 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Lie, We Learn: Multilingual Span-Level Hallucination Detection with PsiloQA
Oct 06, 2025Hallucination detection remains a fundamental challenge for the safe and reliable deployment of large language models (LLMs), especially in applications requiring factual accuracy. Existing hallucination benchmarks often operate at the sequence level and are limited to English, lacking the fine-grained, multilingual supervision needed for a comprehensive evaluation. In this work, we introduce PsiloQA, a large-scale, multilingual dataset annotated with span-level hallucinations across 14 languages. PsiloQA is constructed through an automated three-stage pipeline: generating question-answer pairs from Wikipedia using GPT-4o, eliciting potentially hallucinated answers from diverse LLMs in a no-context setting, and automatically annotating hallucinated spans using GPT-4o by comparing against golden answers and retrieved context. We evaluate a wide range of hallucination detection methods -- including uncertainty quantification, LLM-based tagging, and fine-tuned encoder models -- and show that encoder-based models achieve the strongest performance across languages. Furthermore, PsiloQA demonstrates effective cross-lingual generalization and supports robust knowledge transfer to other benchmarks, all while being significantly more cost-efficient than human-annotated datasets. Our dataset and results advance the development of scalable, fine-grained hallucination detection in multilingual settings.
Uncertainty-Aware Attention Heads: Efficient Unsupervised Uncertainty Quantification for LLMs
May 26, 2025Large language models (LLMs) exhibit impressive fluency, but often produce critical errors known as "hallucinations". Uncertainty quantification (UQ) methods are a promising tool for coping with this fundamental shortcoming. Yet, existing UQ methods face challenges such as high computational overhead or reliance on supervised learning. Here, we aim to bridge this gap. In particular, we propose RAUQ (Recurrent Attention-based Uncertainty Quantification), an unsupervised approach that leverages intrinsic attention patterns in transformers to detect hallucinations efficiently. By analyzing attention weights, we identified a peculiar pattern: drops in attention to preceding tokens are systematically observed during incorrect generations for certain "uncertainty-aware" heads. RAUQ automatically selects such heads, recurrently aggregates their attention weights and token-level confidences, and computes sequence-level uncertainty scores in a single forward pass. Experiments across 4 LLMs and 12 question answering, summarization, and translation tasks demonstrate that RAUQ yields excellent results, outperforming state-of-the-art UQ methods using minimal computational overhead (<1% latency). Moreover, it requires no task-specific labels and no careful hyperparameter tuning, offering plug-and-play real-time hallucination detection in white-box LLMs.
A Head to Predict and a Head to Question: Pre-trained Uncertainty Quantification Heads for Hallucination Detection in LLM Outputs
May 13, 2025Large Language Models (LLMs) have the tendency to hallucinate, i.e., to sporadically generate false or fabricated information. This presents a major challenge, as hallucinations often appear highly convincing and users generally lack the tools to detect them. Uncertainty quantification (UQ) provides a framework for assessing the reliability of model outputs, aiding in the identification of potential hallucinations. In this work, we introduce pre-trained UQ heads: supervised auxiliary modules for LLMs that substantially enhance their ability to capture uncertainty compared to unsupervised UQ methods. Their strong performance stems from the powerful Transformer architecture in their design and informative features derived from LLM attention maps. Experimental evaluation shows that these heads are highly robust and achieve state-of-the-art performance in claim-level hallucination detection across both in-domain and out-of-domain prompts. Moreover, these modules demonstrate strong generalization to languages they were not explicitly trained on. We pre-train a collection of UQ heads for popular LLM series, including Mistral, Llama, and Gemma 2. We publicly release both the code and the pre-trained heads.
Uncertainty-aware abstention in medical diagnosis based on medical texts
Feb 25, 2025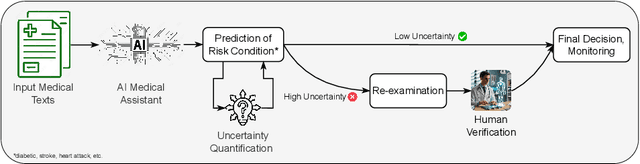
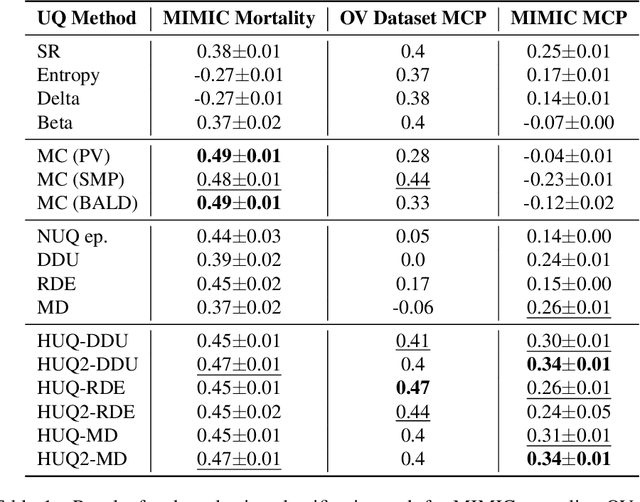
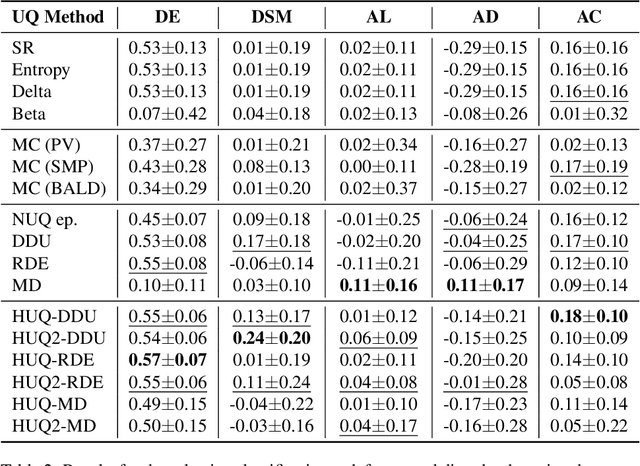
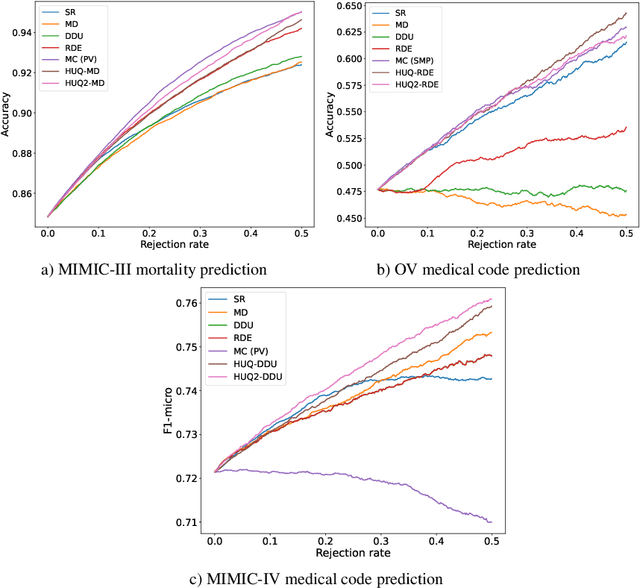
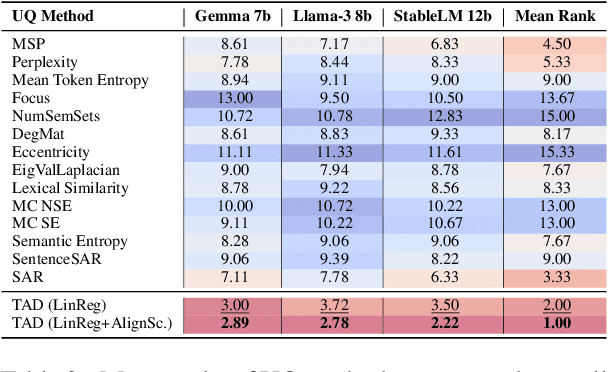
This study addresses the critical issue of reliability for AI-assisted medical diagnosis. We focus on the selection prediction approach that allows the diagnosis system to abstain from providing the decision if it is not confident in the diagnosis. Such selective prediction (or abstention) approaches are usually based on the modeling predictive uncertainty of machine learning models involved. This study explores uncertainty quantification in machine learning models for medical text analysis, addressing diverse tasks across multiple datasets. We focus on binary mortality prediction from textual data in MIMIC-III, multi-label medical code prediction using ICD-10 codes from MIMIC-IV, and multi-class classification with a private outpatient visits dataset. Additionally, we analyze mental health datasets targeting depression and anxiety detection, utilizing various text-based sources, such as essays, social media posts, and clinical descriptions. In addition to comparing uncertainty methods, we introduce HUQ-2, a new state-of-the-art method for enhancing reliability in selective prediction tasks. Our results provide a detailed comparison of uncertainty quantification methods. They demonstrate the effectiveness of HUQ-2 in capturing and evaluating uncertainty, paving the way for more reliable and interpretable applications in medical text analysis.
Token-Level Density-Based Uncertainty Quantification Methods for Eliciting Truthfulness of Large Language Models
Feb 20, 2025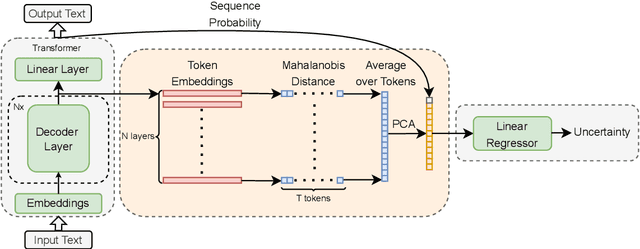

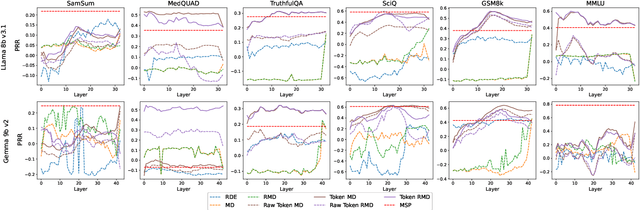
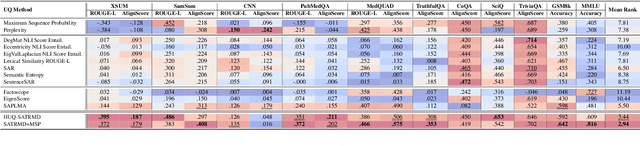
Uncertainty quantification (UQ) is a prominent approach for eliciting truthful answers from large language models (LLMs). To date, information-based and consistency-based UQ have been the dominant UQ methods for text generation via LLMs. Density-based methods, despite being very effective for UQ in text classification with encoder-based models, have not been very successful with generative LLMs. In this work, we adapt Mahalanobis Distance (MD) - a well-established UQ technique in classification tasks - for text generation and introduce a new supervised UQ method. Our method extracts token embeddings from multiple layers of LLMs, computes MD scores for each token, and uses linear regression trained on these features to provide robust uncertainty scores. Through extensive experiments on eleven datasets, we demonstrate that our approach substantially improves over existing UQ methods, providing accurate and computationally efficient uncertainty scores for both sequence-level selective generation and claim-level fact-checking tasks. Our method also exhibits strong generalization to out-of-domain data, making it suitable for a wide range of LLM-based applications.
Unconditional Truthfulness: Learning Conditional Dependency for Uncertainty Quantification of Large Language Models
Aug 20, 2024


Uncertainty quantification (UQ) is a perspective approach to detecting Large Language Model (LLM) hallucinations and low quality output. In this work, we address one of the challenges of UQ in generation tasks that arises from the conditional dependency between the generation steps of an LLM. We propose to learn this dependency from data. We train a regression model, which target variable is the gap between the conditional and the unconditional generation confidence. During LLM inference, we use this learned conditional dependency model to modulate the uncertainty of the current generation step based on the uncertainty of the previous step. Our experimental evaluation on nine datasets and three LLMs shows that the proposed method is highly effective for uncertainty quantification, achieving substantial improvements over rivaling approaches.
Benchmarking Uncertainty Quantification Methods for Large Language Models with LM-Polygraph
Jun 21, 2024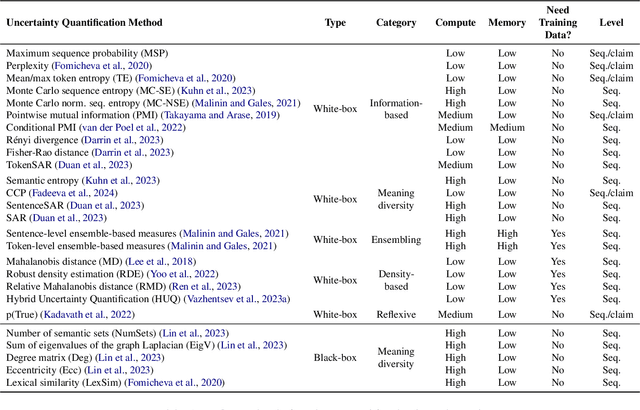
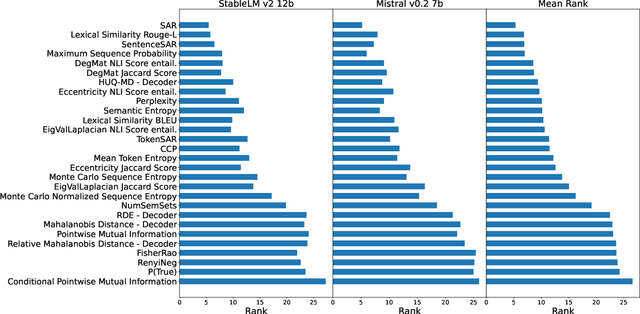
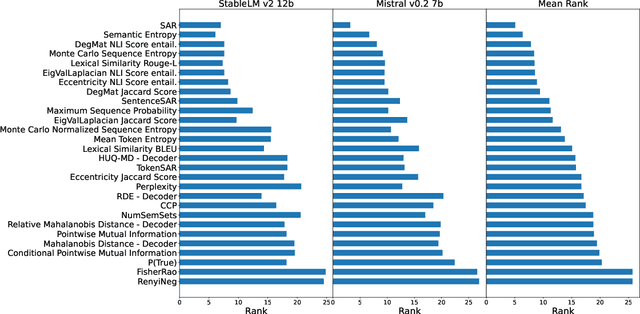
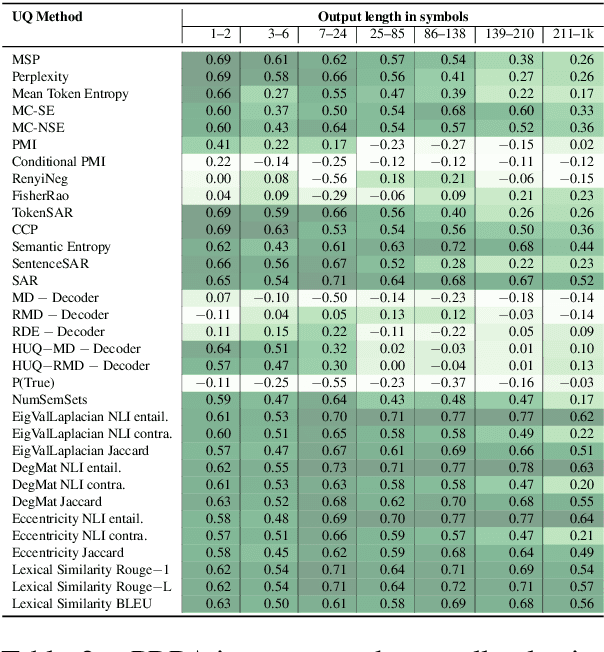
Uncertainty quantification (UQ) is becoming increasingly recognized as a critical component of applications that rely on machine learning (ML). The rapid proliferation of large language models (LLMs) has stimulated researchers to seek efficient and effective approaches to UQ in text generation tasks, as in addition to their emerging capabilities, these models have introduced new challenges for building safe applications. As with other ML models, LLMs are prone to make incorrect predictions, ``hallucinate'' by fabricating claims, or simply generate low-quality output for a given input. UQ is a key element in dealing with these challenges. However research to date on UQ methods for LLMs has been fragmented, with disparate evaluation methods. In this work, we tackle this issue by introducing a novel benchmark that implements a collection of state-of-the-art UQ baselines, and provides an environment for controllable and consistent evaluation of novel techniques by researchers in various text generation tasks. Our benchmark also supports the assessment of confidence normalization methods in terms of their ability to provide interpretable scores. Using our benchmark, we conduct a large-scale empirical investigation of UQ and normalization techniques across nine tasks and shed light on the most promising approaches.
LM-Polygraph: Uncertainty Estimation for Language Models
Nov 13, 2023
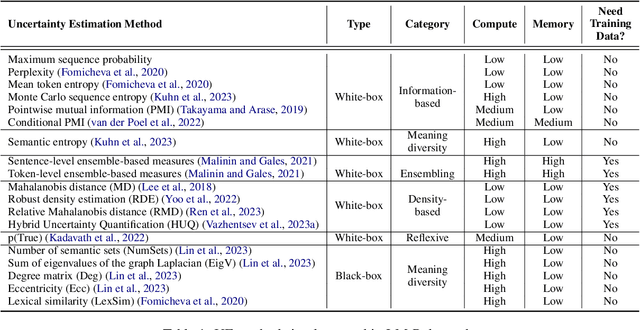
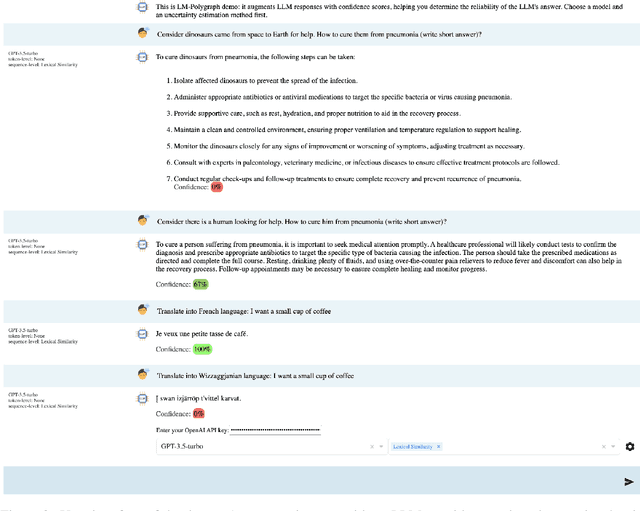
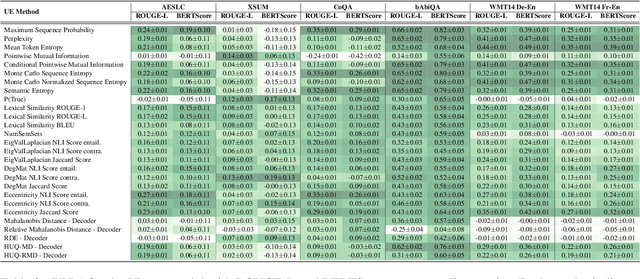
Recent advancements in the capabilities of large language models (LLMs) have paved the way for a myriad of groundbreaking applications in various fields. However, a significant challenge arises as these models often "hallucinate", i.e., fabricate facts without providing users an apparent means to discern the veracity of their statements. Uncertainty estimation (UE) methods are one path to safer, more responsible, and more effective use of LLMs. However, to date, research on UE methods for LLMs has been focused primarily on theoretical rather than engineering contributions. In this work, we tackle this issue by introducing LM-Polygraph, a framework with implementations of a battery of state-of-the-art UE methods for LLMs in text generation tasks, with unified program interfaces in Python. Additionally, it introduces an extendable benchmark for consistent evaluation of UE techniques by researchers, and a demo web application that enriches the standard chat dialog with confidence scores, empowering end-users to discern unreliable responses. LM-Polygraph is compatible with the most recent LLMs, including BLOOMz, LLaMA-2, ChatGPT, and GPT-4, and is designed to support future releases of similarly-styled LMs.