 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuCCoD: Towards Automated ICD Coding in Russian
Feb 28, 2025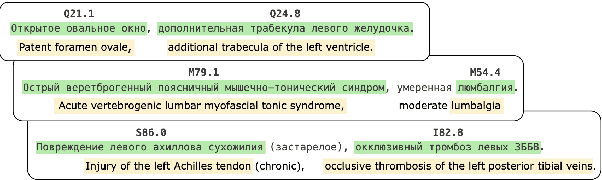

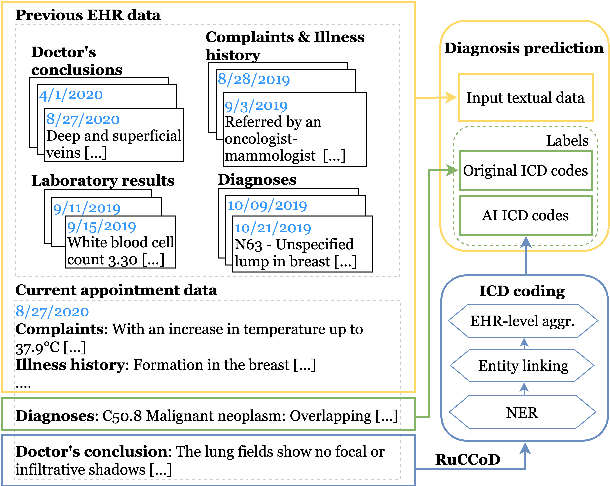
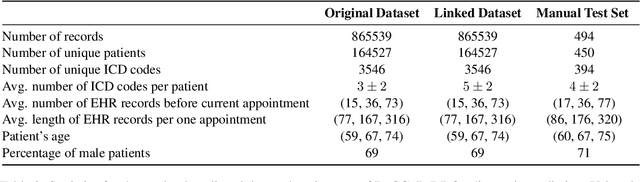
This study investigates the feasibility of automating clinical coding in Russian, a language with limited biomedical resources. We present a new dataset for ICD coding, which includes diagnosis fields from electronic health records (EHRs) annotated with over 10,000 entities and more than 1,500 unique ICD codes. This dataset serves as a benchmark for several state-of-the-art models, including BERT, LLaMA with LoRA, and RAG, with additional experiments examining transfer learning across domains (from PubMed abstracts to medical diagnosis) and terminologies (from UMLS concepts to ICD codes). We then apply the best-performing model to label an in-house EHR dataset containing patient histories from 2017 to 2021. Our experiments, conducted on a carefully curated test set, demonstrate that training with the automated predicted codes leads to a significant improvement in accuracy compared to manually annotated data from physicians. We believe our findings offer valuable insights into the potential for automating clinical coding in resource-limited languages like Russian, which could enhance clinical efficiency and data accuracy in these contexts.
nach0-pc: Multi-task Language Model with Molecular Point Cloud Encoder
Oct 11, 2024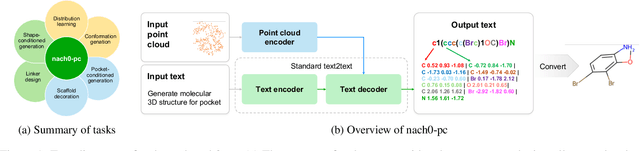
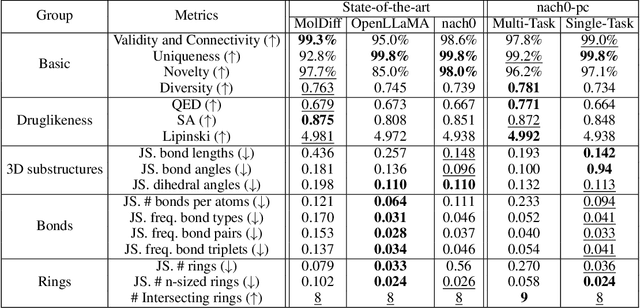
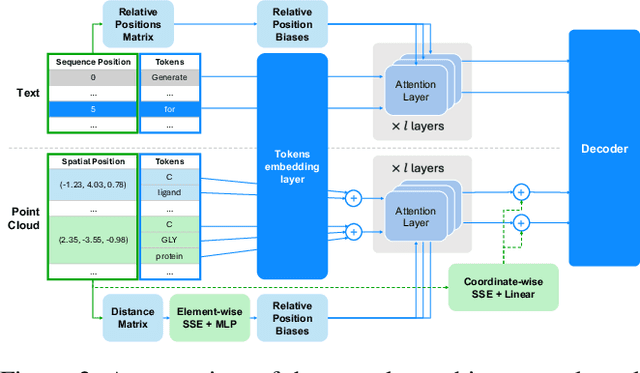
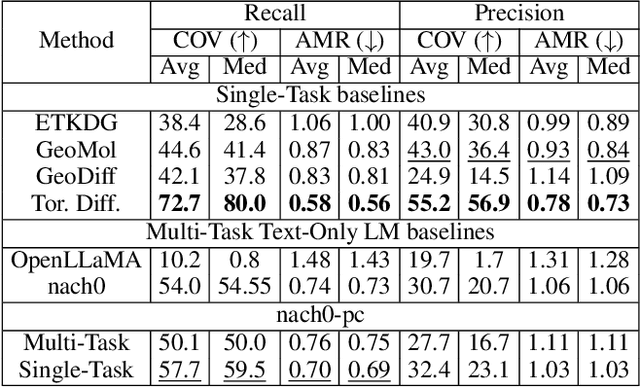
Recent advancements have integrated Language Models (LMs) into a drug discovery pipeline. However, existing models mostly work with SMILES and SELFIES chemical string representations, which lack spatial features vital for drug discovery. Additionally, attempts to translate chemical 3D structures into text format encounter issues such as excessive length and insufficient atom connectivity information. To address these issues, we introduce nach0-pc, a model combining domain-specific encoder and textual representation to handle spatial arrangement of atoms effectively. Our approach utilizes a molecular point cloud encoder for concise and order-invariant structure representation. We introduce a novel pre-training scheme for molecular point clouds to distillate the knowledge from spatial molecular structures datasets. After fine-tuning within both single-task and multi-task frameworks, nach0-pc demonstrates performance comparable with other diffusion models in terms of generated samples quality across several established spatial molecular generation tasks. Notably, our model is a multi-task approach, in contrast to diffusion models being limited to single tasks. Additionally, it is capable of processing point cloud-related data, which language models are not capable of handling due to memory limitations. These lead to our model having reduced training and inference time while maintaining on par performance.