 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Bands to Depth: Understanding Bathymetry Decisions on Sentinel-2
Jan 19, 2026Deploying Sentinel-2 satellite derived bathymetry (SDB) robustly across sites remains challenging. We analyze a Swin-Transformer based U-Net model (Swin-BathyUNet) to understand how it infers depth and when its predictions are trustworthy. A leave-one-band out study ranks spectral importance to the different bands consistent with shallow water optics. We adapt ablation-based CAM to regression (A-CAM-R) and validate the reliability via a performance retention test: keeping only the top-p% salient pixels while neutralizing the rest causes large, monotonic RMSE increase, indicating explanations localize on evidence the model relies on. Attention ablations show decoder conditioned cross attention on skips is an effective upgrade, improving robustness to glint/foam. Cross-region inference (train on one site, test on another) reveals depth-dependent degradation: MAE rises nearly linearly with depth, and bimodal depth distributions exacerbate mid/deep errors. Practical guidance follows: maintain wide receptive fields, preserve radiometric fidelity in green/blue channels, pre-filter bright high variance near shore, and pair light target site fine tuning with depth aware calibration to transfer across regions.
Enhancing Self-Training Methods
Jan 18, 2023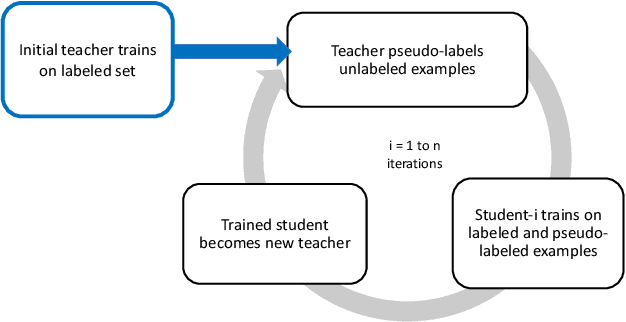

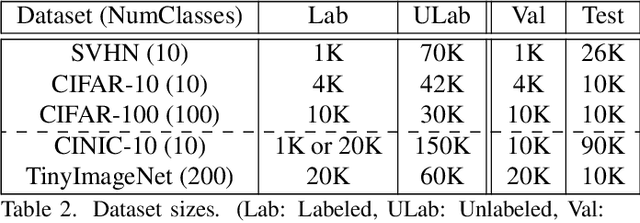
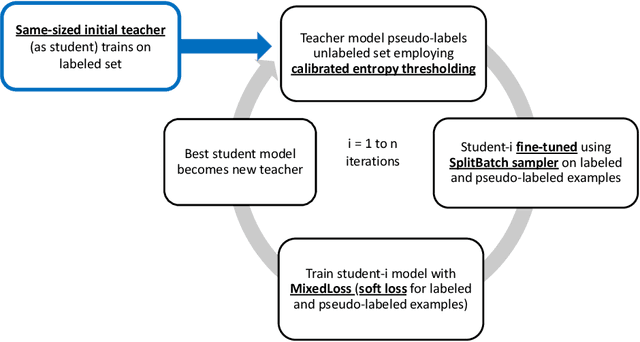
Semi-supervised learning approaches train on small sets of labeled data along with large sets of unlabeled data. Self-training is a semi-supervised teacher-student approach that often suffers from the problem of "confirmation bias" that occurs when the student model repeatedly overfits to incorrect pseudo-labels given by the teacher model for the unlabeled data. This bias impedes improvements in pseudo-label accuracy across self-training iterations, leading to unwanted saturation in model performance after just a few iterations. In this work, we describe multiple enhancements to improve the self-training pipeline to mitigate the effect of confirmation bias. We evaluate our enhancements over multiple datasets showing performance gains over existing self-training design choices. Finally, we also study the extendability of our enhanced approach to Open Set unlabeled data (containing classes not seen in labeled data).