 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBALI: Enhancing Biomedical Language Representations through Knowledge Graph and Language Model Alignment
Sep 09, 2025In recent years, there has been substantial progress in using pretrained Language Models (LMs) on a range of tasks aimed at improving the understanding of biomedical texts. Nonetheless, existing biomedical LLMs show limited comprehension of complex, domain-specific concept structures and the factual information encoded in biomedical Knowledge Graphs (KGs). In this work, we propose BALI (Biomedical Knowledge Graph and Language Model Alignment), a novel joint LM and KG pre-training method that augments an LM with external knowledge by the simultaneous learning of a dedicated KG encoder and aligning the representations of both the LM and the graph. For a given textual sequence, we link biomedical concept mentions to the Unified Medical Language System (UMLS) KG and utilize local KG subgraphs as cross-modal positive samples for these mentions. Our empirical findings indicate that implementing our method on several leading biomedical LMs, such as PubMedBERT and BioLinkBERT, improves their performance on a range of language understanding tasks and the quality of entity representations, even with minimal pre-training on a small alignment dataset sourced from PubMed scientific abstracts.
* 9 pages, 1 figure, published in "The 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2025)"
RuCCoD: Towards Automated ICD Coding in Russian
Feb 28, 2025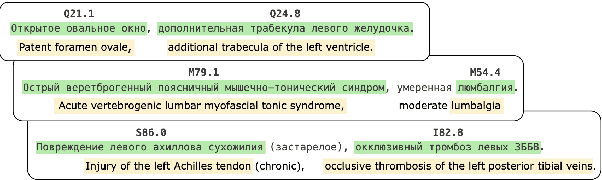

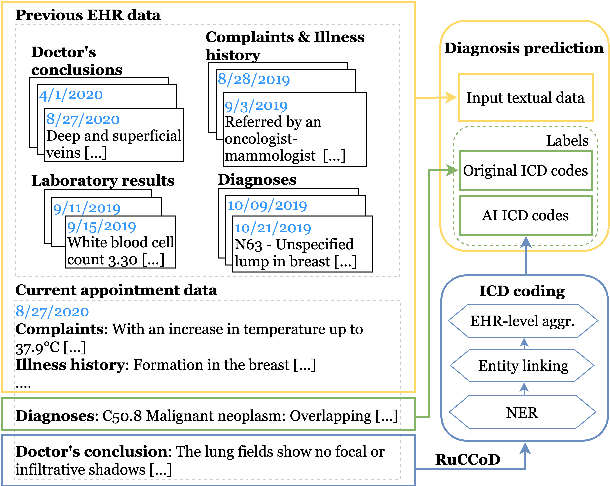
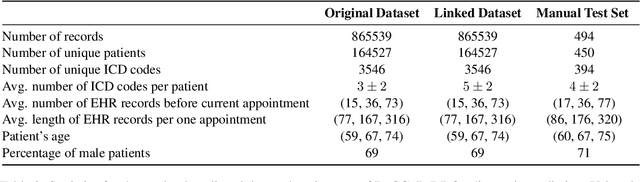
This study investigates the feasibility of automating clinical coding in Russian, a language with limited biomedical resources. We present a new dataset for ICD coding, which includes diagnosis fields from electronic health records (EHRs) annotated with over 10,000 entities and more than 1,500 unique ICD codes. This dataset serves as a benchmark for several state-of-the-art models, including BERT, LLaMA with LoRA, and RAG, with additional experiments examining transfer learning across domains (from PubMed abstracts to medical diagnosis) and terminologies (from UMLS concepts to ICD codes). We then apply the best-performing model to label an in-house EHR dataset containing patient histories from 2017 to 2021. Our experiments, conducted on a carefully curated test set, demonstrate that training with the automated predicted codes leads to a significant improvement in accuracy compared to manually annotated data from physicians. We believe our findings offer valuable insights into the potential for automating clinical coding in resource-limited languages like Russian, which could enhance clinical efficiency and data accuracy in these contexts.
The Russian Drug Reaction Corpus and Neural Models for Drug Reactions and Effectiveness Detection in User Reviews
Apr 07, 2020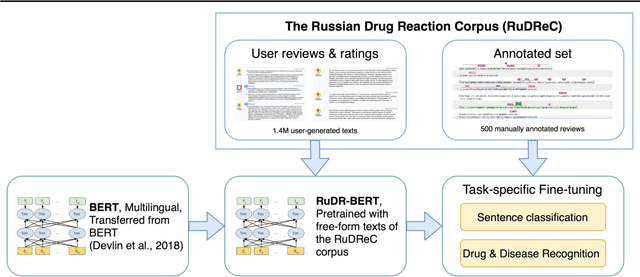
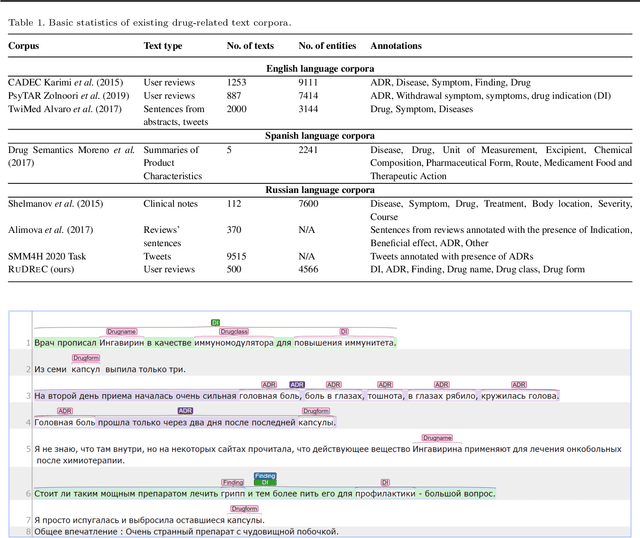
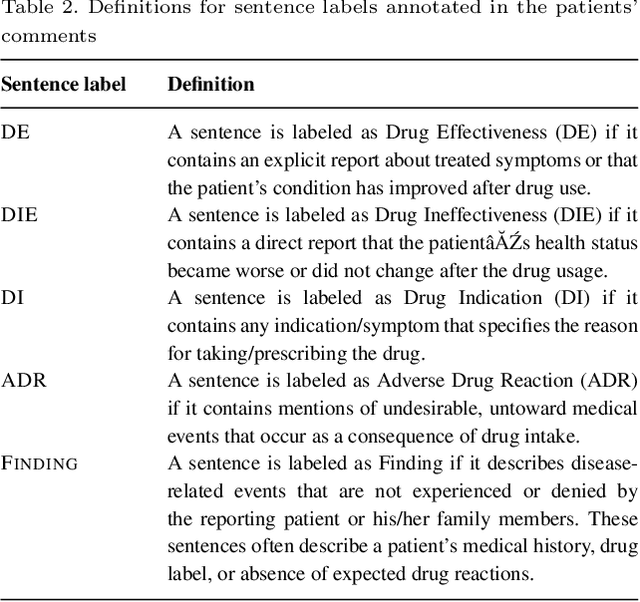
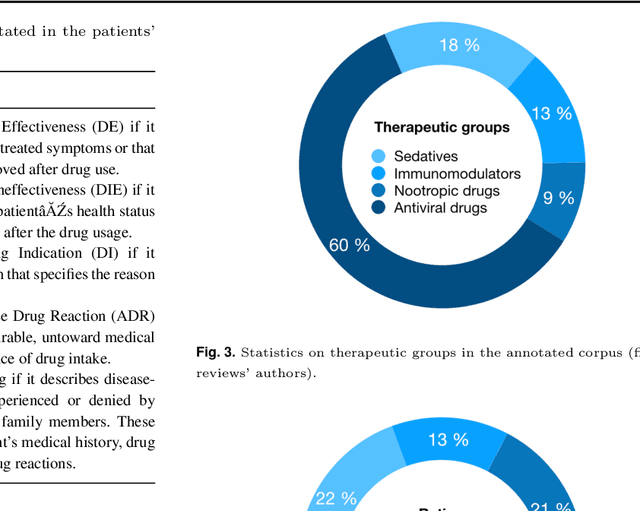
The Russian Drug Reaction Corpus (RuDReC) is a new partially annotated corpus of consumer reviews in Russian about pharmaceutical products for the detection of health-related named entities and the effectiveness of pharmaceutical products. The corpus itself consists of two parts, the raw one and the labelled one. The raw part includes 1.4 million health-related user-generated texts collected from various Internet sources, including social media. The labelled part contains 500 consumer reviews about drug therapy with drug- and disease-related information. Labels for sentences include health-related issues or their absence. The sentences with one are additionally labelled at the expression level for identification of fine-grained subtypes such as drug classes and drug forms, drug indications, and drug reactions. Further, we present a baseline model for named entity recognition (NER) and multi-label sentence classification tasks on this corpus. The macro F1 score of 74.85% in the NER task was achieved by our RuDR-BERT model. For the sentence classification task, our model achieves the macro F1 score of 68.82% gaining 7.47% over the score of BERT model trained on Russian data. We make the RuDReC corpus and pretrained weights of domain-specific BERT models freely available at https://github.com/cimm-kzn/RuDReC