 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Activities of People Worldwide
Jul 11, 2022

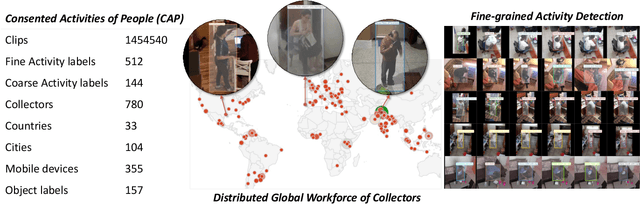
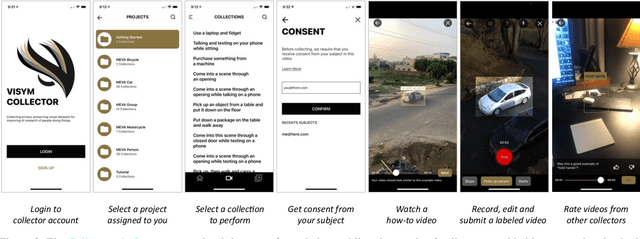
Every day, humans perform many closely related activities that involve subtle discriminative motions, such as putting on a shirt vs. putting on a jacket, or shaking hands vs. giving a high five. Activity recognition by ethical visual AI could provide insights into our patterns of daily life, however existing activity recognition datasets do not capture the massive diversity of these human activities around the world. To address this limitation, we introduce Collector, a free mobile app to record video while simultaneously annotating objects and activities of consented subjects. This new data collection platform was used to curate the Consented Activities of People (CAP) dataset, the first large-scale, fine-grained activity dataset of people worldwide. The CAP dataset contains 1.45M video clips of 512 fine grained activity labels of daily life, collected by 780 subjects in 33 countries. We provide activity classification and activity detection benchmarks for this dataset, and analyze baseline results to gain insight into how people around with world perform common activities. The dataset, benchmarks, evaluation tools, public leaderboards and mobile apps are available for use at visym.github.io/cap.
Enlightening Deep Neural Networks with Knowledge of Confounding Factors
Jul 08, 2016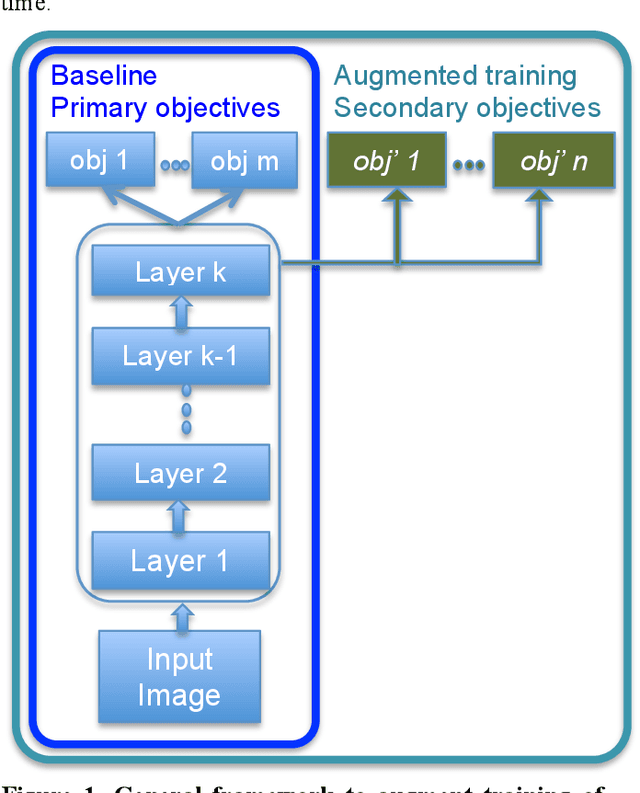
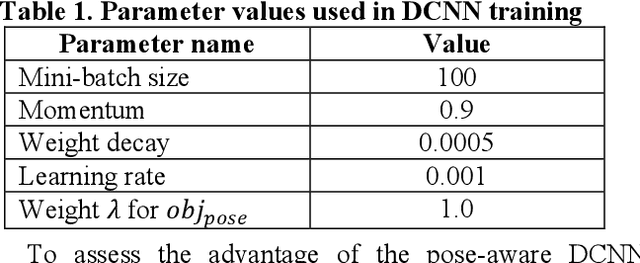

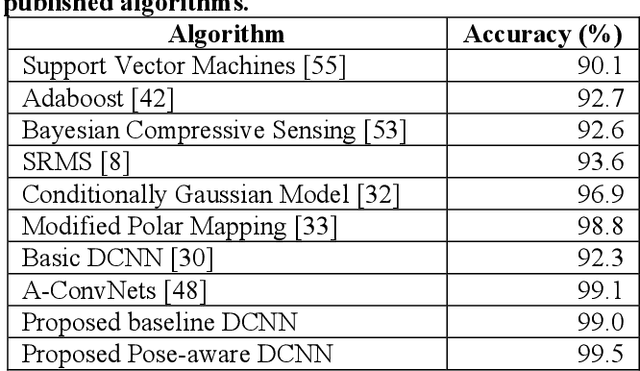
Deep learning techniques have demonstrated significant capacity in modeling some of the most challenging real world problems of high complexity. Despite the popularity of deep models, we still strive to better understand the underlying mechanism that drives their success. Motivated by observations that neurons in trained deep nets predict attributes indirectly related to the training tasks, we recognize that a deep network learns representations more general than the task at hand to disentangle impacts of multiple confounding factors governing the data, in order to isolate the effects of the concerning factors and optimize a given objective. Consequently, we propose a general framework to augment training of deep models with information on auxiliary explanatory data variables, in an effort to boost this disentanglement and train deep networks that comprehend the data interactions and distributions more accurately, and thus improve their generalizability. We incorporate information on prominent auxiliary explanatory factors of the data population into existing architectures as secondary objective/loss blocks that take inputs from hidden layers during training. Once trained, these secondary circuits can be removed to leave a model with the same architecture as the original, but more generalizable and discerning thanks to its comprehension of data interactions. Since pose is one of the most dominant confounding factors for object recognition, we apply this principle to instantiate a pose-aware deep convolutional neural network and demonstrate that auxiliary pose information indeed improves the classification accuracy in our experiments on SAR target classification tasks.