 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Statistical Significance in Human Evaluation of Automatic Metrics via Soft Pairwise Accuracy
Sep 15, 2024



Selecting an automatic metric that best emulates human judgments is often non-trivial, because there is no clear definition of "best emulates." A meta-metric is required to compare the human judgments to the automatic metric judgments, and metric rankings depend on the choice of meta-metric. We propose Soft Pairwise Accuracy (SPA), a new meta-metric that builds on Pairwise Accuracy (PA) but incorporates the statistical significance of both the human judgments and the metric judgments. SPA allows for more fine-grained comparisons between systems than a simplistic binary win/loss, and addresses a number of shortcomings with PA: it is more stable with respect to both the number of systems and segments used for evaluation, it mitigates the issue of metric ties due to quantization, and it produces more statistically significant results. SPA was selected as the official system-level metric for the 2024 WMT metric shared task.
Tangled up in BLEU: Reevaluating the Evaluation of Automatic Machine Translation Evaluation Metrics
Jun 12, 2020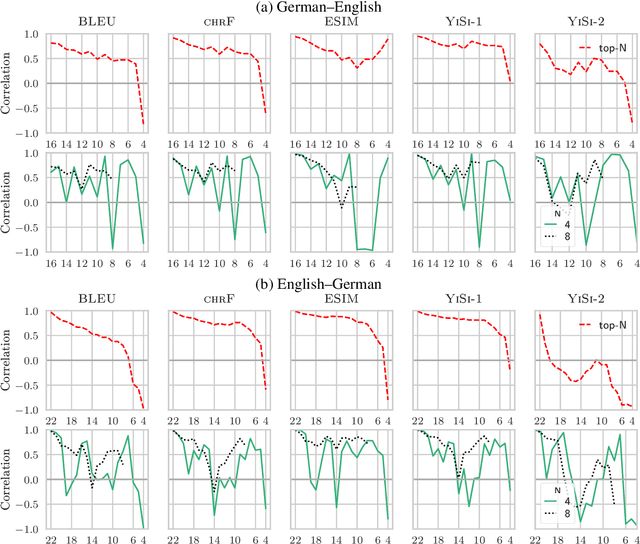
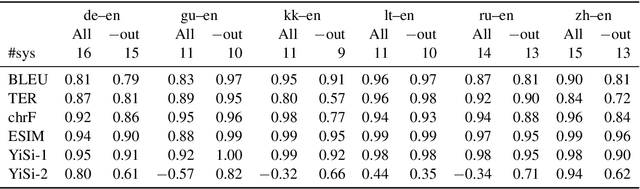

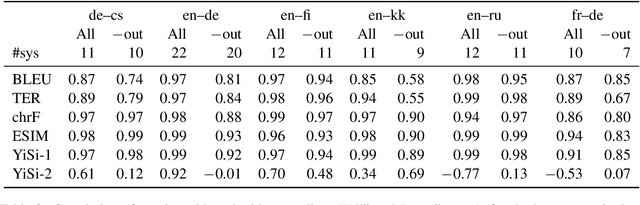
Automatic metrics are fundamental for the development and evaluation of machine translation systems. Judging whether, and to what extent, automatic metrics concur with the gold standard of human evaluation is not a straightforward problem. We show that current methods for judging metrics are highly sensitive to the translations used for assessment, particularly the presence of outliers, which often leads to falsely confident conclusions about a metric's efficacy. Finally, we turn to pairwise system ranking, developing a method for thresholding performance improvement under an automatic metric against human judgements, which allows quantification of type I versus type II errors incurred, i.e., insignificant human differences in system quality that are accepted, and significant human differences that are rejected. Together, these findings suggest improvements to the protocols for metric evaluation and system performance evaluation in machine translation.