 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Security Beyond Core Domains: Resume Screening as a Case Study of Adversarial Vulnerabilities in Specialized LLM Applications
Dec 23, 2025



Large Language Models (LLMs) excel at text comprehension and generation, making them ideal for automated tasks like code review and content moderation. However, our research identifies a vulnerability: LLMs can be manipulated by "adversarial instructions" hidden in input data, such as resumes or code, causing them to deviate from their intended task. Notably, while defenses may exist for mature domains such as code review, they are often absent in other common applications such as resume screening and peer review. This paper introduces a benchmark to assess this vulnerability in resume screening, revealing attack success rates exceeding 80% for certain attack types. We evaluate two defense mechanisms: prompt-based defenses achieve 10.1% attack reduction with 12.5% false rejection increase, while our proposed FIDS (Foreign Instruction Detection through Separation) using LoRA adaptation achieves 15.4% attack reduction with 10.4% false rejection increase. The combined approach provides 26.3% attack reduction, demonstrating that training-time defenses outperform inference-time mitigations in both security and utility preservation.
Reasoning with Confidence: Efficient Verification of LLM Reasoning Steps via Uncertainty Heads
Nov 11, 2025Solving complex tasks usually requires LLMs to generate long multi-step reasoning chains. Previous work has shown that verifying the correctness of individual reasoning steps can further improve the performance and efficiency of LLMs on such tasks and enhance solution interpretability. However, existing verification approaches, such as Process Reward Models (PRMs), are either computationally expensive, limited to specific domains, or require large-scale human or model-generated annotations. Thus, we propose a lightweight alternative for step-level reasoning verification based on data-driven uncertainty scores. We train transformer-based uncertainty quantification heads (UHeads) that use the internal states of a frozen LLM to estimate the uncertainty of its reasoning steps during generation. The approach is fully automatic: target labels are generated either by another larger LLM (e.g., DeepSeek R1) or in a self-supervised manner by the original model itself. UHeads are both effective and lightweight, containing less than 10M parameters. Across multiple domains, including mathematics, planning, and general knowledge question answering, they match or even surpass the performance of PRMs that are up to 810x larger. Our findings suggest that the internal states of LLMs encode their uncertainty and can serve as reliable signals for reasoning verification, offering a promising direction toward scalable and generalizable introspective LLMs.
Faithfulness-Aware Uncertainty Quantification for Fact-Checking the Output of Retrieval Augmented Generation
May 28, 2025Large Language Models (LLMs) enhanced with external knowledge retrieval, an approach known as Retrieval-Augmented Generation (RAG), have shown strong performance in open-domain question answering. However, RAG systems remain susceptible to hallucinations: factually incorrect outputs that may arise either from inconsistencies in the model's internal knowledge or incorrect use of the retrieved context. Existing approaches often conflate factuality with faithfulness to the retrieved context, misclassifying factually correct statements as hallucinations if they are not directly supported by the retrieval. In this paper, we introduce FRANQ (Faithfulness-based Retrieval Augmented UNcertainty Quantification), a novel method for hallucination detection in RAG outputs. FRANQ applies different Uncertainty Quantification (UQ) techniques to estimate factuality based on whether a statement is faithful to the retrieved context or not. To evaluate FRANQ and other UQ techniques for RAG, we present a new long-form Question Answering (QA) dataset annotated for both factuality and faithfulness, combining automated labeling with manual validation of challenging examples. Extensive experiments on long- and short-form QA across multiple datasets and LLMs show that FRANQ achieves more accurate detection of factual errors in RAG-generated responses compared to existing methods.
Uncertainty-Aware Attention Heads: Efficient Unsupervised Uncertainty Quantification for LLMs
May 26, 2025Large language models (LLMs) exhibit impressive fluency, but often produce critical errors known as "hallucinations". Uncertainty quantification (UQ) methods are a promising tool for coping with this fundamental shortcoming. Yet, existing UQ methods face challenges such as high computational overhead or reliance on supervised learning. Here, we aim to bridge this gap. In particular, we propose RAUQ (Recurrent Attention-based Uncertainty Quantification), an unsupervised approach that leverages intrinsic attention patterns in transformers to detect hallucinations efficiently. By analyzing attention weights, we identified a peculiar pattern: drops in attention to preceding tokens are systematically observed during incorrect generations for certain "uncertainty-aware" heads. RAUQ automatically selects such heads, recurrently aggregates their attention weights and token-level confidences, and computes sequence-level uncertainty scores in a single forward pass. Experiments across 4 LLMs and 12 question answering, summarization, and translation tasks demonstrate that RAUQ yields excellent results, outperforming state-of-the-art UQ methods using minimal computational overhead (<1% latency). Moreover, it requires no task-specific labels and no careful hyperparameter tuning, offering plug-and-play real-time hallucination detection in white-box LLMs.
A Head to Predict and a Head to Question: Pre-trained Uncertainty Quantification Heads for Hallucination Detection in LLM Outputs
May 13, 2025Large Language Models (LLMs) have the tendency to hallucinate, i.e., to sporadically generate false or fabricated information. This presents a major challenge, as hallucinations often appear highly convincing and users generally lack the tools to detect them. Uncertainty quantification (UQ) provides a framework for assessing the reliability of model outputs, aiding in the identification of potential hallucinations. In this work, we introduce pre-trained UQ heads: supervised auxiliary modules for LLMs that substantially enhance their ability to capture uncertainty compared to unsupervised UQ methods. Their strong performance stems from the powerful Transformer architecture in their design and informative features derived from LLM attention maps. Experimental evaluation shows that these heads are highly robust and achieve state-of-the-art performance in claim-level hallucination detection across both in-domain and out-of-domain prompts. Moreover, these modules demonstrate strong generalization to languages they were not explicitly trained on. We pre-train a collection of UQ heads for popular LLM series, including Mistral, Llama, and Gemma 2. We publicly release both the code and the pre-trained heads.
Analysis of Emotion in Rumour Threads on Social Media
Feb 23, 2025Rumours in online social media pose significant risks to modern society, motivating the need for better understanding of how they develop. We focus specifically on the interface between emotion and rumours in threaded discourses, building on the surprisingly sparse literature on the topic which has largely focused on emotions within the original rumour posts themselves, and largely overlooked the comparative differences between rumours and non-rumours. In this work, we provide a comprehensive analytical emotion framework, contrasting rumour and non-rumour cases using existing NLP datasets to further understand the emotion dynamics within rumours. Our framework reveals several findings: rumours exhibit more negative sentiment and emotions, including anger, fear and pessimism, while non-rumours evoke more positive emotions; emotions are contagious in online interactions, with rumours facilitate negative emotions and non-rumours foster positive emotions; and based on causal analysis, surprise acts as a bridge between rumours and other emotions, pessimism is driven by sadness and fear, optimism by joy and love.
Control Illusion: The Failure of Instruction Hierarchies in Large Language Models
Feb 21, 2025Large language models (LLMs) are increasingly deployed with hierarchical instruction schemes, where certain instructions (e.g., system-level directives) are expected to take precedence over others (e.g., user messages). Yet, we lack a systematic understanding of how effectively these hierarchical control mechanisms work. We introduce a systematic evaluation framework based on constraint prioritization to assess how well LLMs enforce instruction hierarchies. Our experiments across six state-of-the-art LLMs reveal that models struggle with consistent instruction prioritization, even for simple formatting conflicts. We find that the widely-adopted system/user prompt separation fails to establish a reliable instruction hierarchy, and models exhibit strong inherent biases toward certain constraint types regardless of their priority designation. While controlled prompt engineering and model fine-tuning show modest improvements, our results indicate that instruction hierarchy enforcement is not robustly realized, calling for deeper architectural innovations beyond surface-level modifications.
Token-Level Density-Based Uncertainty Quantification Methods for Eliciting Truthfulness of Large Language Models
Feb 20, 2025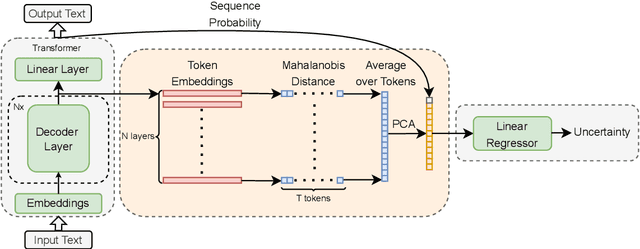

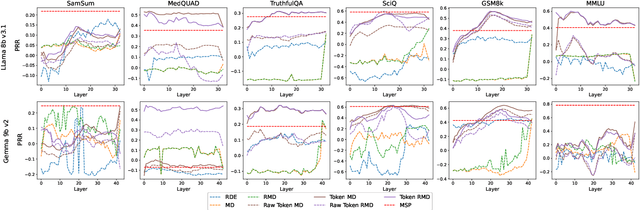
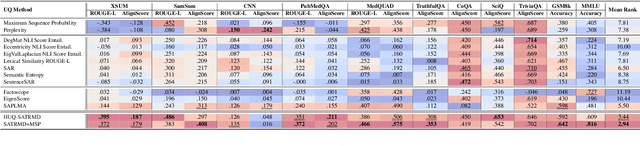
Uncertainty quantification (UQ) is a prominent approach for eliciting truthful answers from large language models (LLMs). To date, information-based and consistency-based UQ have been the dominant UQ methods for text generation via LLMs. Density-based methods, despite being very effective for UQ in text classification with encoder-based models, have not been very successful with generative LLMs. In this work, we adapt Mahalanobis Distance (MD) - a well-established UQ technique in classification tasks - for text generation and introduce a new supervised UQ method. Our method extracts token embeddings from multiple layers of LLMs, computes MD scores for each token, and uses linear regression trained on these features to provide robust uncertainty scores. Through extensive experiments on eleven datasets, we demonstrate that our approach substantially improves over existing UQ methods, providing accurate and computationally efficient uncertainty scores for both sequence-level selective generation and claim-level fact-checking tasks. Our method also exhibits strong generalization to out-of-domain data, making it suitable for a wide range of LLM-based applications.
SCALAR: Scientific Citation-based Live Assessment of Long-context Academic Reasoning
Feb 19, 2025Evaluating large language models' (LLMs) long-context understanding capabilities remains challenging. We present SCALAR (Scientific Citation-based Live Assessment of Long-context Academic Reasoning), a novel benchmark that leverages academic papers and their citation networks. SCALAR features automatic generation of high-quality ground truth labels without human annotation, controllable difficulty levels, and a dynamic updating mechanism that prevents data contamination. Using ICLR 2025 papers, we evaluate 8 state-of-the-art LLMs, revealing key insights about their capabilities and limitations in processing long scientific documents across different context lengths and reasoning types. Our benchmark provides a reliable and sustainable way to track progress in long-context understanding as LLM capabilities evolve.
Qorgau: Evaluating LLM Safety in Kazakh-Russian Bilingual Contexts
Feb 19, 2025Large language models (LLMs) are known to have the potential to generate harmful content, posing risks to users. While significant progress has been made in developing taxonomies for LLM risks and safety evaluation prompts, most studies have focused on monolingual contexts, primarily in English. However, language- and region-specific risks in bilingual contexts are often overlooked, and core findings can diverge from those in monolingual settings. In this paper, we introduce Qorgau, a novel dataset specifically designed for safety evaluation in Kazakh and Russian, reflecting the unique bilingual context in Kazakhstan, where both Kazakh (a low-resource language) and Russian (a high-resource language) are spoken. Experiments with both multilingual and language-specific LLMs reveal notable differences in safety performance, emphasizing the need for tailored, region-specific datasets to ensure the responsible and safe deployment of LLMs in countries like Kazakhstan. Warning: this paper contains example data that may be offensive, harmful, or biased.