 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Better Mistakes in CLIP-Based Zero-Shot Classification with Hierarchy-Aware Language Prompts
Mar 04, 2025Recent studies are leveraging advancements in large language models (LLMs) trained on extensive internet-crawled text data to generate textual descriptions of downstream classes in CLIP-based zero-shot image classification. While most of these approaches aim at improving accuracy, our work focuses on ``making better mistakes", of which the mistakes' severities are derived from the given label hierarchy of downstream tasks. Since CLIP's image encoder is trained with language supervising signals, it implicitly captures the hierarchical semantic relationships between different classes. This motivates our goal of making better mistakes in zero-shot classification, a task for which CLIP is naturally well-suited. Our approach (HAPrompts) queries the language model to produce textual representations for given classes as zero-shot classifiers of CLIP to perform image classification on downstream tasks. To our knowledge, this is the first work to introduce making better mistakes in CLIP-based zero-shot classification. Our approach outperforms the related methods in a holistic comparison across five datasets of varying scales with label hierarchies of different heights in our experiments. Our code and LLM-generated image prompts: \href{https://github.com/ltong1130ztr/HAPrompts}{https://github.com/ltong1130ztr/HAPrompts}.
What Makes a Good Dataset for Knowledge Distillation?
Nov 19, 2024



Knowledge distillation (KD) has been a popular and effective method for model compression. One important assumption of KD is that the teacher's original dataset will also be available when training the student. However, in situations such as continual learning and distilling large models trained on company-withheld datasets, having access to the original data may not always be possible. This leads practitioners towards utilizing other sources of supplemental data, which could yield mixed results. One must then ask: "what makes a good dataset for transferring knowledge from teacher to student?" Many would assume that only real in-domain imagery is viable, but is that the only option? In this work, we explore multiple possible surrogate distillation datasets and demonstrate that many different datasets, even unnatural synthetic imagery, can serve as a suitable alternative in KD. From examining these alternative datasets, we identify and present various criteria describing what makes a good dataset for distillation. Source code will be available in the future.
Deep Learning Improvements for Sparse Spatial Field Reconstruction
Aug 22, 2024Accurately reconstructing a global spatial field from sparse data has been a longstanding problem in several domains, such as Earth Sciences and Fluid Dynamics. Historically, scientists have approached this problem by employing complex physics models to reconstruct the spatial fields. However, these methods are often computationally intensive. With the increase in popularity of machine learning (ML), several researchers have applied ML to the spatial field reconstruction task and observed improvements in computational efficiency. One such method in arXiv:2101.00554 utilizes a sparse mask of sensor locations and a Voronoi tessellation with sensor measurements as inputs to a convolutional neural network for reconstructing the global spatial field. In this work, we propose multiple adjustments to the aforementioned approach and show improvements on geoscience and fluid dynamics simulation datasets. We identify and discuss scenarios that benefit the most using the proposed ML-based spatial field reconstruction approach.
Data-Free Knowledge Distillation Using Adversarially Perturbed OpenGL Shader Images
Oct 20, 2023



Knowledge distillation (KD) has been a popular and effective method for model compression. One important assumption of KD is that the original training dataset is always available. However, this is not always the case due to privacy concerns and more. In recent years, "data-free" KD has emerged as a growing research topic which focuses on the scenario of performing KD when no data is provided. Many methods rely on a generator network to synthesize examples for distillation (which can be difficult to train) and can frequently produce images that are visually similar to the original dataset, which raises questions surrounding whether privacy is completely preserved. In this work, we propose a new approach to data-free KD that utilizes unnatural OpenGL images, combined with large amounts of data augmentation and adversarial attacks, to train a student network. We demonstrate that our approach achieves state-of-the-art results for a variety of datasets/networks and is more stable than existing generator-based data-free KD methods. Source code will be available in the future.
Inducing Neural Collapse to a Fixed Hierarchy-Aware Frame for Reducing Mistake Severity
Mar 10, 2023There is a recently discovered and intriguing phenomenon called Neural Collapse: at the terminal phase of training a deep neural network for classification, the within-class penultimate feature means and the associated classifier vectors of all flat classes collapse to the vertices of a simplex Equiangular Tight Frame (ETF). Recent work has tried to exploit this phenomenon by fixing the related classifier weights to a pre-computed ETF to induce neural collapse and maximize the separation of the learned features when training with imbalanced data. In this work, we propose to fix the linear classifier of a deep neural network to a Hierarchy-Aware Frame (HAFrame), instead of an ETF, and use a cosine similarity-based auxiliary loss to learn hierarchy-aware penultimate features that collapse to the HAFrame. We demonstrate that our approach reduces the mistake severity of the model's predictions while maintaining its top-1 accuracy on several datasets of varying scales with hierarchies of heights ranging from 3 to 12. We will release our code on GitHub in the near future.
Enhancing Self-Training Methods
Jan 18, 2023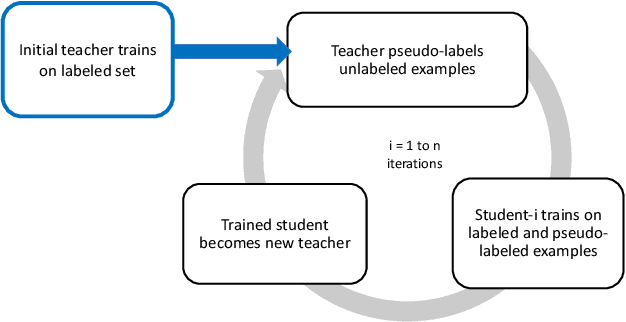

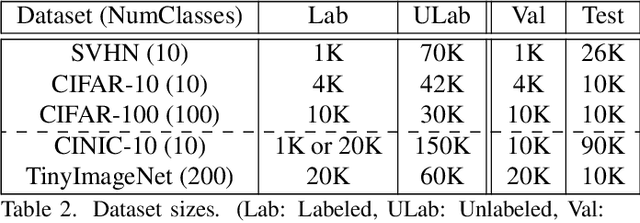
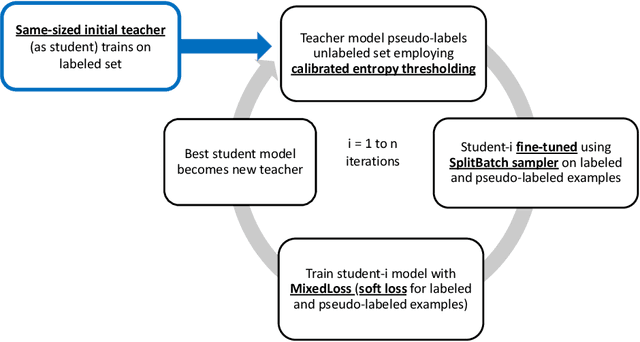
Semi-supervised learning approaches train on small sets of labeled data along with large sets of unlabeled data. Self-training is a semi-supervised teacher-student approach that often suffers from the problem of "confirmation bias" that occurs when the student model repeatedly overfits to incorrect pseudo-labels given by the teacher model for the unlabeled data. This bias impedes improvements in pseudo-label accuracy across self-training iterations, leading to unwanted saturation in model performance after just a few iterations. In this work, we describe multiple enhancements to improve the self-training pipeline to mitigate the effect of confirmation bias. We evaluate our enhancements over multiple datasets showing performance gains over existing self-training design choices. Finally, we also study the extendability of our enhanced approach to Open Set unlabeled data (containing classes not seen in labeled data).
Learning When to Say "I Don't Know"
Sep 11, 2022
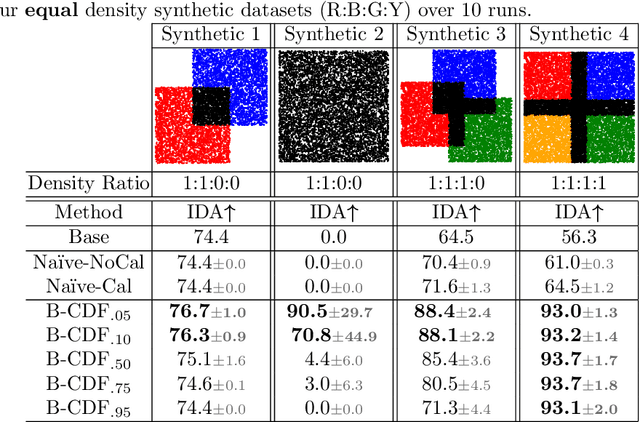
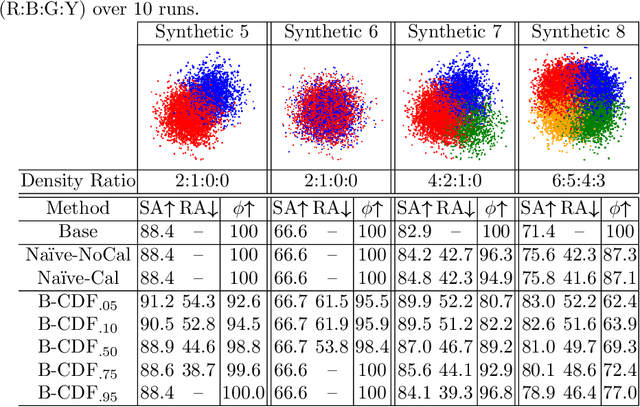
We propose a new Reject Option Classification technique to identify and remove regions of uncertainty in the decision space for a given neural classifier and dataset. Such existing formulations employ a learned rejection (remove)/selection (keep) function and require either a known cost for rejecting examples or strong constraints on the accuracy or coverage of the selected examples. We consider an alternative formulation by instead analyzing the complementary reject region and employing a validation set to learn per-class softmax thresholds. The goal is to maximize the accuracy of the selected examples subject to a natural randomness allowance on the rejected examples (rejecting more incorrect than correct predictions). We provide results showing the benefits of the proposed method over na\"ively thresholding calibrated/uncalibrated softmax scores with 2-D points, imagery, and text classification datasets using state-of-the-art pretrained models. Source code is available at https://github.com/osu-cvl/learning-idk.
Confident AI
Feb 12, 2022In this paper, we propose "Confident AI" as a means to designing Artificial Intelligence (AI) and Machine Learning (ML) systems with both algorithm and user confidence in model predictions and reported results. The 4 basic tenets of Confident AI are Repeatability, Believability, Sufficiency, and Adaptability. Each of the tenets is used to explore fundamental issues in current AI/ML systems and together provide an overall approach to Confident AI.
Revisiting Batch Normalization
Oct 26, 2021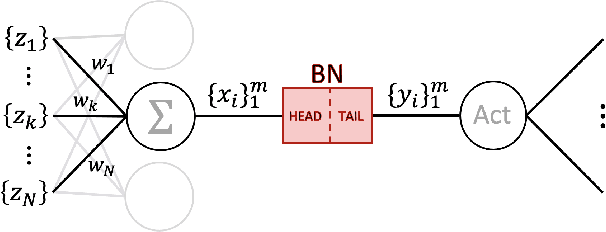
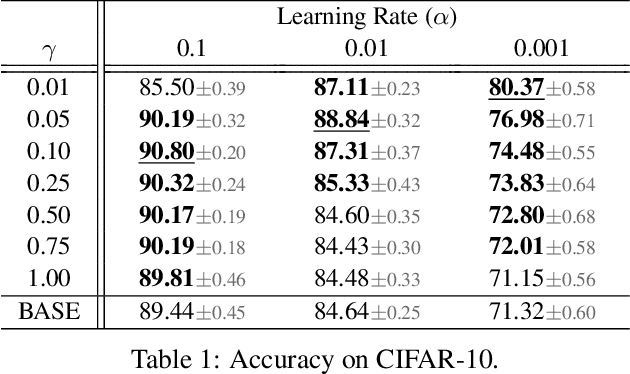
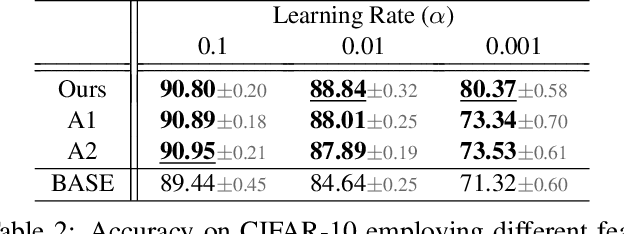
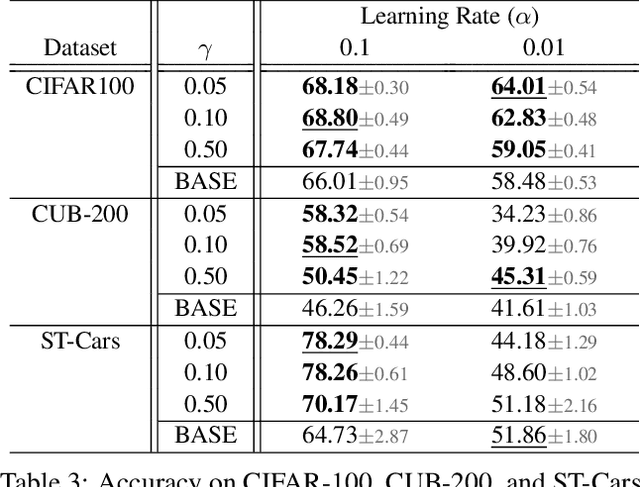
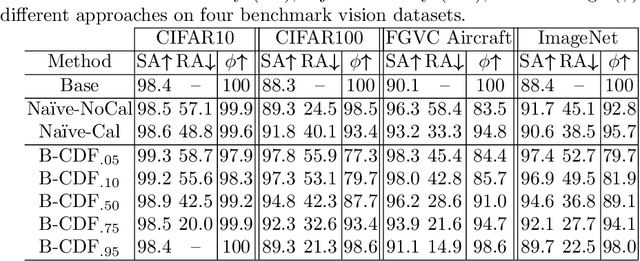
Batch normalization (BN) is comprised of a normalization component followed by an affine transformation and has become essential for training deep neural networks. Standard initialization of each BN in a network sets the affine transformation scale and shift to 1 and 0, respectively. However, after training we have observed that these parameters do not alter much from their initialization. Furthermore, we have noticed that the normalization process can still yield overly large values, which is undesirable for training. We revisit the BN formulation and present a new initialization method and update approach for BN to address the aforementioned issues. Experimental results using the proposed alterations to BN show statistically significant performance gains in a variety of scenarios. The approach can be used with existing implementations at no additional computational cost. We also present a new online BN-based input data normalization technique to alleviate the need for other offline or fixed methods. Source code is available at https://github.com/osu-cvl/revisiting-bn.
Bottom-up Hierarchical Classification Using Confusion-based Logit Compression
Oct 05, 2021



In this work, we propose a method to efficiently compute label posteriors of a base flat classifier in the presence of few validation examples within a bottom-up hierarchical inference framework. A stand-alone validation set (not used to train the base classifier) is preferred for posterior estimation to avoid overfitting the base classifier, however a small validation set limits the number of features one can effectively use. We propose a simple, yet robust, logit vector compression approach based on generalized logits and label confusions for the task of label posterior estimation within the context of hierarchical classification. Extensive comparative experiments with other compression techniques are provided across multiple sized validation sets, and a comparison with related hierarchical classification approaches is also conducted. The proposed approach mitigates the problem of not having enough validation examples for reliable posterior estimation while maintaining strong hierarchical classification performance.