 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Self-Training Methods
Paper and Code
Jan 18, 2023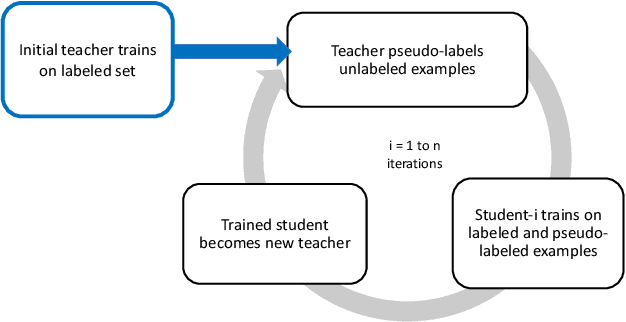

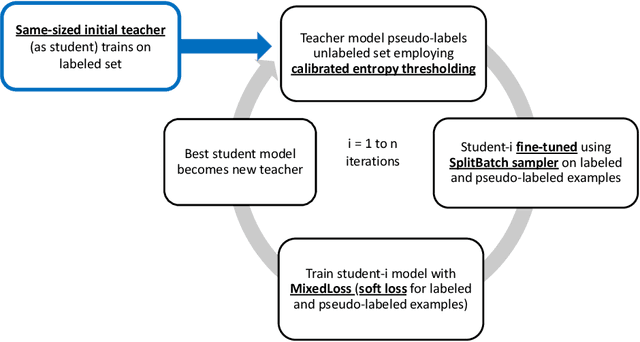
Semi-supervised learning approaches train on small sets of labeled data along with large sets of unlabeled data. Self-training is a semi-supervised teacher-student approach that often suffers from the problem of "confirmation bias" that occurs when the student model repeatedly overfits to incorrect pseudo-labels given by the teacher model for the unlabeled data. This bias impedes improvements in pseudo-label accuracy across self-training iterations, leading to unwanted saturation in model performance after just a few iterations. In this work, we describe multiple enhancements to improve the self-training pipeline to mitigate the effect of confirmation bias. We evaluate our enhancements over multiple datasets showing performance gains over existing self-training design choices. Finally, we also study the extendability of our enhanced approach to Open Set unlabeled data (containing classes not seen in labeled data).