 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuCCoD: Towards Automated ICD Coding in Russian
Feb 28, 2025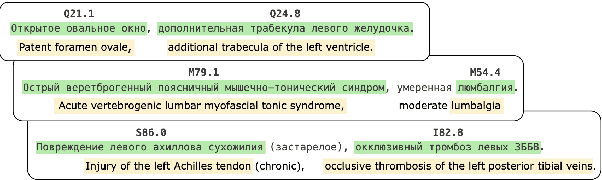

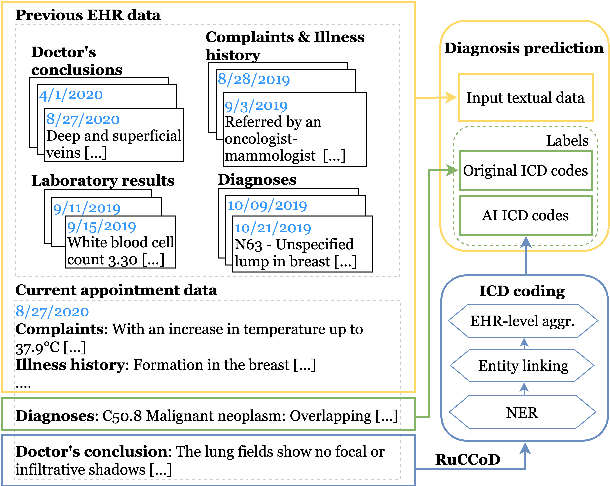
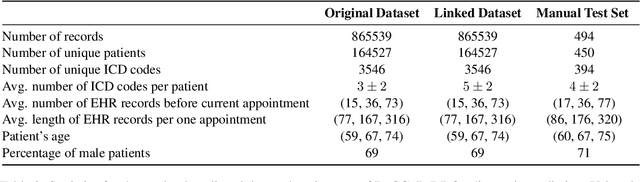
This study investigates the feasibility of automating clinical coding in Russian, a language with limited biomedical resources. We present a new dataset for ICD coding, which includes diagnosis fields from electronic health records (EHRs) annotated with over 10,000 entities and more than 1,500 unique ICD codes. This dataset serves as a benchmark for several state-of-the-art models, including BERT, LLaMA with LoRA, and RAG, with additional experiments examining transfer learning across domains (from PubMed abstracts to medical diagnosis) and terminologies (from UMLS concepts to ICD codes). We then apply the best-performing model to label an in-house EHR dataset containing patient histories from 2017 to 2021. Our experiments, conducted on a carefully curated test set, demonstrate that training with the automated predicted codes leads to a significant improvement in accuracy compared to manually annotated data from physicians. We believe our findings offer valuable insights into the potential for automating clinical coding in resource-limited languages like Russian, which could enhance clinical efficiency and data accuracy in these contexts.
Uncertainty-aware abstention in medical diagnosis based on medical texts
Feb 25, 2025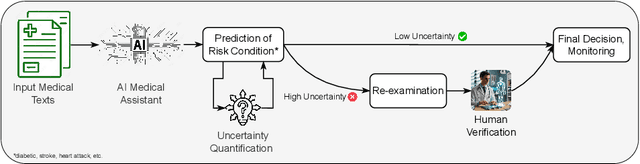
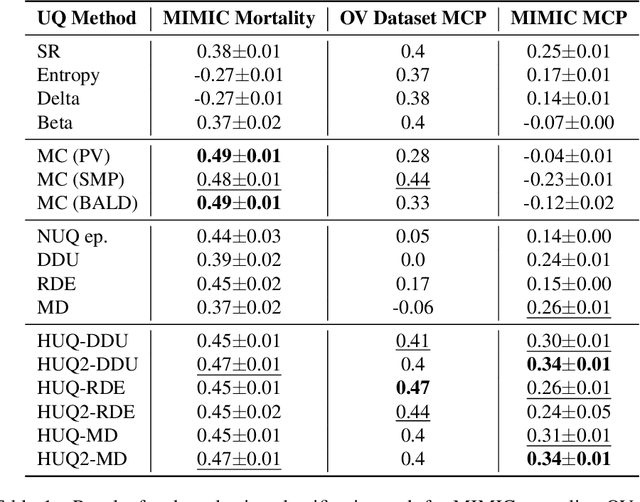
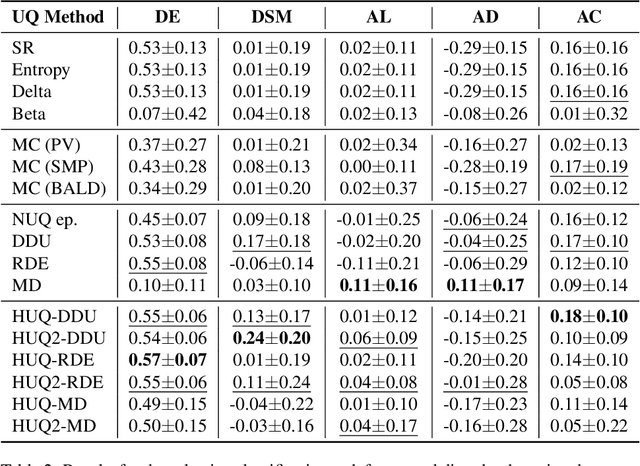
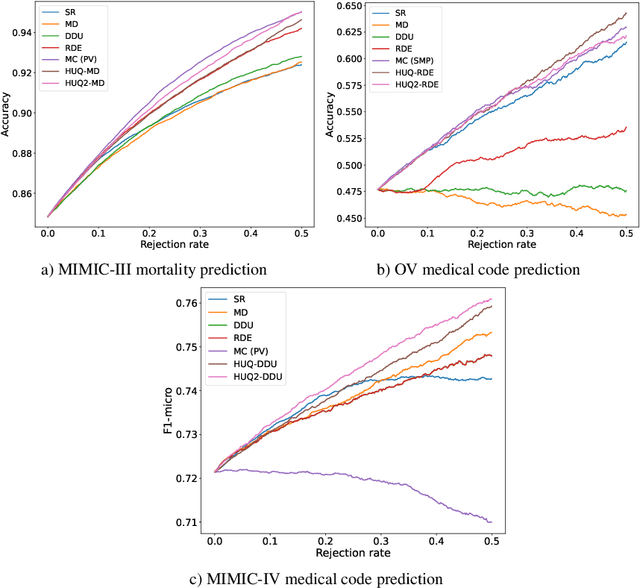
This study addresses the critical issue of reliability for AI-assisted medical diagnosis. We focus on the selection prediction approach that allows the diagnosis system to abstain from providing the decision if it is not confident in the diagnosis. Such selective prediction (or abstention) approaches are usually based on the modeling predictive uncertainty of machine learning models involved. This study explores uncertainty quantification in machine learning models for medical text analysis, addressing diverse tasks across multiple datasets. We focus on binary mortality prediction from textual data in MIMIC-III, multi-label medical code prediction using ICD-10 codes from MIMIC-IV, and multi-class classification with a private outpatient visits dataset. Additionally, we analyze mental health datasets targeting depression and anxiety detection, utilizing various text-based sources, such as essays, social media posts, and clinical descriptions. In addition to comparing uncertainty methods, we introduce HUQ-2, a new state-of-the-art method for enhancing reliability in selective prediction tasks. Our results provide a detailed comparison of uncertainty quantification methods. They demonstrate the effectiveness of HUQ-2 in capturing and evaluating uncertainty, paving the way for more reliable and interpretable applications in medical text analysis.
NeuralSympCheck: A Symptom Checking and Disease Diagnostic Neural Model with Logic Regularization
Jun 02, 2022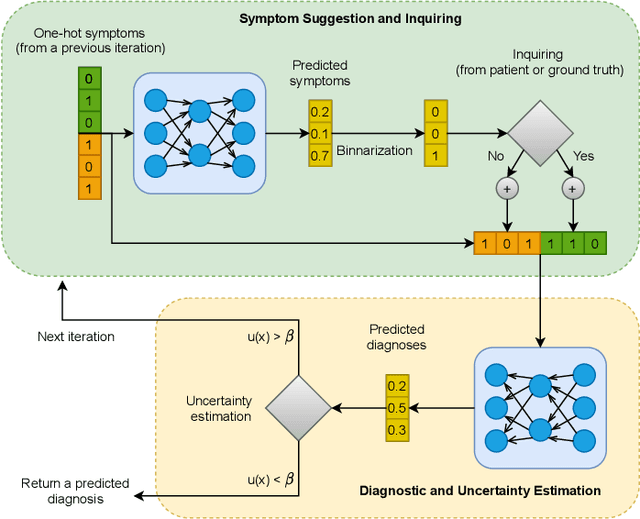
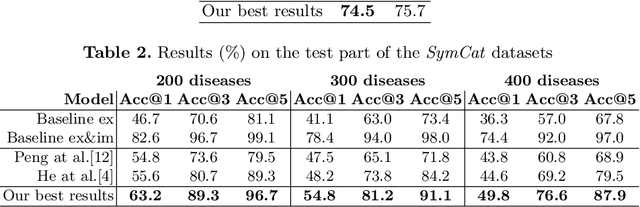
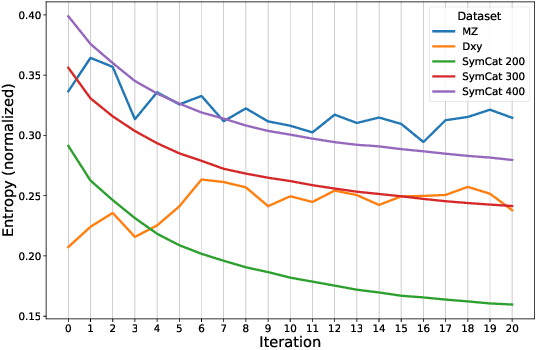
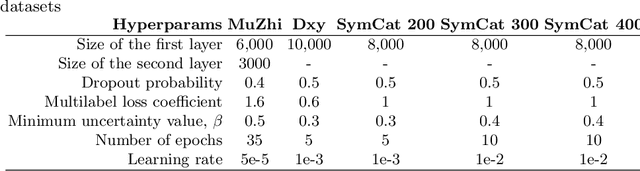
The symptom checking systems inquire users for their symptoms and perform a rapid and affordable medical assessment of their condition. The basic symptom checking systems based on Bayesian methods, decision trees, or information gain methods are easy to train and do not require significant computational resources. However, their drawbacks are low relevance of proposed symptoms and insufficient quality of diagnostics. The best results on these tasks are achieved by reinforcement learning models. Their weaknesses are the difficulty of developing and training such systems and limited applicability to cases with large and sparse decision spaces. We propose a new approach based on the supervised learning of neural models with logic regularization that combines the advantages of the different methods. Our experiments on real and synthetic data show that the proposed approach outperforms the best existing methods in the accuracy of diagnosis when the number of diagnoses and symptoms is large.
RuMedBench: A Russian Medical Language Understanding Benchmark
Jan 17, 2022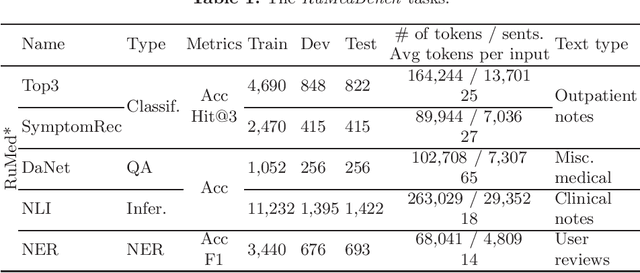


The paper describes the open Russian medical language understanding benchmark covering several task types (classification, question answering, natural language inference, named entity recognition) on a number of novel text sets. Given the sensitive nature of the data in healthcare, such a benchmark partially closes the problem of Russian medical dataset absence. We prepare the unified format labeling, data split, and evaluation metrics for new tasks. The remaining tasks are from existing datasets with a few modifications. A single-number metric expresses a model's ability to cope with the benchmark. Moreover, we implement several baseline models, from simple ones to neural networks with transformer architecture, and release the code. Expectedly, the more advanced models yield better performance, but even a simple model is enough for a decent result in some tasks. Furthermore, for all tasks, we provide a human evaluation. Interestingly the models outperform humans in the large-scale classification tasks. However, the advantage of natural intelligence remains in the tasks requiring more knowledge and reasoning.
CoRSAI: A System for Robust Interpretation of CT Scans of COVID-19 Patients Using Deep Learning
May 25, 2021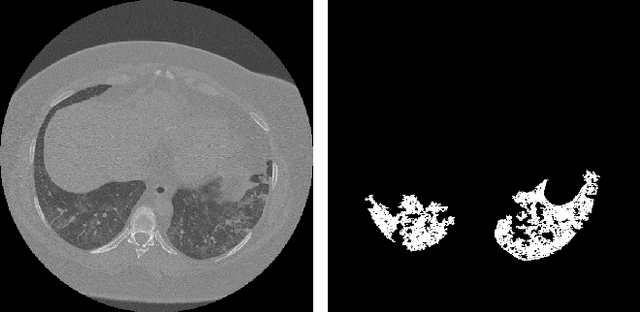


Analysis of chest CT scans can be used in detecting parts of lungs that are affected by infectious diseases such as COVID-19.Determining the volume of lungs affected by lesions is essential for formulating treatment recommendations and prioritizingpatients by severity of the disease. In this paper we adopted an approach based on using an ensemble of deep convolutionalneural networks for segmentation of slices of lung CT scans. Using our models we are able to segment the lesions, evaluatepatients dynamics, estimate relative volume of lungs affected by lesions and evaluate the lung damage stage. Our modelswere trained on data from different medical centers. We compared predictions of our models with those of six experiencedradiologists and our segmentation model outperformed most of them. On the task of classification of disease severity, ourmodel outperformed all the radiologists.