 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Russian Drug Reaction Corpus and Neural Models for Drug Reactions and Effectiveness Detection in User Reviews
Paper and Code
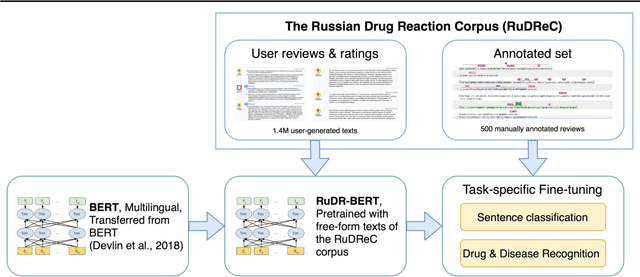
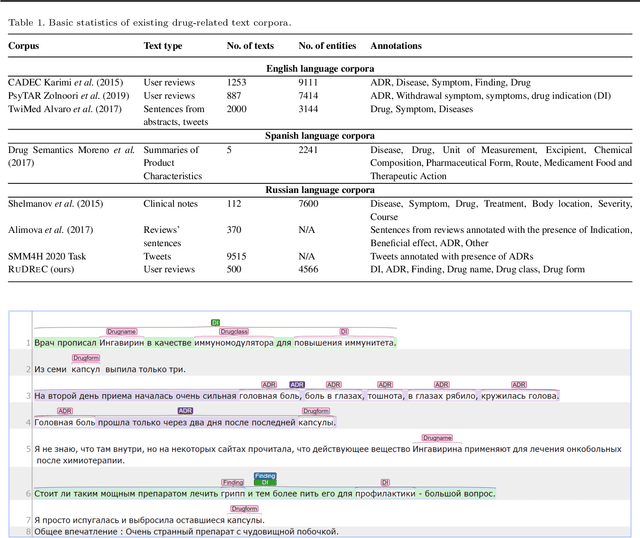
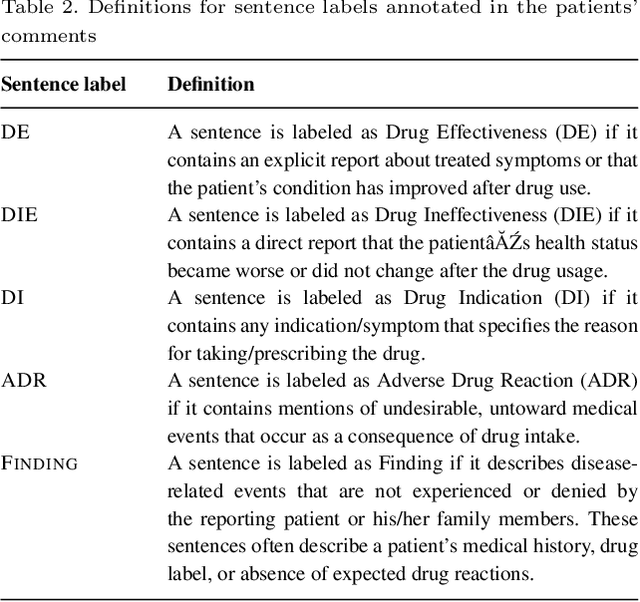
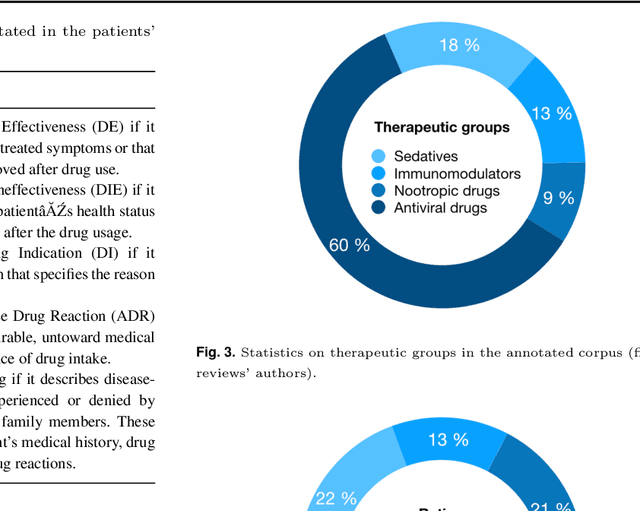
The Russian Drug Reaction Corpus (RuDReC) is a new partially annotated corpus of consumer reviews in Russian about pharmaceutical products for the detection of health-related named entities and the effectiveness of pharmaceutical products. The corpus itself consists of two parts, the raw one and the labelled one. The raw part includes 1.4 million health-related user-generated texts collected from various Internet sources, including social media. The labelled part contains 500 consumer reviews about drug therapy with drug- and disease-related information. Labels for sentences include health-related issues or their absence. The sentences with one are additionally labelled at the expression level for identification of fine-grained subtypes such as drug classes and drug forms, drug indications, and drug reactions. Further, we present a baseline model for named entity recognition (NER) and multi-label sentence classification tasks on this corpus. The macro F1 score of 74.85% in the NER task was achieved by our RuDR-BERT model. For the sentence classification task, our model achieves the macro F1 score of 68.82% gaining 7.47% over the score of BERT model trained on Russian data. We make the RuDReC corpus and pretrained weights of domain-specific BERT models freely available at https://github.com/cimm-kzn/RuDReC