 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Layer Saliency in Language Transformers
Aug 09, 2023



In this paper, we introduce a strategy for identifying textual saliency in large-scale language models applied to classification tasks. In visual networks where saliency is more well-studied, saliency is naturally localized through the convolutional layers of the network; however, the same is not true in modern transformer-stack networks used to process natural language. We adapt gradient-based saliency methods for these networks, propose a method for evaluating the degree of semantic coherence of each layer, and demonstrate consistent improvement over numerous other methods for textual saliency on multiple benchmark classification datasets. Our approach requires no additional training or access to labelled data, and is comparatively very computationally efficient.
Out the Window: A Crowd-Sourced Dataset for Activity Classification in Security Video
Sep 15, 2019

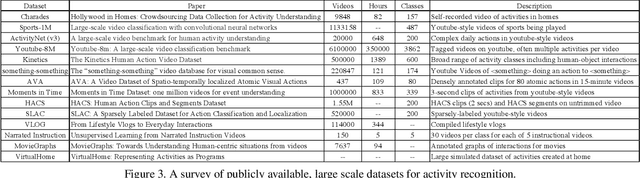
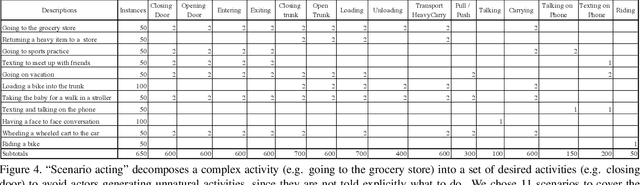
The Out the Window (OTW) dataset is a crowdsourced activity dataset containing 5,668 instances of 17 activities from the NIST Activities in Extended Video (ActEV) challenge. These videos are crowdsourced from workers on the Amazon Mechanical Turk using a novel scenario acting strategy, which collects multiple instances of natural activities per scenario. Turkers are instructed to lean their mobile device against an upper story window overlooking an outdoor space, walk outside to perform a scenario involving people, vehicles and objects, and finally upload the video to us for annotation. Performance evaluation for activity classification on VIRAT Ground 2.0 shows that the OTW dataset provides an 8.3% improvement in mean classification accuracy, and a 12.5% improvement on the most challenging activities involving people with vehicles.