 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreezing Subnetworks to Analyze Domain Adaptation in Neural Machine Translation
Sep 14, 2018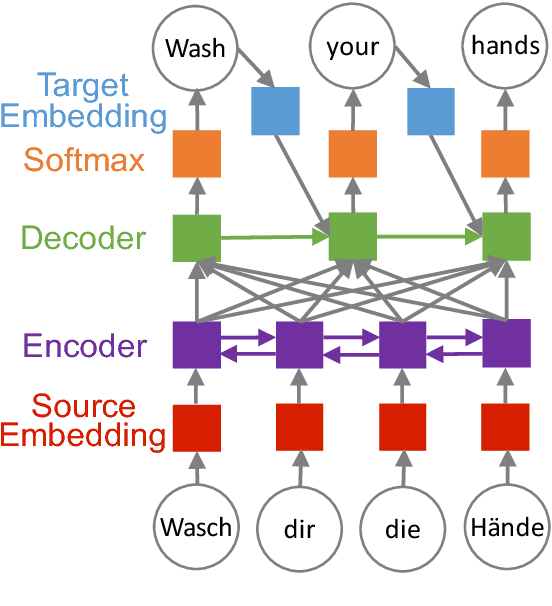
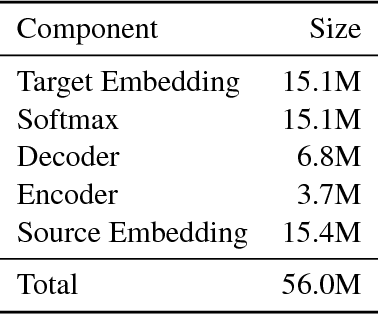
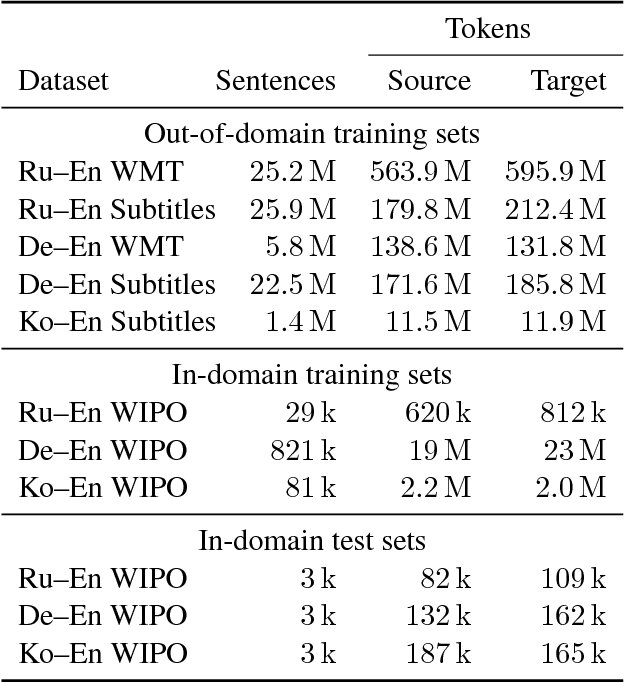
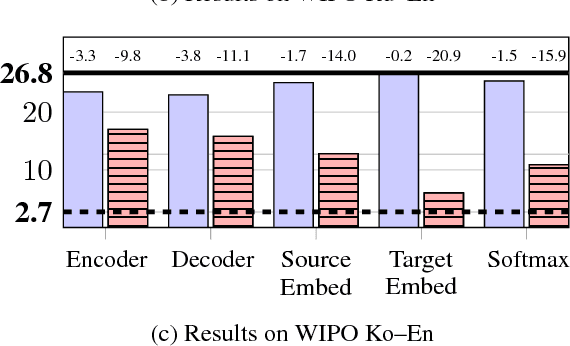
To better understand the effectiveness of continued training, we analyze the major components of a neural machine translation system (the encoder, decoder, and each embedding space) and consider each component's contribution to, and capacity for, domain adaptation. We find that freezing any single component during continued training has minimal impact on performance, and that performance is surprisingly good when a single component is adapted while holding the rest of the model fixed. We also find that continued training does not move the model very far from the out-of-domain model, compared to a sensitivity analysis metric, suggesting that the out-of-domain model can provide a good generic initialization for the new domain.
Targeted Syntactic Evaluation of Language Models
Aug 27, 2018
We present a dataset for evaluating the grammaticality of the predictions of a language model. We automatically construct a large number of minimally different pairs of English sentences, each consisting of a grammatical and an ungrammatical sentence. The sentence pairs represent different variations of structure-sensitive phenomena: subject-verb agreement, reflexive anaphora and negative polarity items. We expect a language model to assign a higher probability to the grammatical sentence than the ungrammatical one. In an experiment using this data set, an LSTM language model performed poorly on many of the constructions. Multi-task training with a syntactic objective (CCG supertagging) improved the LSTM's accuracy, but a large gap remained between its performance and the accuracy of human participants recruited online. This suggests that there is considerable room for improvement over LSTMs in capturing syntax in a language model.