 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Revisit of Temperature in Classification-Based Knowledge Distillation
Mar 04, 2026A central idea of knowledge distillation is to expose relational structure embedded in the teacher's weights for the student to learn, which is often facilitated using a temperature parameter. Despite its widespread use, there remains limited understanding on how to select an appropriate temperature value, or how this value depends on other training elements such as optimizer, teacher pretraining/finetuning, etc. In practice, temperature is commonly chosen via grid search or by adopting values from prior work, which can be time-consuming or may lead to suboptimal student performance when training setups differ. In this work, we posit that temperature is closely linked to these training components and present a unified study that systematically examines such interactions. From analyzing these cross-connections, we identify and present common situations that have a pronounced impact on temperature selection, providing valuable guidance for practitioners employing knowledge distillation in their work.
What Makes a Good Dataset for Knowledge Distillation?
Nov 19, 2024



Knowledge distillation (KD) has been a popular and effective method for model compression. One important assumption of KD is that the teacher's original dataset will also be available when training the student. However, in situations such as continual learning and distilling large models trained on company-withheld datasets, having access to the original data may not always be possible. This leads practitioners towards utilizing other sources of supplemental data, which could yield mixed results. One must then ask: "what makes a good dataset for transferring knowledge from teacher to student?" Many would assume that only real in-domain imagery is viable, but is that the only option? In this work, we explore multiple possible surrogate distillation datasets and demonstrate that many different datasets, even unnatural synthetic imagery, can serve as a suitable alternative in KD. From examining these alternative datasets, we identify and present various criteria describing what makes a good dataset for distillation. Source code will be available in the future.
Deep Learning Improvements for Sparse Spatial Field Reconstruction
Aug 22, 2024Accurately reconstructing a global spatial field from sparse data has been a longstanding problem in several domains, such as Earth Sciences and Fluid Dynamics. Historically, scientists have approached this problem by employing complex physics models to reconstruct the spatial fields. However, these methods are often computationally intensive. With the increase in popularity of machine learning (ML), several researchers have applied ML to the spatial field reconstruction task and observed improvements in computational efficiency. One such method in arXiv:2101.00554 utilizes a sparse mask of sensor locations and a Voronoi tessellation with sensor measurements as inputs to a convolutional neural network for reconstructing the global spatial field. In this work, we propose multiple adjustments to the aforementioned approach and show improvements on geoscience and fluid dynamics simulation datasets. We identify and discuss scenarios that benefit the most using the proposed ML-based spatial field reconstruction approach.
Data-Free Knowledge Distillation Using Adversarially Perturbed OpenGL Shader Images
Oct 20, 2023



Knowledge distillation (KD) has been a popular and effective method for model compression. One important assumption of KD is that the original training dataset is always available. However, this is not always the case due to privacy concerns and more. In recent years, "data-free" KD has emerged as a growing research topic which focuses on the scenario of performing KD when no data is provided. Many methods rely on a generator network to synthesize examples for distillation (which can be difficult to train) and can frequently produce images that are visually similar to the original dataset, which raises questions surrounding whether privacy is completely preserved. In this work, we propose a new approach to data-free KD that utilizes unnatural OpenGL images, combined with large amounts of data augmentation and adversarial attacks, to train a student network. We demonstrate that our approach achieves state-of-the-art results for a variety of datasets/networks and is more stable than existing generator-based data-free KD methods. Source code will be available in the future.
Revisiting Batch Normalization
Oct 26, 2021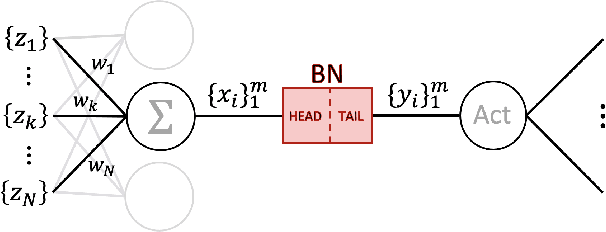
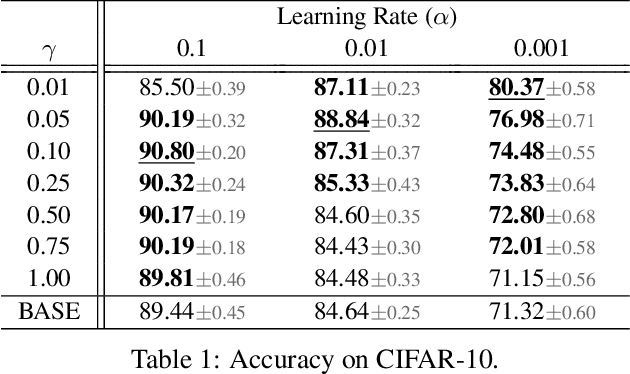
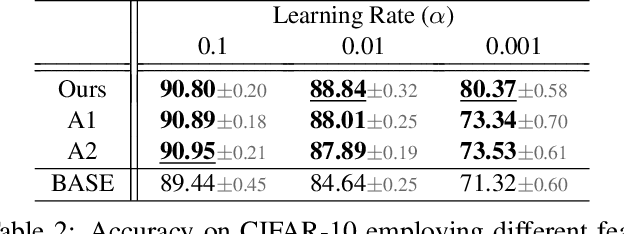
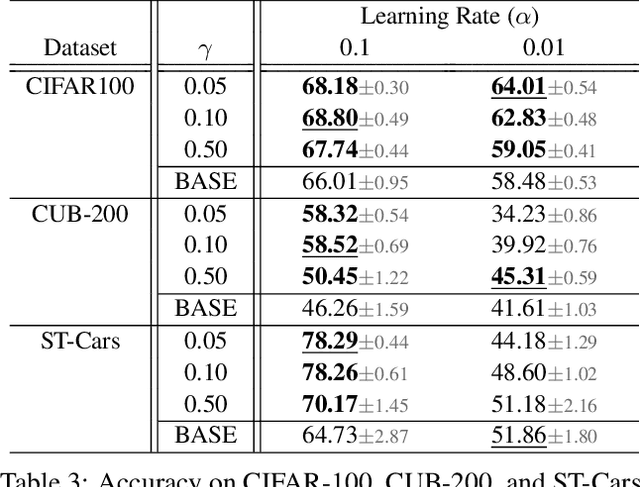
Batch normalization (BN) is comprised of a normalization component followed by an affine transformation and has become essential for training deep neural networks. Standard initialization of each BN in a network sets the affine transformation scale and shift to 1 and 0, respectively. However, after training we have observed that these parameters do not alter much from their initialization. Furthermore, we have noticed that the normalization process can still yield overly large values, which is undesirable for training. We revisit the BN formulation and present a new initialization method and update approach for BN to address the aforementioned issues. Experimental results using the proposed alterations to BN show statistically significant performance gains in a variety of scenarios. The approach can be used with existing implementations at no additional computational cost. We also present a new online BN-based input data normalization technique to alleviate the need for other offline or fixed methods. Source code is available at https://github.com/osu-cvl/revisiting-bn.