Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperiments with LVT and FRE for Transformer model
Paper and Code
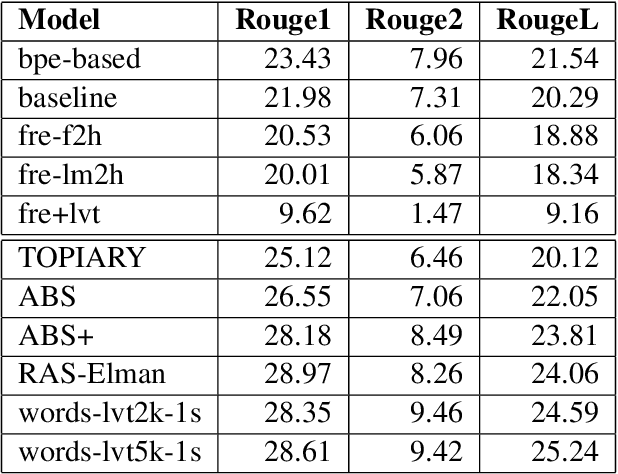
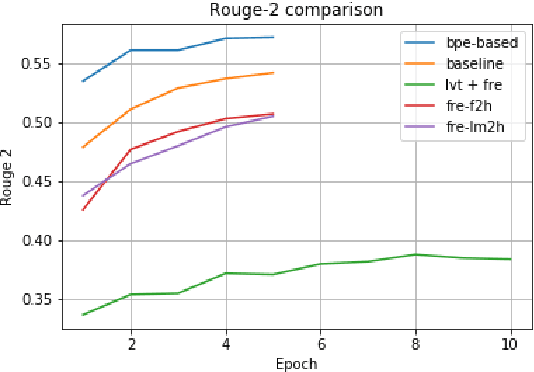
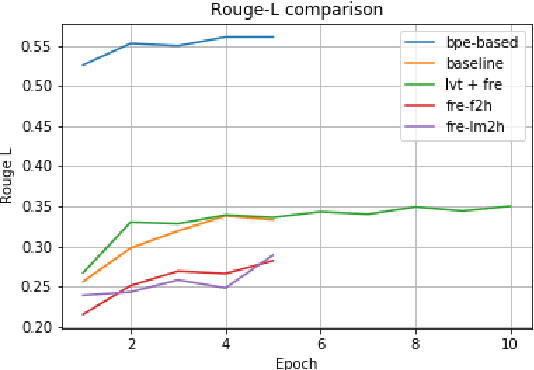
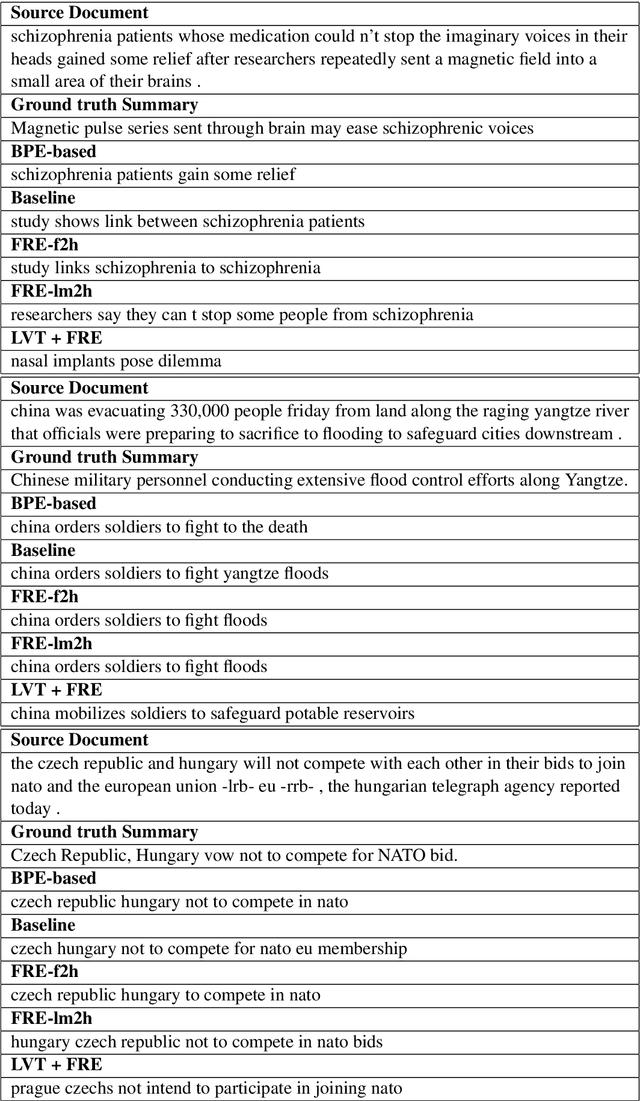
In this paper, we experiment with Large Vocabulary Trick and Feature-rich encoding applied to the Transformer model for Text Summarization. We could not achieve better results, than the analogous RNN-based sequence-to-sequence model, so we tried more models to find out, what improves the results and what deteriorates them.
View paper on