 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelection of pseudo-annotated data for adverse drug reaction classification across drug groups
Paper and Code
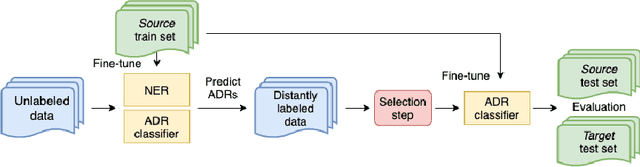
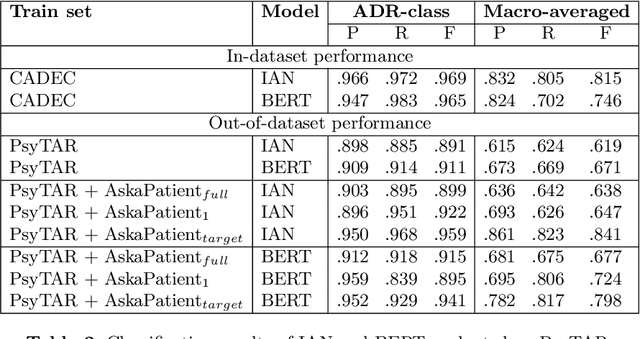
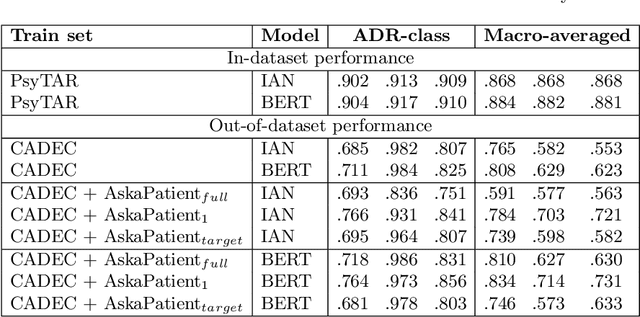
Automatic monitoring of adverse drug events (ADEs) or reactions (ADRs) is currently receiving significant attention from the biomedical community. In recent years, user-generated data on social media has become a valuable resource for this task. Neural models have achieved impressive performance on automatic text classification for ADR detection. Yet, training and evaluation of these methods are carried out on user-generated texts about a targeted drug. In this paper, we assess the robustness of state-of-the-art neural architectures across different drug groups. We investigate several strategies to use pseudo-labeled data in addition to a manually annotated train set. Out-of-dataset experiments diagnose the bottleneck of supervised models in terms of breakdown performance, while additional pseudo-labeled data improves overall results regardless of the text selection strategy.