 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Say "I Don't Know"
Sep 11, 2022
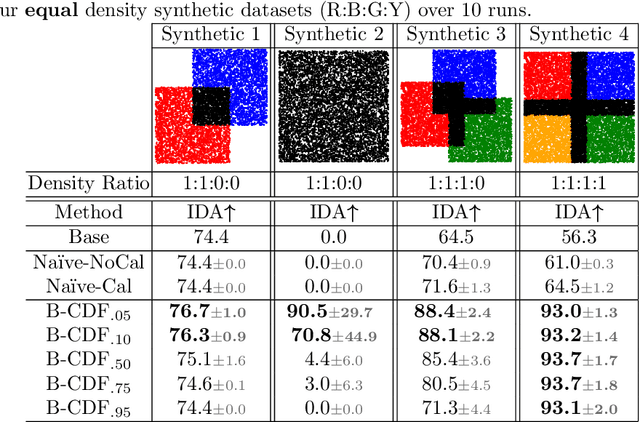
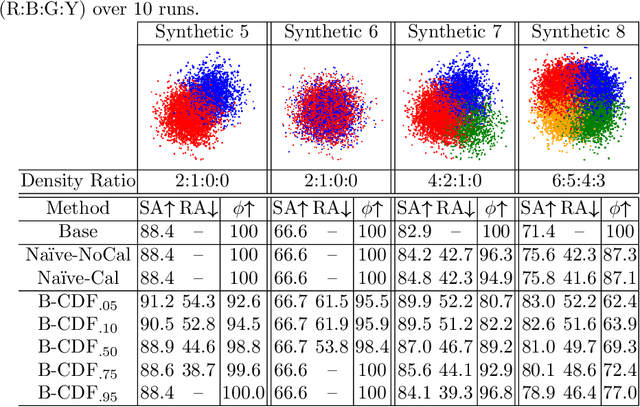
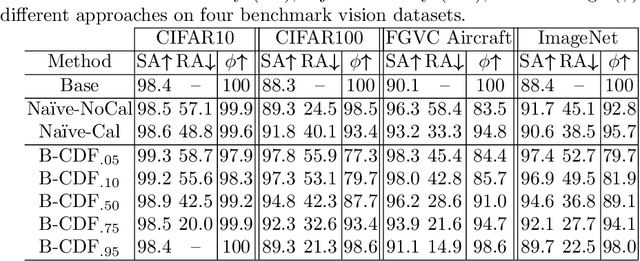
We propose a new Reject Option Classification technique to identify and remove regions of uncertainty in the decision space for a given neural classifier and dataset. Such existing formulations employ a learned rejection (remove)/selection (keep) function and require either a known cost for rejecting examples or strong constraints on the accuracy or coverage of the selected examples. We consider an alternative formulation by instead analyzing the complementary reject region and employing a validation set to learn per-class softmax thresholds. The goal is to maximize the accuracy of the selected examples subject to a natural randomness allowance on the rejected examples (rejecting more incorrect than correct predictions). We provide results showing the benefits of the proposed method over na\"ively thresholding calibrated/uncalibrated softmax scores with 2-D points, imagery, and text classification datasets using state-of-the-art pretrained models. Source code is available at https://github.com/osu-cvl/learning-idk.
Out the Window: A Crowd-Sourced Dataset for Activity Classification in Security Video
Sep 15, 2019

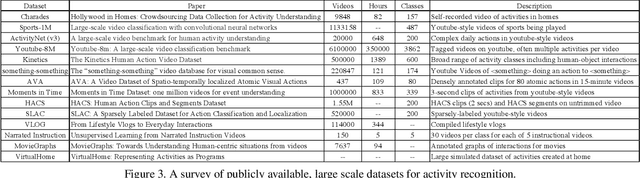
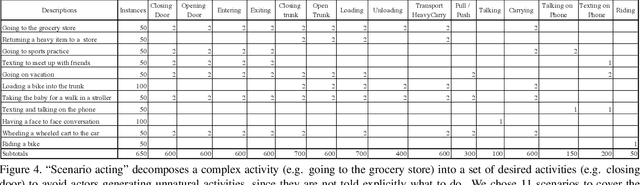
The Out the Window (OTW) dataset is a crowdsourced activity dataset containing 5,668 instances of 17 activities from the NIST Activities in Extended Video (ActEV) challenge. These videos are crowdsourced from workers on the Amazon Mechanical Turk using a novel scenario acting strategy, which collects multiple instances of natural activities per scenario. Turkers are instructed to lean their mobile device against an upper story window overlooking an outdoor space, walk outside to perform a scenario involving people, vehicles and objects, and finally upload the video to us for annotation. Performance evaluation for activity classification on VIRAT Ground 2.0 shows that the OTW dataset provides an 8.3% improvement in mean classification accuracy, and a 12.5% improvement on the most challenging activities involving people with vehicles.
Freezing Subnetworks to Analyze Domain Adaptation in Neural Machine Translation
Sep 14, 2018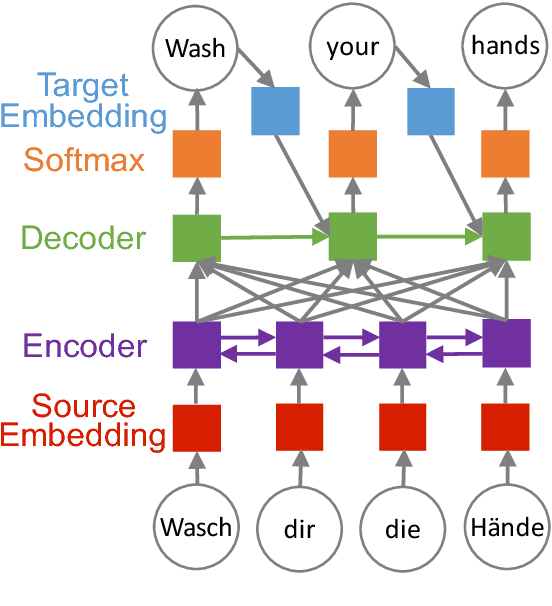
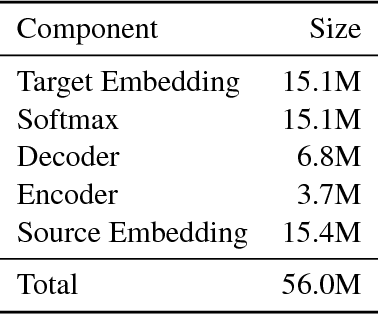
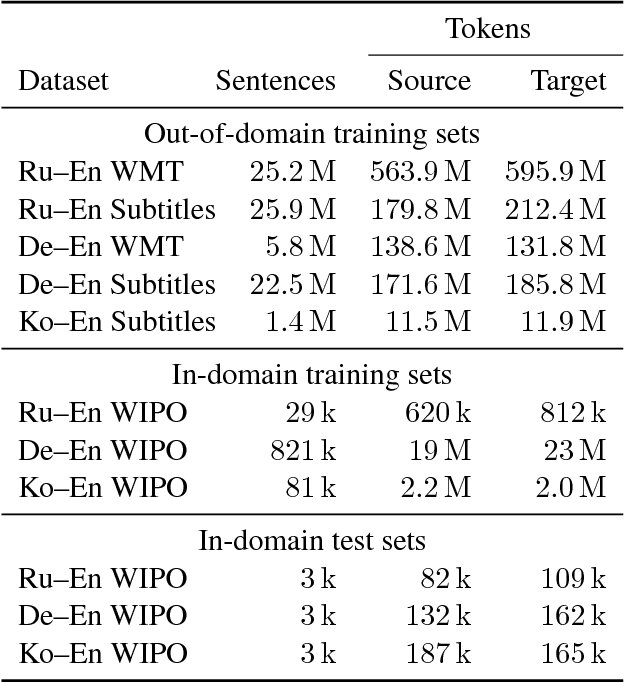
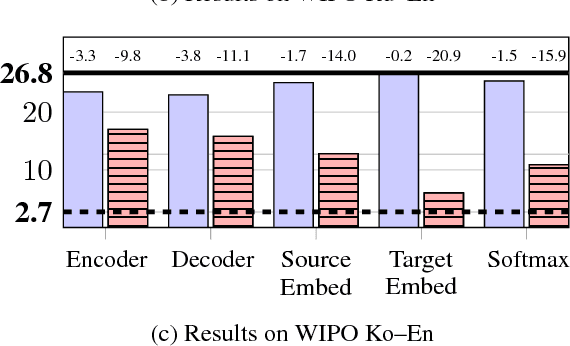
To better understand the effectiveness of continued training, we analyze the major components of a neural machine translation system (the encoder, decoder, and each embedding space) and consider each component's contribution to, and capacity for, domain adaptation. We find that freezing any single component during continued training has minimal impact on performance, and that performance is surprisingly good when a single component is adapted while holding the rest of the model fixed. We also find that continued training does not move the model very far from the out-of-domain model, compared to a sensitivity analysis metric, suggesting that the out-of-domain model can provide a good generic initialization for the new domain.