 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Improving Statistical Significance in Human Evaluation of Automatic Metrics via Soft Pairwise Accuracy
Sep 15, 2024



Selecting an automatic metric that best emulates human judgments is often non-trivial, because there is no clear definition of "best emulates." A meta-metric is required to compare the human judgments to the automatic metric judgments, and metric rankings depend on the choice of meta-metric. We propose Soft Pairwise Accuracy (SPA), a new meta-metric that builds on Pairwise Accuracy (PA) but incorporates the statistical significance of both the human judgments and the metric judgments. SPA allows for more fine-grained comparisons between systems than a simplistic binary win/loss, and addresses a number of shortcomings with PA: it is more stable with respect to both the number of systems and segments used for evaluation, it mitigates the issue of metric ties due to quantization, and it produces more statistically significant results. SPA was selected as the official system-level metric for the 2024 WMT metric shared task.
Fine-Tuned Machine Translation Metrics Struggle in Unseen Domains
Feb 28, 2024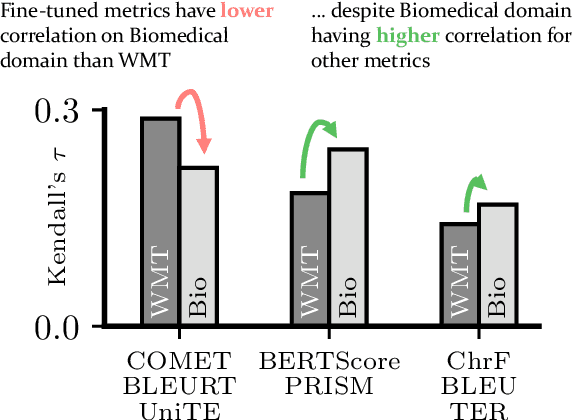
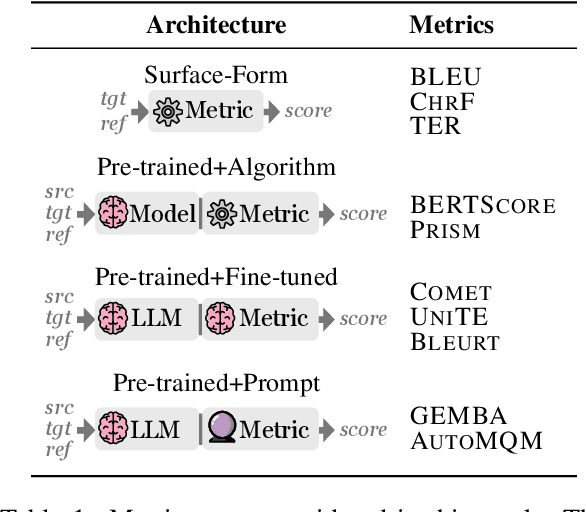
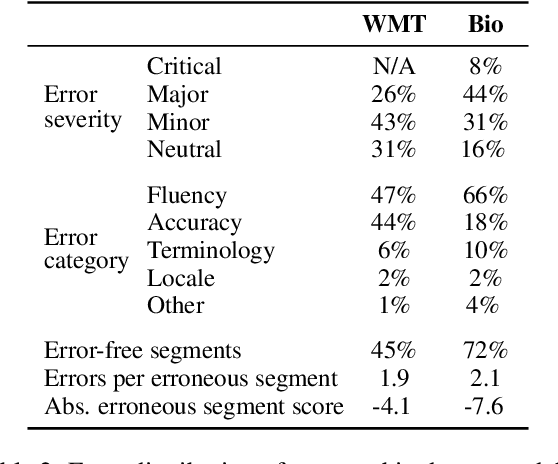
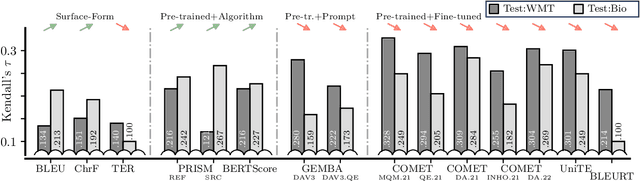
We introduce a new, extensive multidimensional quality metrics (MQM) annotated dataset covering 11 language pairs in the biomedical domain. We use this dataset to investigate whether machine translation (MT) metrics which are fine-tuned on human-generated MT quality judgements are robust to domain shifts between training and inference. We find that fine-tuned metrics exhibit a substantial performance drop in the unseen domain scenario relative to metrics that rely on the surface form, as well as pre-trained metrics which are not fine-tuned on MT quality judgments.
A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism
Jan 11, 2024
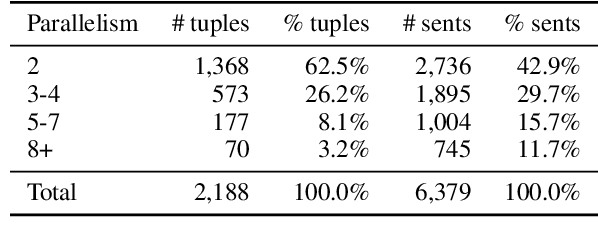
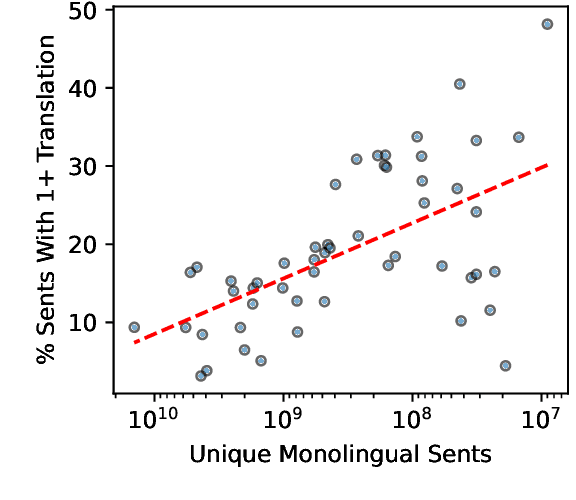

We show that content on the web is often translated into many languages, and the low quality of these multi-way translations indicates they were likely created using Machine Translation (MT). Multi-way parallel, machine generated content not only dominates the translations in lower resource languages; it also constitutes a large fraction of the total web content in those languages. We also find evidence of a selection bias in the type of content which is translated into many languages, consistent with low quality English content being translated en masse into many lower resource languages, via MT. Our work raises serious concerns about training models such as multilingual large language models on both monolingual and bilingual data scraped from the web.
End-to-End Single-Channel Speaker-Turn Aware Conversational Speech Translation
Nov 01, 2023



Conventional speech-to-text translation (ST) systems are trained on single-speaker utterances, and they may not generalize to real-life scenarios where the audio contains conversations by multiple speakers. In this paper, we tackle single-channel multi-speaker conversational ST with an end-to-end and multi-task training model, named Speaker-Turn Aware Conversational Speech Translation, that combines automatic speech recognition, speech translation and speaker turn detection using special tokens in a serialized labeling format. We run experiments on the Fisher-CALLHOME corpus, which we adapted by merging the two single-speaker channels into one multi-speaker channel, thus representing the more realistic and challenging scenario with multi-speaker turns and cross-talk. Experimental results across single- and multi-speaker conditions and against conventional ST systems, show that our model outperforms the reference systems on the multi-speaker condition, while attaining comparable performance on the single-speaker condition. We release scripts for data processing and model training.
Speaker Diarization of Scripted Audiovisual Content
Aug 04, 2023

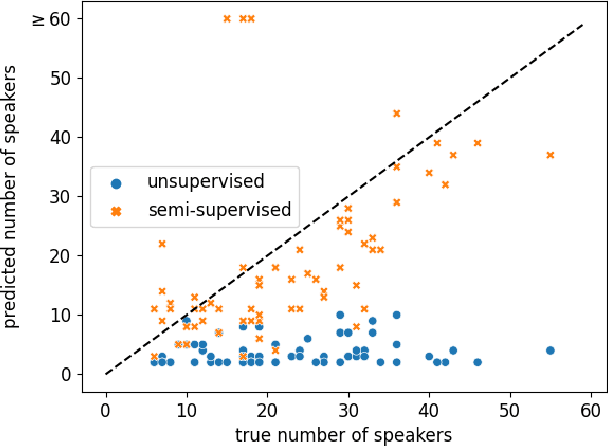
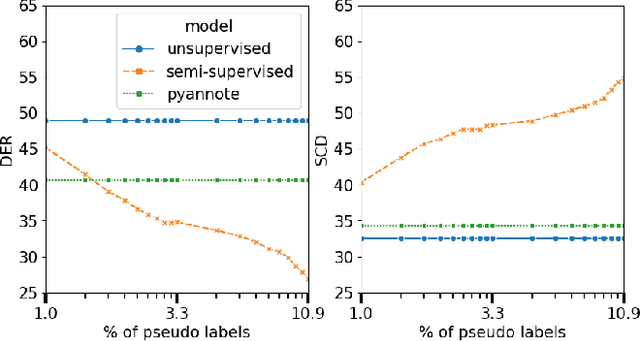
The media localization industry usually requires a verbatim script of the final film or TV production in order to create subtitles or dubbing scripts in a foreign language. In particular, the verbatim script (i.e. as-broadcast script) must be structured into a sequence of dialogue lines each including time codes, speaker name and transcript. Current speech recognition technology alleviates the transcription step. However, state-of-the-art speaker diarization models still fall short on TV shows for two main reasons: (i) their inability to track a large number of speakers, (ii) their low accuracy in detecting frequent speaker changes. To mitigate this problem, we present a novel approach to leverage production scripts used during the shooting process, to extract pseudo-labeled data for the speaker diarization task. We propose a novel semi-supervised approach and demonstrate improvements of 51.7% relative to two unsupervised baseline models on our metrics on a 66 show test set.
Improving Isochronous Machine Translation with Target Factors and Auxiliary Counters
May 22, 2023



To translate speech for automatic dubbing, machine translation needs to be isochronous, i.e. translated speech needs to be aligned with the source in terms of speech durations. We introduce target factors in a transformer model to predict durations jointly with target language phoneme sequences. We also introduce auxiliary counters to help the decoder to keep track of the timing information while generating target phonemes. We show that our model improves translation quality and isochrony compared to previous work where the translation model is instead trained to predict interleaved sequences of phonemes and durations.
Jointly Optimizing Translations and Speech Timing to Improve Isochrony in Automatic Dubbing
Feb 25, 2023



Automatic dubbing (AD) is the task of translating the original speech in a video into target language speech. The new target language speech should satisfy isochrony; that is, the new speech should be time aligned with the original video, including mouth movements, pauses, hand gestures, etc. In this paper, we propose training a model that directly optimizes both the translation as well as the speech duration of the generated translations. We show that this system generates speech that better matches the timing of the original speech, compared to prior work, while simplifying the system architecture.
Dubbing in Practice: A Large Scale Study of Human Localization With Insights for Automatic Dubbing
Dec 23, 2022We investigate how humans perform the task of dubbing video content from one language into another, leveraging a novel corpus of 319.57 hours of video from 54 professionally produced titles. This is the first such large-scale study we are aware of. The results challenge a number of assumptions commonly made in both qualitative literature on human dubbing and machine-learning literature on automatic dubbing, arguing for the importance of vocal naturalness and translation quality over commonly emphasized isometric (character length) and lip-sync constraints, and for a more qualified view of the importance of isochronic (timing) constraints. We also find substantial influence of the source-side audio on human dubs through channels other than the words of the translation, pointing to the need for research on ways to preserve speech characteristics, as well as semantic transfer such as emphasis/emotion, in automatic dubbing systems.
Improving Robustness of Retrieval Augmented Translation via Shuffling of Suggestions
Oct 11, 2022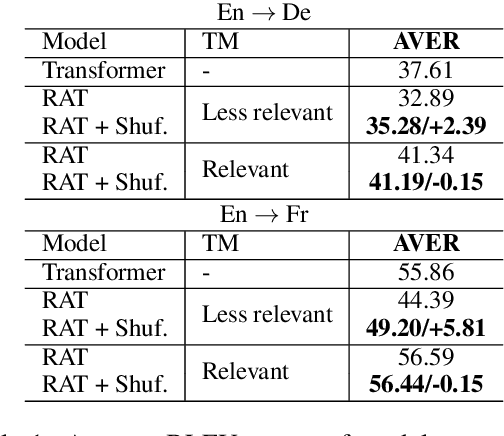
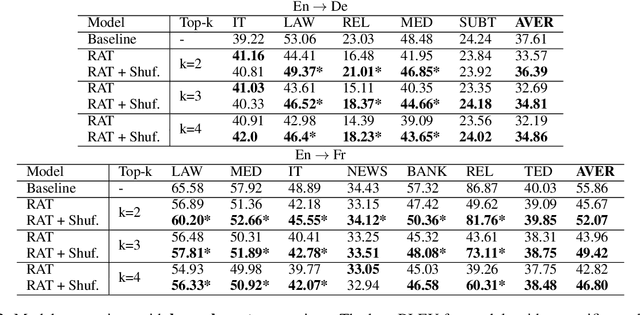
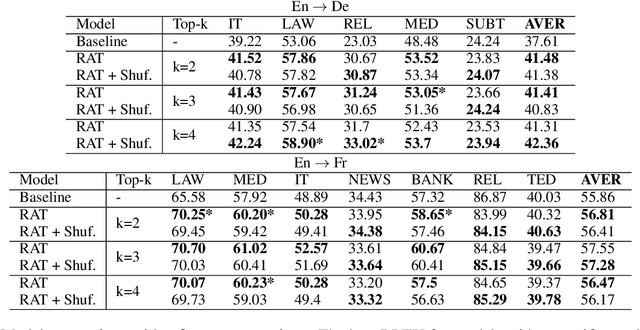

Several recent studies have reported dramatic performance improvements in neural machine translation (NMT) by augmenting translation at inference time with fuzzy-matches retrieved from a translation memory (TM). However, these studies all operate under the assumption that the TMs available at test time are highly relevant to the testset. We demonstrate that for existing retrieval augmented translation methods, using a TM with a domain mismatch to the test set can result in substantially worse performance compared to not using a TM at all. We propose a simple method to expose fuzzy-match NMT systems during training and show that it results in a system that is much more tolerant (regaining up to 5.8 BLEU) to inference with TMs with domain mismatch. Also, the model is still competitive to the baseline when fed with suggestions from relevant TMs.