 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 3: Dimensional Aspect-Based Sentiment Analysis (DimABSA)
Apr 08, 2026We present the SemEval-2026 shared task on Dimensional Aspect-Based Sentiment Analysis (DimABSA), which improves traditional ABSA by modeling sentiment along valence-arousal (VA) dimensions rather than using categorical polarity labels. To extend ABSA beyond consumer reviews to public-issue discourse (e.g., political, energy, and climate issues), we introduce an additional task, Dimensional Stance Analysis (DimStance), which treats stance targets as aspects and reformulates stance detection as regression in the VA space. The task consists of two tracks: Track A (DimABSA) and Track B (DimStance). Track A includes three subtasks: (1) dimensional aspect sentiment regression, (2) dimensional aspect sentiment triplet extraction, and (3) dimensional aspect sentiment quadruplet extraction, while Track B includes only the regression subtask for stance targets. We also introduce a continuous F1 (cF1) metric to jointly evaluate structured extraction and VA regression. The task attracted more than 400 participants, resulting in 112 final submissions and 42 system description papers. We report baseline results, discuss top-performing systems, and analyze key design choices to provide insights into dimensional sentiment analysis at the aspect and stance-target levels. All resources are available on our GitHub repository.
DimABSA: Building Multilingual and Multidomain Datasets for Dimensional Aspect-Based Sentiment Analysis
Jan 30, 2026Aspect-Based Sentiment Analysis (ABSA) focuses on extracting sentiment at a fine-grained aspect level and has been widely applied across real-world domains. However, existing ABSA research relies on coarse-grained categorical labels (e.g., positive, negative), which limits its ability to capture nuanced affective states. To address this limitation, we adopt a dimensional approach that represents sentiment with continuous valence-arousal (VA) scores, enabling fine-grained analysis at both the aspect and sentiment levels. To this end, we introduce DimABSA, the first multilingual, dimensional ABSA resource annotated with both traditional ABSA elements (aspect terms, aspect categories, and opinion terms) and newly introduced VA scores. This resource contains 76,958 aspect instances across 42,590 sentences, spanning six languages and four domains. We further introduce three subtasks that combine VA scores with different ABSA elements, providing a bridge from traditional ABSA to dimensional ABSA. Given that these subtasks involve both categorical and continuous outputs, we propose a new unified metric, continuous F1 (cF1), which incorporates VA prediction error into standard F1. We provide a comprehensive benchmark using both prompted and fine-tuned large language models across all subtasks. Our results show that DimABSA is a challenging benchmark and provides a foundation for advancing multilingual dimensional ABSA.
Multimodal Evaluation of Russian-language Architectures
Nov 19, 2025Multimodal large language models (MLLMs) are currently at the center of research attention, showing rapid progress in scale and capabilities, yet their intelligence, limitations, and risks remain insufficiently understood. To address these issues, particularly in the context of the Russian language, where no multimodal benchmarks currently exist, we introduce Mera Multi, an open multimodal evaluation framework for Russian-spoken architectures. The benchmark is instruction-based and encompasses default text, image, audio, and video modalities, comprising 18 newly constructed evaluation tasks for both general-purpose models and modality-specific architectures (image-to-text, video-to-text, and audio-to-text). Our contributions include: (i) a universal taxonomy of multimodal abilities; (ii) 18 datasets created entirely from scratch with attention to Russian cultural and linguistic specificity, unified prompts, and metrics; (iii) baseline results for both closed-source and open-source models; (iv) a methodology for preventing benchmark leakage, including watermarking and licenses for private sets. While our current focus is on Russian, the proposed benchmark provides a replicable methodology for constructing multimodal benchmarks in typologically diverse languages, particularly within the Slavic language family.
MERA Code: A Unified Framework for Evaluating Code Generation Across Tasks
Jul 16, 2025Advancements in LLMs have enhanced task automation in software engineering; however, current evaluations primarily focus on natural language tasks, overlooking code quality. Most benchmarks prioritize high-level reasoning over executable code and real-world performance, leaving gaps in understanding true capabilities and risks associated with these models in production. To address this issue, we propose MERA Code, a new addition to the MERA benchmark family, specifically focused on evaluating code for the latest code generation LLMs in Russian. This benchmark includes 11 evaluation tasks that span 8 programming languages. Our proposed evaluation methodology features a taxonomy that outlines the practical coding skills necessary for models to complete these tasks. The benchmark comprises an open-source codebase for users to conduct MERA assessments, a scoring system compatible with various programming environments, and a platform featuring a leaderboard and submission system. We evaluate open LLMs and frontier API models, analyzing their limitations in terms of practical coding tasks in non-English languages. We are publicly releasing MERA to guide future research, anticipate groundbreaking features in model development, and standardize evaluation procedures.
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
RuBia: A Russian Language Bias Detection Dataset
Mar 26, 2024Warning: this work contains upsetting or disturbing content. Large language models (LLMs) tend to learn the social and cultural biases present in the raw pre-training data. To test if an LLM's behavior is fair, functional datasets are employed, and due to their purpose, these datasets are highly language and culture-specific. In this paper, we address a gap in the scope of multilingual bias evaluation by presenting a bias detection dataset specifically designed for the Russian language, dubbed as RuBia. The RuBia dataset is divided into 4 domains: gender, nationality, socio-economic status, and diverse, each of the domains is further divided into multiple fine-grained subdomains. Every example in the dataset consists of two sentences with the first reinforcing a potentially harmful stereotype or trope and the second contradicting it. These sentence pairs were first written by volunteers and then validated by native-speaking crowdsourcing workers. Overall, there are nearly 2,000 unique sentence pairs spread over 19 subdomains in RuBia. To illustrate the dataset's purpose, we conduct a diagnostic evaluation of state-of-the-art or near-state-of-the-art LLMs and discuss the LLMs' predisposition to social biases.
Sinkhorn Transformations for Single-Query Postprocessing in Text-Video Retrieval
Nov 14, 2023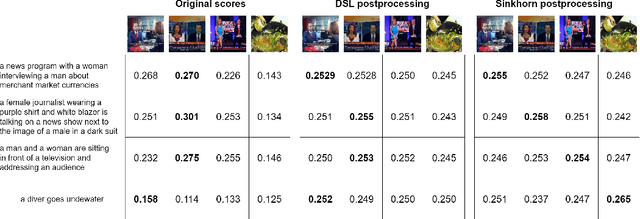
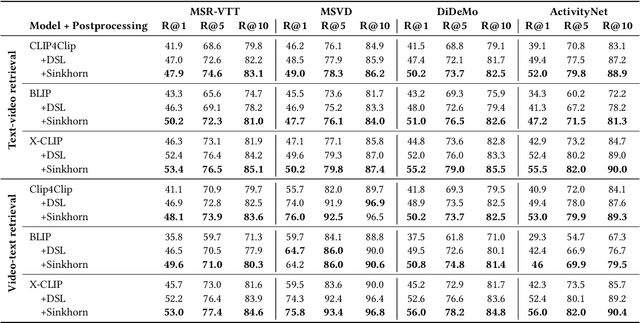
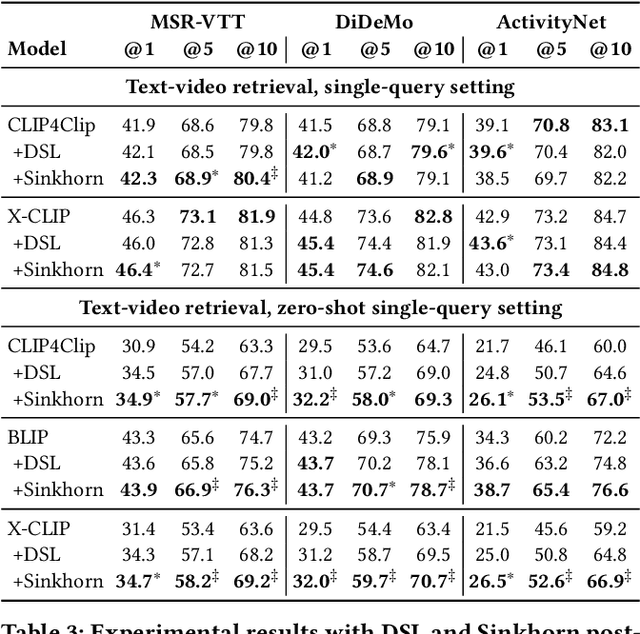
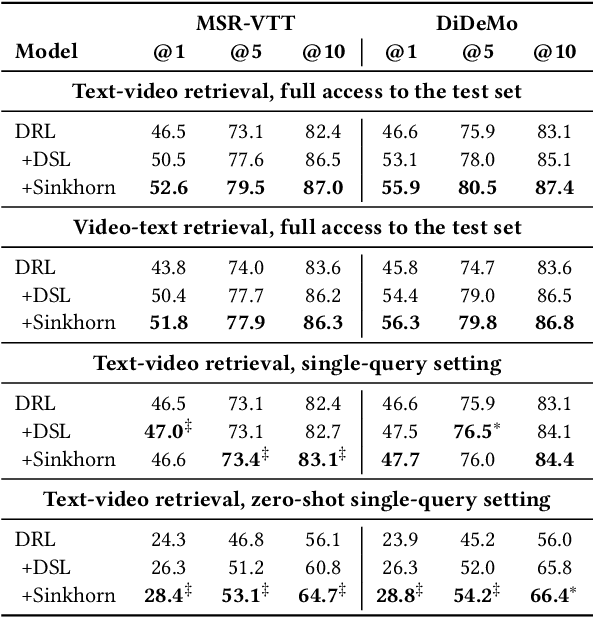
A recent trend in multimodal retrieval is related to postprocessing test set results via the dual-softmax loss (DSL). While this approach can bring significant improvements, it usually presumes that an entire matrix of test samples is available as DSL input. This work introduces a new postprocessing approach based on Sinkhorn transformations that outperforms DSL. Further, we propose a new postprocessing setting that does not require access to multiple test queries. We show that our approach can significantly improve the results of state of the art models such as CLIP4Clip, BLIP, X-CLIP, and DRL, thus achieving a new state-of-the-art on several standard text-video retrieval datasets both with access to the entire test set and in the single-query setting.
Selection of pseudo-annotated data for adverse drug reaction classification across drug groups
Nov 24, 2021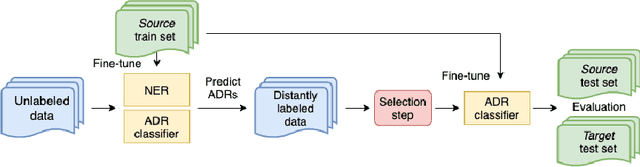
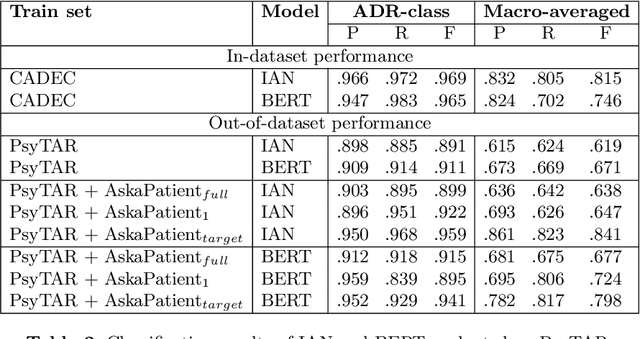
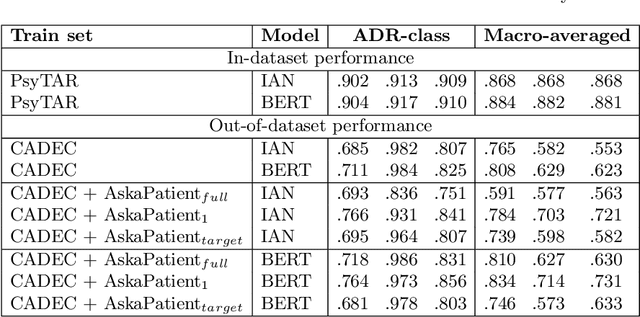
Automatic monitoring of adverse drug events (ADEs) or reactions (ADRs) is currently receiving significant attention from the biomedical community. In recent years, user-generated data on social media has become a valuable resource for this task. Neural models have achieved impressive performance on automatic text classification for ADR detection. Yet, training and evaluation of these methods are carried out on user-generated texts about a targeted drug. In this paper, we assess the robustness of state-of-the-art neural architectures across different drug groups. We investigate several strategies to use pseudo-labeled data in addition to a manually annotated train set. Out-of-dataset experiments diagnose the bottleneck of supervised models in terms of breakdown performance, while additional pseudo-labeled data improves overall results regardless of the text selection strategy.
The Russian Drug Reaction Corpus and Neural Models for Drug Reactions and Effectiveness Detection in User Reviews
Apr 07, 2020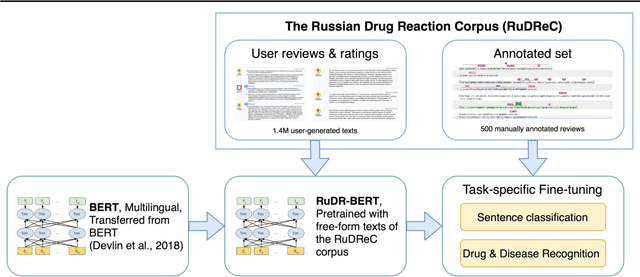
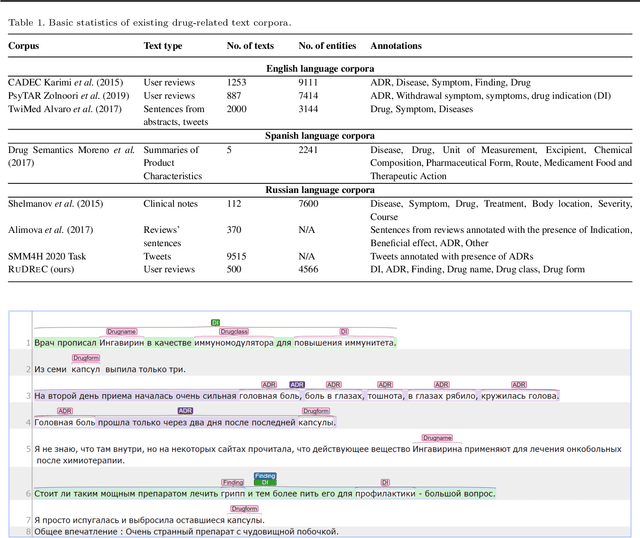
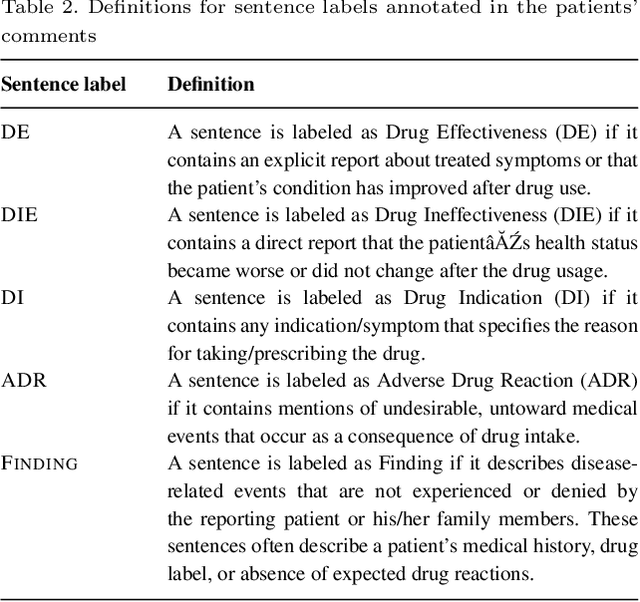
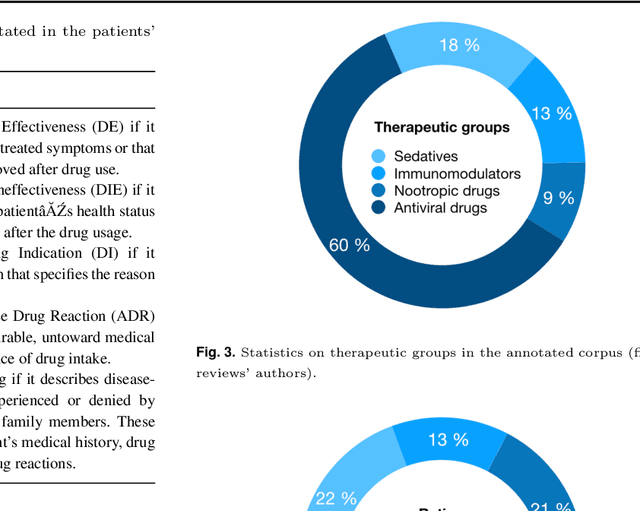
The Russian Drug Reaction Corpus (RuDReC) is a new partially annotated corpus of consumer reviews in Russian about pharmaceutical products for the detection of health-related named entities and the effectiveness of pharmaceutical products. The corpus itself consists of two parts, the raw one and the labelled one. The raw part includes 1.4 million health-related user-generated texts collected from various Internet sources, including social media. The labelled part contains 500 consumer reviews about drug therapy with drug- and disease-related information. Labels for sentences include health-related issues or their absence. The sentences with one are additionally labelled at the expression level for identification of fine-grained subtypes such as drug classes and drug forms, drug indications, and drug reactions. Further, we present a baseline model for named entity recognition (NER) and multi-label sentence classification tasks on this corpus. The macro F1 score of 74.85% in the NER task was achieved by our RuDR-BERT model. For the sentence classification task, our model achieves the macro F1 score of 68.82% gaining 7.47% over the score of BERT model trained on Russian data. We make the RuDReC corpus and pretrained weights of domain-specific BERT models freely available at https://github.com/cimm-kzn/RuDReC