground and Airborne Imagery
Mar 06, 2025



Heterogeneous collections of ground and airborne imagery can readily be used to create high-quality 3D models and novel viewpoint renderings of the observed scene. Standard photogrammetry pipelines generate models in arbitrary coordinate systems, which is problematic for applications that require georegistered models. Even for applications that do not require georegistered models, georegistration is useful as a mechanism for aligning multiple disconnected models generated from non-overlapping data. The proposed method leverages satellite imagery, an associated digital surface model (DSM), and the novel view generation capabilities of modern 3D modeling techniques (e.g. neural radiance fields) to provide a robust method for georegistering airborne imagery, and a related technique for registering ground-based imagery to models created from airborne imagery. Experiments demonstrate successful georegistration of airborne and ground-based photogrammetric models across a variety of distinct sites. The proposed method does not require use of any metadata other than a satellite-based reference product and therefore has general applicability.
4-D Scene Alignment in Surveillance Video
Jun 06, 2019
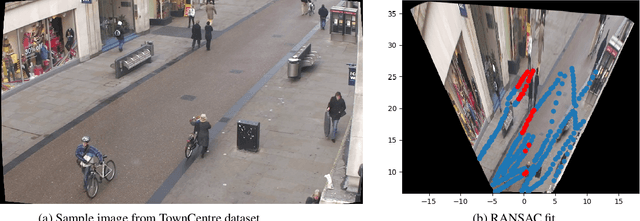


Designing robust activity detectors for fixed camera surveillance video requires knowledge of the 3-D scene. This paper presents an automatic camera calibration process that provides a mechanism to reason about the spatial proximity between objects at different times. It combines a CNN-based camera pose estimator with a vertical scale provided by pedestrian observations to establish the 4-D scene geometry. Unlike some previous methods, the people do not need to be tracked nor do the head and feet need to be explicitly detected. It is robust to individual height variations and camera parameter estimation errors.
Pix2face: Direct 3D Face Model Estimation
Aug 29, 2017

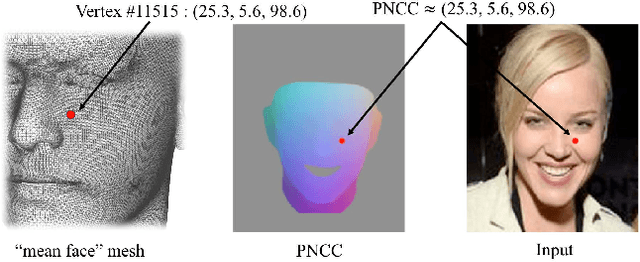

An efficient, fully automatic method for 3D face shape and pose estimation in unconstrained 2D imagery is presented. The proposed method jointly estimates a dense set of 3D landmarks and facial geometry using a single pass of a modified version of the popular "U-Net" neural network architecture. Additionally, we propose a method for directly estimating a set of 3D Morphable Model (3DMM) parameters, using the estimated 3D landmarks and geometry as constraints in a simple linear system. Qualitative modeling results are presented, as well as quantitative evaluation of predicted 3D face landmarks in unconstrained video sequences.
Robust Registration and Geometry Estimation from Unstructured Facial Scans
Aug 17, 2017

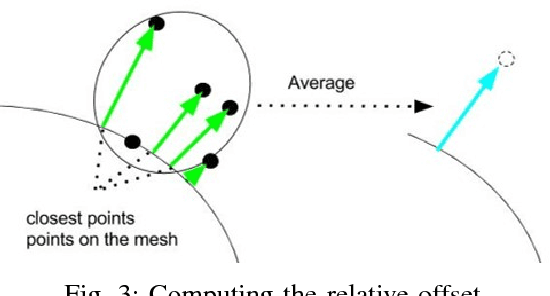
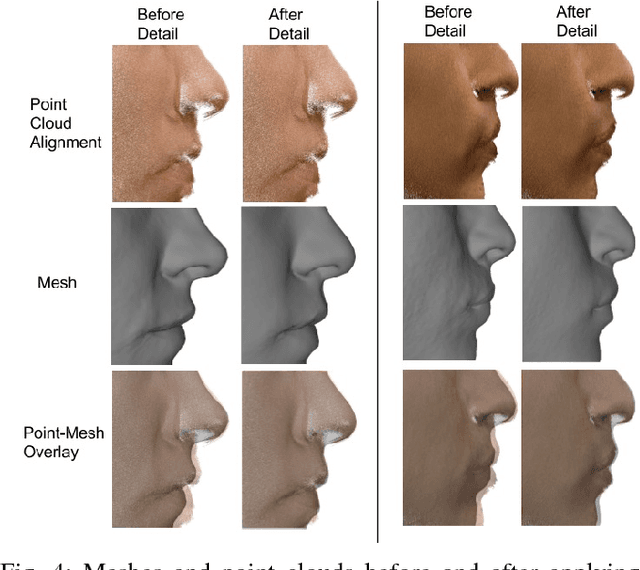
Commercial off the shelf (COTS) 3D scanners are capable of generating point clouds covering visible portions of a face with sub-millimeter accuracy at close range, but lack the coverage and specialized anatomic registration provided by more expensive 3D facial scanners. We demonstrate an effective pipeline for joint alignment of multiple unstructured 3D point clouds and registration to a parameterized 3D model which represents shape variation of the human head. Most algorithms separate the problems of pose estimation and mesh warping, however we propose a new iterative method where these steps are interwoven. Error decreases with each iteration, showing the proposed approach is effective in improving geometry and alignment. The approach described is used to align the NDOff-2007 dataset, which contains 7,358 individual scans at various poses of 396 subjects. The dataset has a number of full profile scans which are correctly aligned and contribute directly to the associated mesh geometry. The dataset in its raw form contains a significant number of mislabeled scans, which are identified and corrected based on alignment error using the proposed algorithm. The average point to surface distance between the aligned scans and the produced geometries is one half millimeter.
Dataset Augmentation for Pose and Lighting Invariant Face Recognition
Apr 14, 2017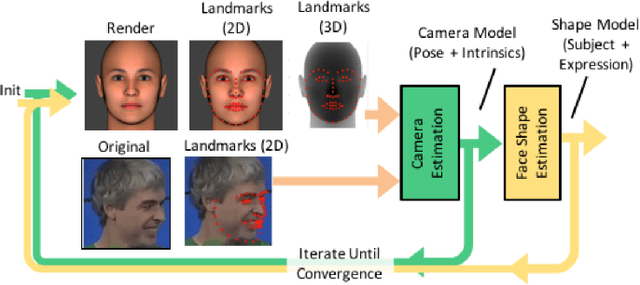



The performance of modern face recognition systems is a function of the dataset on which they are trained. Most datasets are largely biased toward "near-frontal" views with benign lighting conditions, negatively effecting recognition performance on images that do not meet these criteria. The proposed approach demonstrates how a baseline training set can be augmented to increase pose and lighting variability using semi-synthetic images with simulated pose and lighting conditions. The semi-synthetic images are generated using a fast and robust 3-d shape estimation and rendering pipeline which includes the full head and background. Various methods of incorporating the semi-synthetic renderings into the training procedure of a state of the art deep neural network-based recognition system without modifying the structure of the network itself are investigated. Quantitative results are presented on the challenging IJB-A identification dataset using a state of the art recognition pipeline as a baseline.