 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORAL: Scalable Multi-Task Robot Learning via LoRA Experts
Mar 10, 2026Deploying Vision-Language-Action (VLA) models in real-world robotics exposes a core multi-task learning challenge: reconciling task interference in multi-task robotic learning. When multiple tasks are jointly fine-tuned in a single stage, gradients from different tasks can conflict, causing negative transfer and reducing per-task performance. Yet maintaining a separate full checkpoint per task is often storage- and deployment-prohibitive. To address this dilemma, we present CORAL, a backbone- and embodiment-agnostic framework designed primarily to mitigate multi-task interference while remaining naturally extensible to a continuous stream of new tasks. CORAL freezes a single pre-trained VLA backbone and attaches one lightweight Low-Rank Adaptation (LoRA) expert per task; at runtime, a dynamic inference engine (the CORAL Manager) routes language instructions to the appropriate expert and swaps experts on the fly with zero inference overhead. This strict parameter isolation avoids complex gating networks and prevents parameter-level cross-task interference by construction; as an added capability, it also enables sequentially introducing new tasks without parameter overwriting caused by catastrophic forgetting. We validate CORAL on a real-world Galaxea R1 dual-arm mobile manipulator and three simulation benchmarks (LIBERO, WidowX, Google Robot), where CORAL overcomes fine-grained instructional ambiguity and substantially outperforms joint training, yielding a practical and scalable system for lifelong multi-task robot learning. Website: https://frontierrobo.github.io/CORAL
Parameter-Efficient Fine-Tuning of 3D DDPM for MRI Image Generation Using Tensor Networks
Jul 24, 2025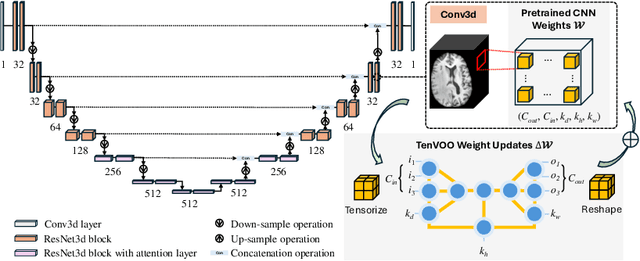

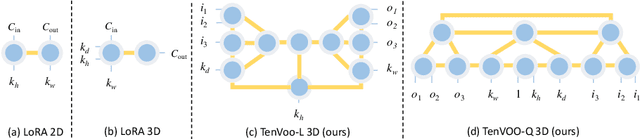

We address the challenge of parameter-efficient fine-tuning (PEFT) for three-dimensional (3D) U-Net-based denoising diffusion probabilistic models (DDPMs) in magnetic resonance imaging (MRI) image generation. Despite its practical significance, research on parameter-efficient representations of 3D convolution operations remains limited. To bridge this gap, we propose Tensor Volumetric Operator (TenVOO), a novel PEFT method specifically designed for fine-tuning DDPMs with 3D convolutional backbones. Leveraging tensor network modeling, TenVOO represents 3D convolution kernels with lower-dimensional tensors, effectively capturing complex spatial dependencies during fine-tuning with few parameters. We evaluate TenVOO on three downstream brain MRI datasets-ADNI, PPMI, and BraTS2021-by fine-tuning a DDPM pretrained on 59,830 T1-weighted brain MRI scans from the UK Biobank. Our results demonstrate that TenVOO achieves state-of-the-art performance in multi-scale structural similarity index measure (MS-SSIM), outperforming existing approaches in capturing spatial dependencies while requiring only 0.3% of the trainable parameters of the original model. Our code is available at: https://github.com/xiaovhua/tenvoo
Making Better Mistakes in CLIP-Based Zero-Shot Classification with Hierarchy-Aware Language Prompts
Mar 04, 2025



Recent studies are leveraging advancements in large language models (LLMs) trained on extensive internet-crawled text data to generate textual descriptions of downstream classes in CLIP-based zero-shot image classification. While most of these approaches aim at improving accuracy, our work focuses on ``making better mistakes", of which the mistakes' severities are derived from the given label hierarchy of downstream tasks. Since CLIP's image encoder is trained with language supervising signals, it implicitly captures the hierarchical semantic relationships between different classes. This motivates our goal of making better mistakes in zero-shot classification, a task for which CLIP is naturally well-suited. Our approach (HAPrompts) queries the language model to produce textual representations for given classes as zero-shot classifiers of CLIP to perform image classification on downstream tasks. To our knowledge, this is the first work to introduce making better mistakes in CLIP-based zero-shot classification. Our approach outperforms the related methods in a holistic comparison across five datasets of varying scales with label hierarchies of different heights in our experiments. Our code and LLM-generated image prompts: \href{https://github.com/ltong1130ztr/HAPrompts}{https://github.com/ltong1130ztr/HAPrompts}.
Inducing Neural Collapse to a Fixed Hierarchy-Aware Frame for Reducing Mistake Severity
Mar 10, 2023



There is a recently discovered and intriguing phenomenon called Neural Collapse: at the terminal phase of training a deep neural network for classification, the within-class penultimate feature means and the associated classifier vectors of all flat classes collapse to the vertices of a simplex Equiangular Tight Frame (ETF). Recent work has tried to exploit this phenomenon by fixing the related classifier weights to a pre-computed ETF to induce neural collapse and maximize the separation of the learned features when training with imbalanced data. In this work, we propose to fix the linear classifier of a deep neural network to a Hierarchy-Aware Frame (HAFrame), instead of an ETF, and use a cosine similarity-based auxiliary loss to learn hierarchy-aware penultimate features that collapse to the HAFrame. We demonstrate that our approach reduces the mistake severity of the model's predictions while maintaining its top-1 accuracy on several datasets of varying scales with hierarchies of heights ranging from 3 to 12. We will release our code on GitHub in the near future.
Bottom-up Hierarchical Classification Using Confusion-based Logit Compression
Oct 05, 2021



In this work, we propose a method to efficiently compute label posteriors of a base flat classifier in the presence of few validation examples within a bottom-up hierarchical inference framework. A stand-alone validation set (not used to train the base classifier) is preferred for posterior estimation to avoid overfitting the base classifier, however a small validation set limits the number of features one can effectively use. We propose a simple, yet robust, logit vector compression approach based on generalized logits and label confusions for the task of label posterior estimation within the context of hierarchical classification. Extensive comparative experiments with other compression techniques are provided across multiple sized validation sets, and a comparison with related hierarchical classification approaches is also conducted. The proposed approach mitigates the problem of not having enough validation examples for reliable posterior estimation while maintaining strong hierarchical classification performance.