 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERA Code: A Unified Framework for Evaluating Code Generation Across Tasks
Jul 16, 2025Advancements in LLMs have enhanced task automation in software engineering; however, current evaluations primarily focus on natural language tasks, overlooking code quality. Most benchmarks prioritize high-level reasoning over executable code and real-world performance, leaving gaps in understanding true capabilities and risks associated with these models in production. To address this issue, we propose MERA Code, a new addition to the MERA benchmark family, specifically focused on evaluating code for the latest code generation LLMs in Russian. This benchmark includes 11 evaluation tasks that span 8 programming languages. Our proposed evaluation methodology features a taxonomy that outlines the practical coding skills necessary for models to complete these tasks. The benchmark comprises an open-source codebase for users to conduct MERA assessments, a scoring system compatible with various programming environments, and a platform featuring a leaderboard and submission system. We evaluate open LLMs and frontier API models, analyzing their limitations in terms of practical coding tasks in non-English languages. We are publicly releasing MERA to guide future research, anticipate groundbreaking features in model development, and standardize evaluation procedures.
YABLoCo: Yet Another Benchmark for Long Context Code Generation
May 07, 2025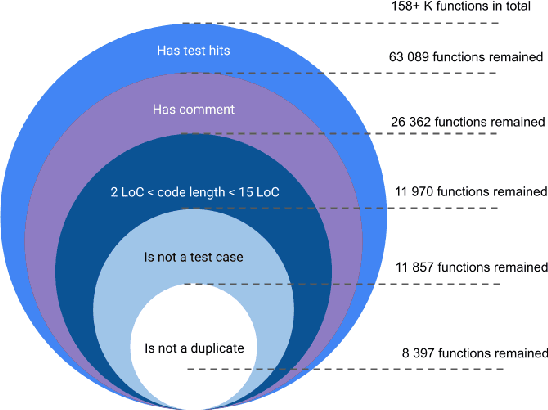
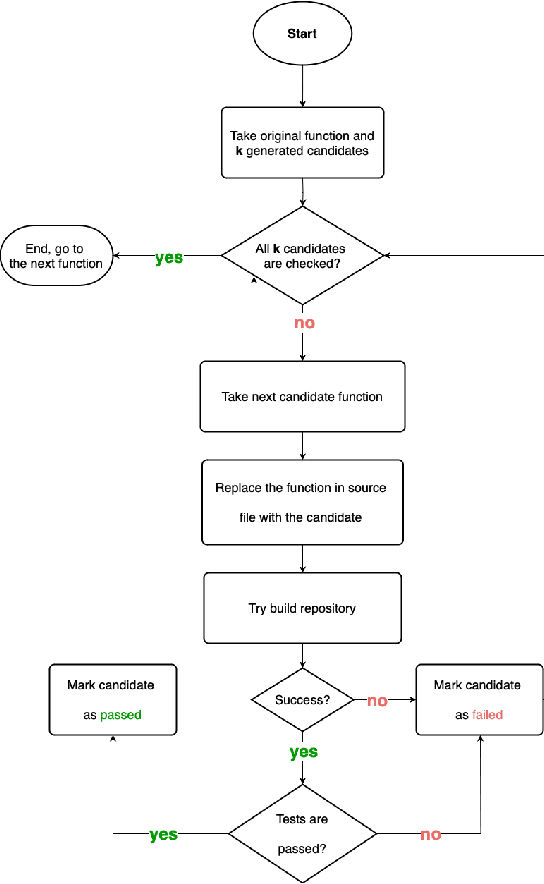
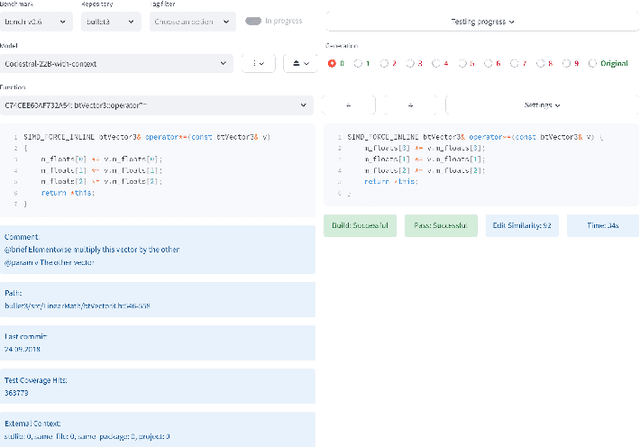
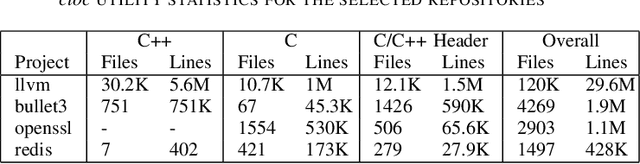
Large Language Models demonstrate the ability to solve various programming tasks, including code generation. Typically, the performance of LLMs is measured on benchmarks with small or medium-sized context windows of thousands of lines of code. At the same time, in real-world software projects, repositories can span up to millions of LoC. This paper closes this gap by contributing to the long context code generation benchmark (YABLoCo). The benchmark featured a test set of 215 functions selected from four large repositories with thousands of functions. The dataset contained metadata of functions, contexts of the functions with different levels of dependencies, docstrings, functions bodies, and call graphs for each repository. This paper presents three key aspects of the contribution. First, the benchmark aims at function body generation in large repositories in C and C++, two languages not covered by previous benchmarks. Second, the benchmark contains large repositories from 200K to 2,000K LoC. Third, we contribute a scalable evaluation pipeline for efficient computing of the target metrics and a tool for visual analysis of generated code. Overall, these three aspects allow for evaluating code generation in large repositories in C and C++.
Leveraging Large Language Models in Code Question Answering: Baselines and Issues
Nov 05, 2024
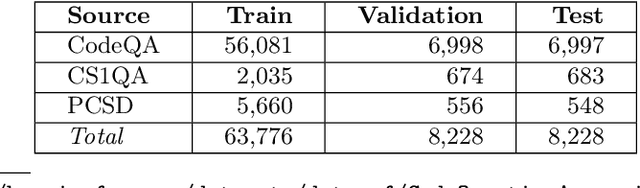
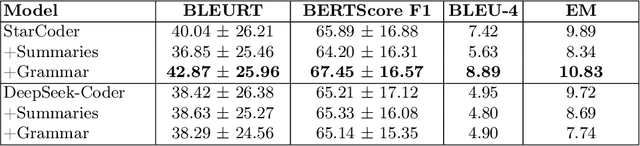
Question answering over source code provides software engineers and project managers with helpful information about the implemented features of a software product. This paper presents a work devoted to using large language models for question answering over source code in Python. The proposed method for implementing a source code question answering system involves fine-tuning a large language model on a unified dataset of questions and answers for Python code. To achieve the highest quality answers, we tested various models trained on datasets preprocessed in different ways: a dataset without grammar correction, a dataset with grammar correction, and a dataset augmented with the generated summaries. The model answers were also analyzed for errors manually. We report BLEU-4, BERTScore F1, BLEURT, and Exact Match metric values, along with the conclusions from the manual error analysis. The obtained experimental results highlight the current problems of the research area, such as poor quality of the public genuine question-answering datasets. In addition, the findings include the positive effect of the grammar correction of the training data on the testing metric values. The addressed findings and issues could be important for other researchers who attempt to improve the quality of source code question answering solutions. The training and evaluation code is publicly available at https://github.com/IU-AES-AI4Code/CodeQuestionAnswering.
Experiments with LVT and FRE for Transformer model
Apr 26, 2020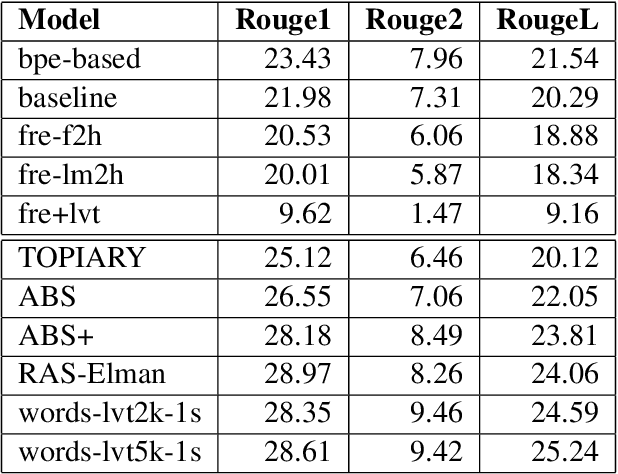
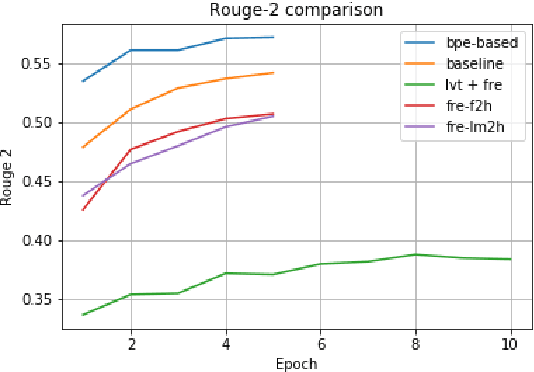
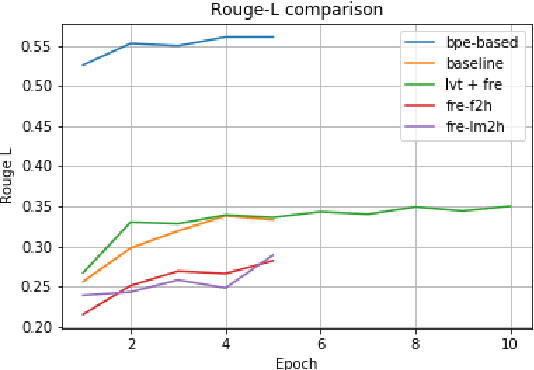
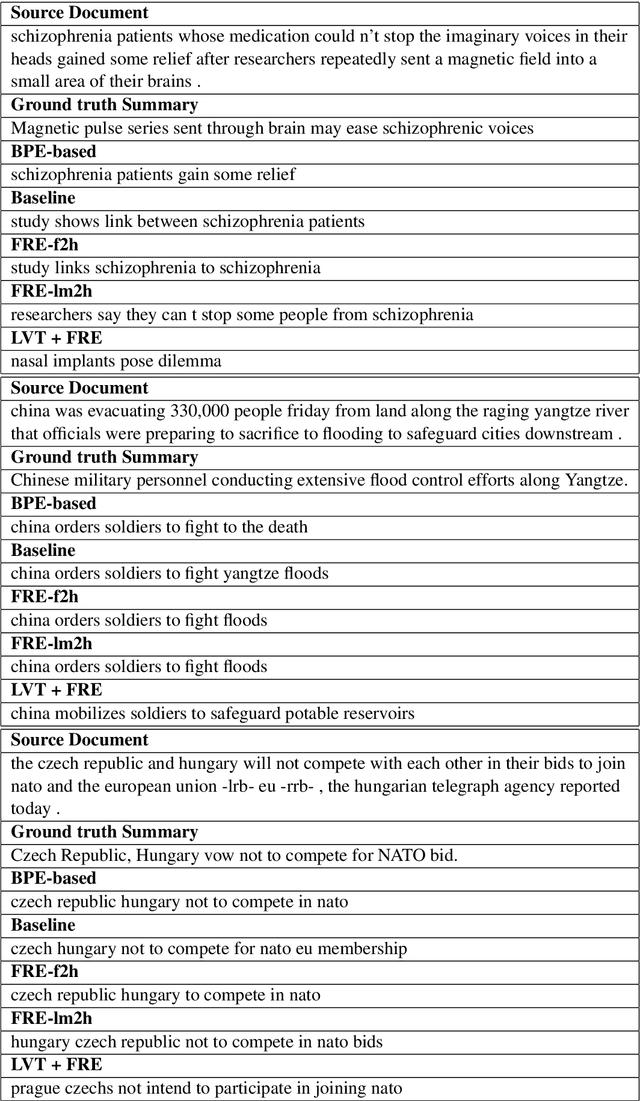
In this paper, we experiment with Large Vocabulary Trick and Feature-rich encoding applied to the Transformer model for Text Summarization. We could not achieve better results, than the analogous RNN-based sequence-to-sequence model, so we tried more models to find out, what improves the results and what deteriorates them.
A Survey of Methods to Leverage Monolingual Data in Low-resource Neural Machine Translation
Oct 01, 2019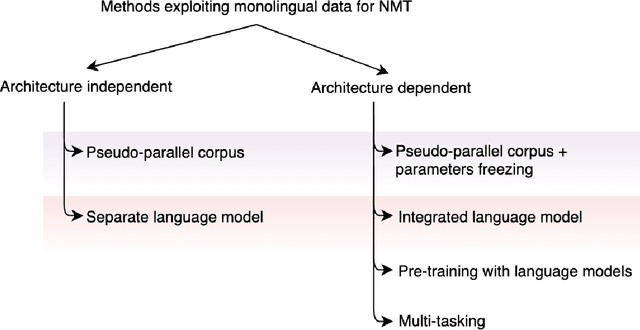
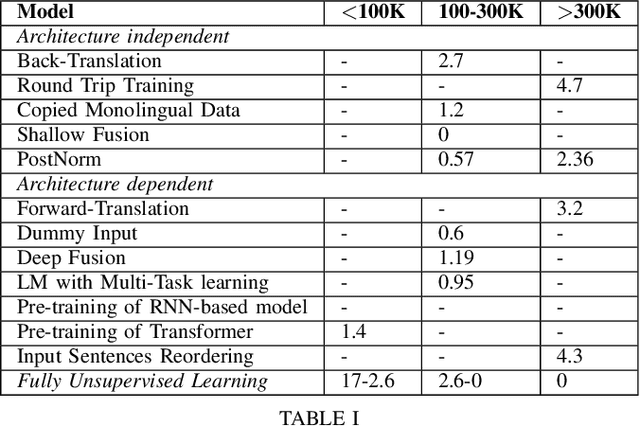
Neural machine translation has become the state-of-the-art for language pairs with large parallel corpora. However, the quality of machine translation for low-resource languages leaves much to be desired. There are several approaches to mitigate this problem, such as transfer learning, semi-supervised and unsupervised learning techniques. In this paper, we review the existing methods, where the main idea is to exploit the power of monolingual data, which, compared to parallel, is usually easier to obtain and significantly greater in amount.
Application of Low-resource Machine Translation Techniques to Russian-Tatar Language Pair
Oct 01, 2019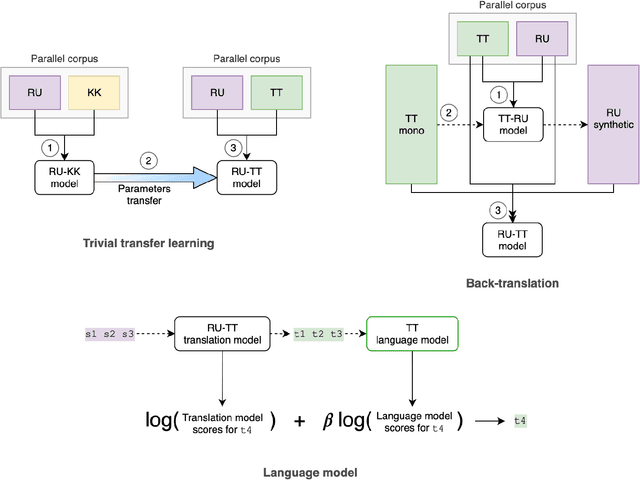
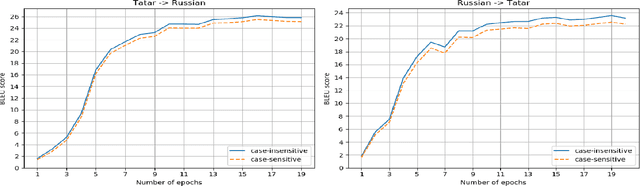
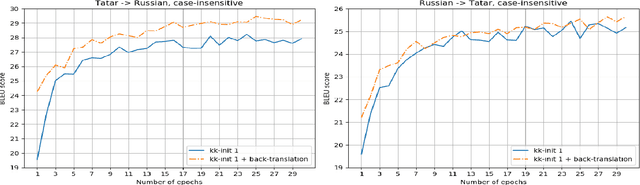
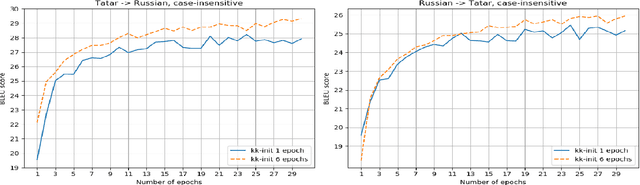
Neural machine translation is the current state-of-the-art in machine translation. Although it is successful in a resource-rich setting, its applicability for low-resource language pairs is still debatable. In this paper, we explore the effect of different techniques to improve machine translation quality when a parallel corpus is as small as 324 000 sentences, taking as an example previously unexplored Russian-Tatar language pair. We apply such techniques as transfer learning and semi-supervised learning to the base Transformer model, and empirically show that the resulting models improve Russian to Tatar and Tatar to Russian translation quality by +2.57 and +3.66 BLEU, respectively.