 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuCCoD: Towards Automated ICD Coding in Russian
Feb 28, 2025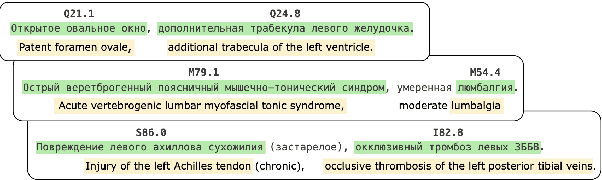

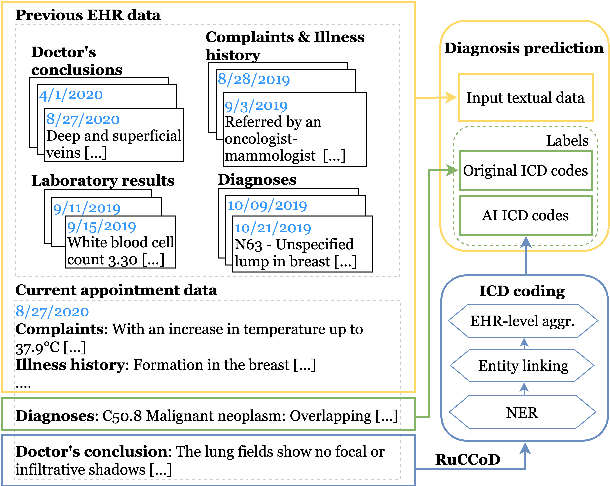
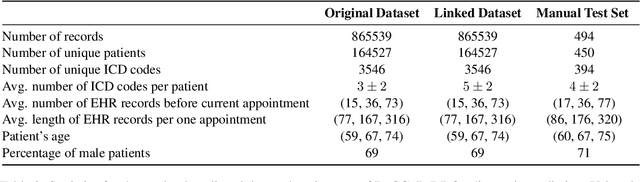
This study investigates the feasibility of automating clinical coding in Russian, a language with limited biomedical resources. We present a new dataset for ICD coding, which includes diagnosis fields from electronic health records (EHRs) annotated with over 10,000 entities and more than 1,500 unique ICD codes. This dataset serves as a benchmark for several state-of-the-art models, including BERT, LLaMA with LoRA, and RAG, with additional experiments examining transfer learning across domains (from PubMed abstracts to medical diagnosis) and terminologies (from UMLS concepts to ICD codes). We then apply the best-performing model to label an in-house EHR dataset containing patient histories from 2017 to 2021. Our experiments, conducted on a carefully curated test set, demonstrate that training with the automated predicted codes leads to a significant improvement in accuracy compared to manually annotated data from physicians. We believe our findings offer valuable insights into the potential for automating clinical coding in resource-limited languages like Russian, which could enhance clinical efficiency and data accuracy in these contexts.
Code Summarization Beyond Function Level
Feb 23, 2025



Code summarization is a critical task in natural language processing and software engineering, which aims to generate concise descriptions of source code. Recent advancements have improved the quality of these summaries, enhancing code readability and maintainability. However, the content of a repository or a class has not been considered in function code summarization. This study investigated the effectiveness of code summarization models beyond the function level, exploring the impact of class and repository contexts on the summary quality. The study involved revising benchmarks for evaluating models at class and repository levels, assessing baseline models, and evaluating LLMs with in-context learning to determine the enhancement of summary quality with additional context. The findings revealed that the fine-tuned state-of-the-art CodeT5+ base model excelled in code summarization, while incorporating few-shot learning and retrieved code chunks from RAG significantly enhanced the performance of LLMs in this task. Notably, the Deepseek Coder 1.3B and Starcoder2 15B models demonstrated substantial improvements in metrics such as BLEURT, METEOR, and BLEU-4 at both class and repository levels. Repository-level summarization exhibited promising potential but necessitates significant computational resources and gains from the inclusion of structured context. Lastly, we employed the recent SIDE code summarization metric in our evaluation. This study contributes to refining strategies for prompt engineering, few-shot learning, and RAG, addressing gaps in benchmarks for code summarization at various levels. Finally, we publish all study details, code, datasets, and results of evaluation in the GitHub repository available at https://github.com/kilimanj4r0/code-summarization-beyond-function-level.
Leveraging Large Language Models in Code Question Answering: Baselines and Issues
Nov 05, 2024
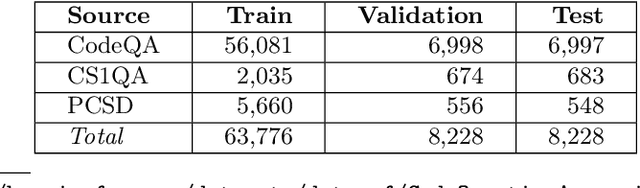
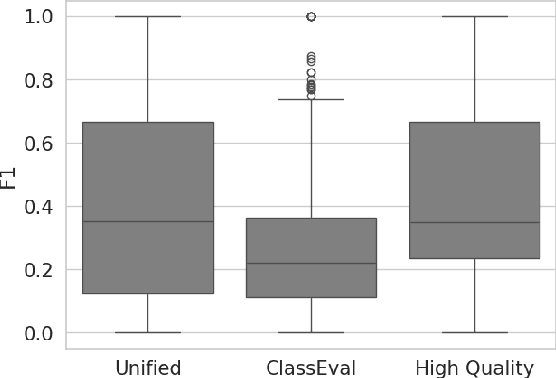
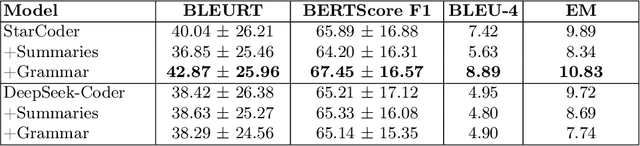
Question answering over source code provides software engineers and project managers with helpful information about the implemented features of a software product. This paper presents a work devoted to using large language models for question answering over source code in Python. The proposed method for implementing a source code question answering system involves fine-tuning a large language model on a unified dataset of questions and answers for Python code. To achieve the highest quality answers, we tested various models trained on datasets preprocessed in different ways: a dataset without grammar correction, a dataset with grammar correction, and a dataset augmented with the generated summaries. The model answers were also analyzed for errors manually. We report BLEU-4, BERTScore F1, BLEURT, and Exact Match metric values, along with the conclusions from the manual error analysis. The obtained experimental results highlight the current problems of the research area, such as poor quality of the public genuine question-answering datasets. In addition, the findings include the positive effect of the grammar correction of the training data on the testing metric values. The addressed findings and issues could be important for other researchers who attempt to improve the quality of source code question answering solutions. The training and evaluation code is publicly available at https://github.com/IU-AES-AI4Code/CodeQuestionAnswering.