 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuCLIRTech: Chinese Monolingual and Cross-Language Information Retrieval Evaluation in a Challenging Domain
Feb 05, 2026Measuring advances in retrieval requires test collections with relevance judgments that can faithfully distinguish systems. This paper presents NeuCLIRTech, an evaluation collection for cross-language retrieval over technical information. The collection consists of technical documents written natively in Chinese and those same documents machine translated into English. It includes 110 queries with relevance judgments. The collection supports two retrieval scenarios: monolingual retrieval in Chinese, and cross-language retrieval with English as the query language. NeuCLIRTech combines the TREC NeuCLIR track topics of 2023 and 2024. The 110 queries with 35,962 document judgments provide strong statistical discriminatory power when trying to distinguish retrieval approaches. A fusion baseline of strong neural retrieval systems is included so that developers of reranking algorithms are not reliant on BM25 as their first stage retriever. The dataset and artifacts are released on Huggingface Datasets
Data Kernel Perspective Space Performance Guarantees for Synthetic Data from Transformer Models
Feb 04, 2026Scarcity of labeled training data remains the long pole in the tent for building performant language technology and generative AI models. Transformer models -- particularly LLMs -- are increasingly being used to mitigate the data scarcity problem via synthetic data generation. However, because the models are black boxes, the properties of the synthetic data are difficult to predict. In practice it is common for language technology engineers to 'fiddle' with the LLM temperature setting and hope that what comes out the other end improves the downstream model. Faced with this uncertainty, here we propose Data Kernel Perspective Space (DKPS) to provide the foundation for mathematical analysis yielding concrete statistical guarantees for the quality of the outputs of transformer models. We first show the mathematical derivation of DKPS and how it provides performance guarantees. Next we show how DKPS performance guarantees can elucidate performance of a downstream task, such as neural machine translation models or LLMs trained using Contrastive Preference Optimization (CPO). Limitations of the current work and future research are also discussed.
NeuCLIRBench: A Modern Evaluation Collection for Monolingual, Cross-Language, and Multilingual Information Retrieval
Nov 18, 2025

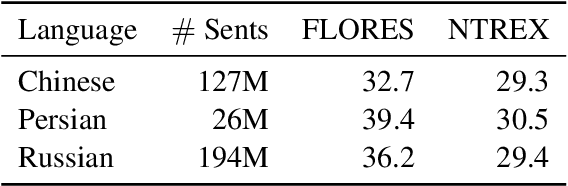
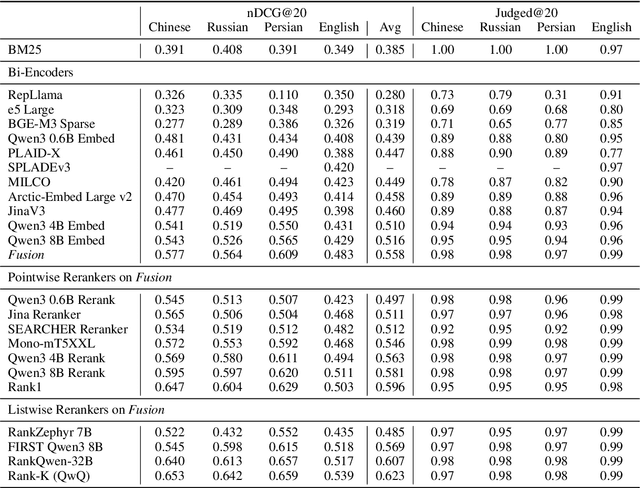
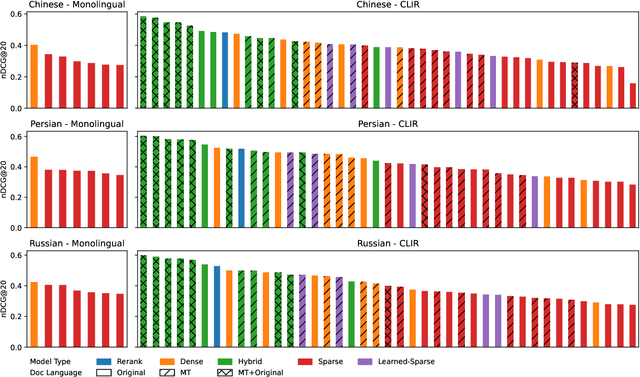
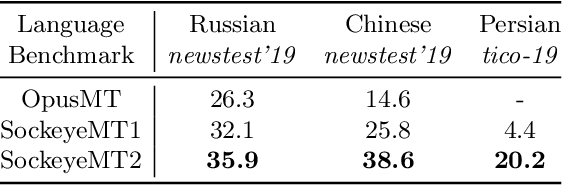
To measure advances in retrieval, test collections with relevance judgments that can faithfully distinguish systems are required. This paper presents NeuCLIRBench, an evaluation collection for cross-language and multilingual retrieval. The collection consists of documents written natively in Chinese, Persian, and Russian, as well as those same documents machine translated into English. The collection supports several retrieval scenarios including: monolingual retrieval in English, Chinese, Persian, or Russian; cross-language retrieval with English as the query language and one of the other three languages as the document language; and multilingual retrieval, again with English as the query language and relevant documents in all three languages. NeuCLIRBench combines the TREC NeuCLIR track topics of 2022, 2023, and 2024. The 250,128 judgments across approximately 150 queries for the monolingual and cross-language tasks and 100 queries for multilingual retrieval provide strong statistical discriminatory power to distinguish retrieval approaches. A fusion baseline of strong neural retrieval systems is included with the collection so that developers of reranking algorithms are no longer reliant on BM25 as their first-stage retriever. NeuCLIRBench is publicly available.
Linguistic Nepotism: Trading-off Quality for Language Preference in Multilingual RAG
Sep 17, 2025Multilingual Retrieval-Augmented Generation (mRAG) systems enable language models to answer knowledge-intensive queries with citation-supported responses across languages. While such systems have been proposed, an open questions is whether the mixture of different document languages impacts generation and citation in unintended ways. To investigate, we introduce a controlled methodology using model internals to measure language preference while holding other factors such as document relevance constant. Across eight languages and six open-weight models, we find that models preferentially cite English sources when queries are in English, with this bias amplified for lower-resource languages and for documents positioned mid-context. Crucially, we find that models sometimes trade-off document relevance for language preference, indicating that citation choices are not always driven by informativeness alone. Our findings shed light on how language models leverage multilingual context and influence citation behavior.
Overview of the TREC 2024 NeuCLIR Track
Sep 17, 2025The principal goal of the TREC Neural Cross-Language Information Retrieval (NeuCLIR) track is to study the effect of neural approaches on cross-language information access. The track has created test collections containing Chinese, Persian, and Russian news stories and Chinese academic abstracts. NeuCLIR includes four task types: Cross-Language Information Retrieval (CLIR) from news, Multilingual Information Retrieval (MLIR) from news, Report Generation from news, and CLIR from technical documents. A total of 274 runs were submitted by five participating teams (and as baselines by the track coordinators) for eight tasks across these four task types. Task descriptions and the available results are presented.
On the Evaluation of Machine-Generated Reports
May 02, 2024



Large Language Models (LLMs) have enabled new ways to satisfy information needs. Although great strides have been made in applying them to settings like document ranking and short-form text generation, they still struggle to compose complete, accurate, and verifiable long-form reports. Reports with these qualities are necessary to satisfy the complex, nuanced, or multi-faceted information needs of users. In this perspective paper, we draw together opinions from industry and academia, and from a variety of related research areas, to present our vision for automatic report generation, and -- critically -- a flexible framework by which such reports can be evaluated. In contrast with other summarization tasks, automatic report generation starts with a detailed description of an information need, stating the necessary background, requirements, and scope of the report. Further, the generated reports should be complete, accurate, and verifiable. These qualities, which are desirable -- if not required -- in many analytic report-writing settings, require rethinking how to build and evaluate systems that exhibit these qualities. To foster new efforts in building these systems, we present an evaluation framework that draws on ideas found in various evaluations. To test completeness and accuracy, the framework uses nuggets of information, expressed as questions and answers, that need to be part of any high-quality generated report. Additionally, evaluation of citations that map claims made in the report to their source documents ensures verifiability.
Extending Translate-Train for ColBERT-X to African Language CLIR
Apr 11, 2024



This paper describes the submission runs from the HLTCOE team at the CIRAL CLIR tasks for African languages at FIRE 2023. Our submissions use machine translation models to translate the documents and the training passages, and ColBERT-X as the retrieval model. Additionally, we present a set of unofficial runs that use an alternative training procedure with a similar training setting.
Overview of the TREC 2023 NeuCLIR Track
Apr 11, 2024
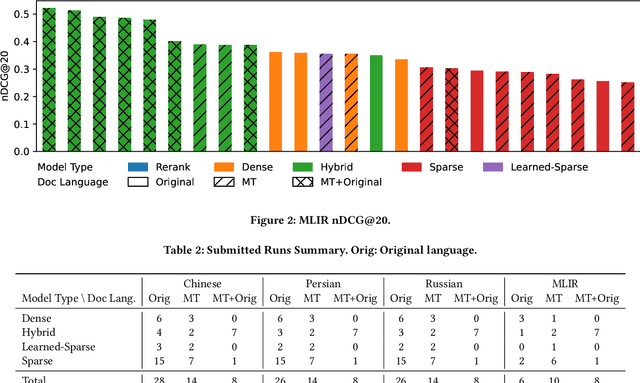
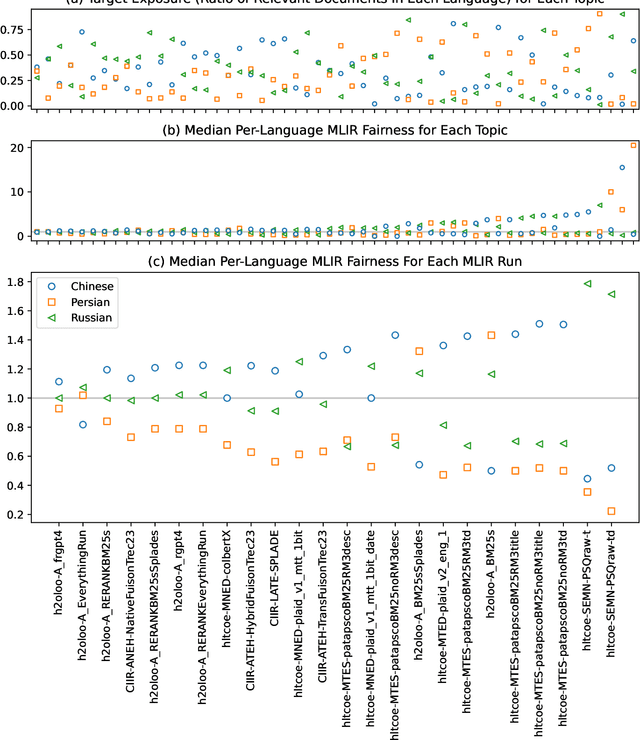
The principal goal of the TREC Neural Cross-Language Information Retrieval (NeuCLIR) track is to study the impact of neural approaches to cross-language information retrieval. The track has created four collections, large collections of Chinese, Persian, and Russian newswire and a smaller collection of Chinese scientific abstracts. The principal tasks are ranked retrieval of news in one of the three languages, using English topics. Results for a multilingual task, also with English topics but with documents from all three newswire collections, are also reported. New in this second year of the track is a pilot technical documents CLIR task for ranked retrieval of Chinese technical documents using English topics. A total of 220 runs across all tasks were submitted by six participating teams and, as baselines, by track coordinators. Task descriptions and results are presented.
Overview of the TREC 2022 NeuCLIR Track
Apr 24, 2023
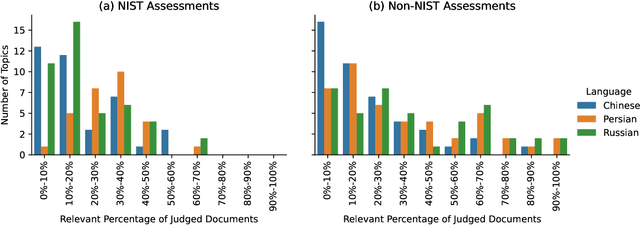
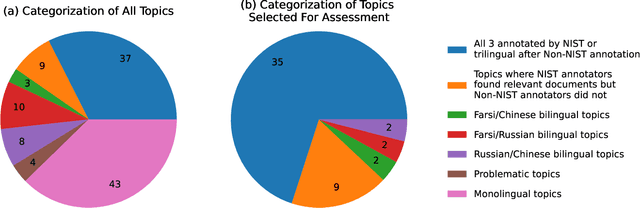
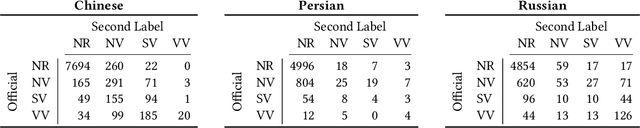
This is the first year of the TREC Neural CLIR (NeuCLIR) track, which aims to study the impact of neural approaches to cross-language information retrieval. The main task in this year's track was ad hoc ranked retrieval of Chinese, Persian, or Russian newswire documents using queries expressed in English. Topics were developed using standard TREC processes, except that topics developed by an annotator for one language were assessed by a different annotator when evaluating that topic on a different language. There were 172 total runs submitted by twelve teams.
Transfer Learning Approaches for Building Cross-Language Dense Retrieval Models
Jan 20, 2022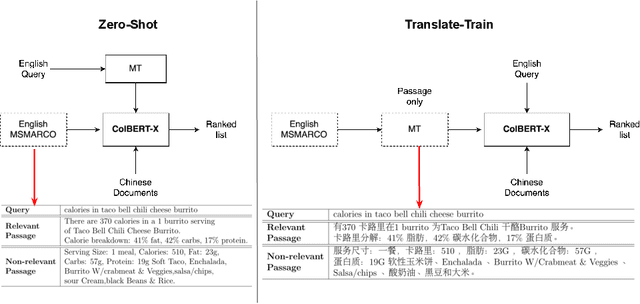
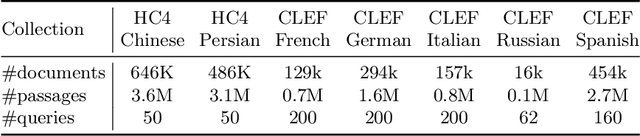
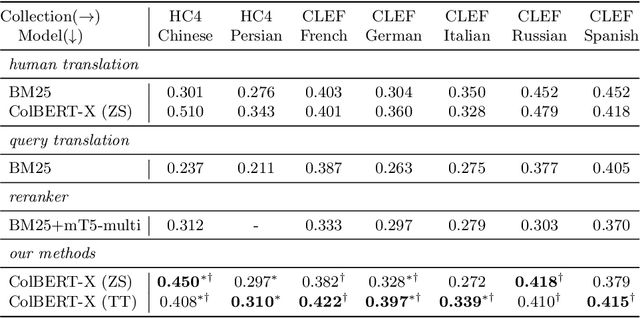
The advent of transformer-based models such as BERT has led to the rise of neural ranking models. These models have improved the effectiveness of retrieval systems well beyond that of lexical term matching models such as BM25. While monolingual retrieval tasks have benefited from large-scale training collections such as MS MARCO and advances in neural architectures, cross-language retrieval tasks have fallen behind these advancements. This paper introduces ColBERT-X, a generalization of the ColBERT multi-representation dense retrieval model that uses the XLM-RoBERTa (XLM-R) encoder to support cross-language information retrieval (CLIR). ColBERT-X can be trained in two ways. In zero-shot training, the system is trained on the English MS MARCO collection, relying on the XLM-R encoder for cross-language mappings. In translate-train, the system is trained on the MS MARCO English queries coupled with machine translations of the associated MS MARCO passages. Results on ad hoc document ranking tasks in several languages demonstrate substantial and statistically significant improvements of these trained dense retrieval models over traditional lexical CLIR baselines.