 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperiments with LVT and FRE for Transformer model
Apr 26, 2020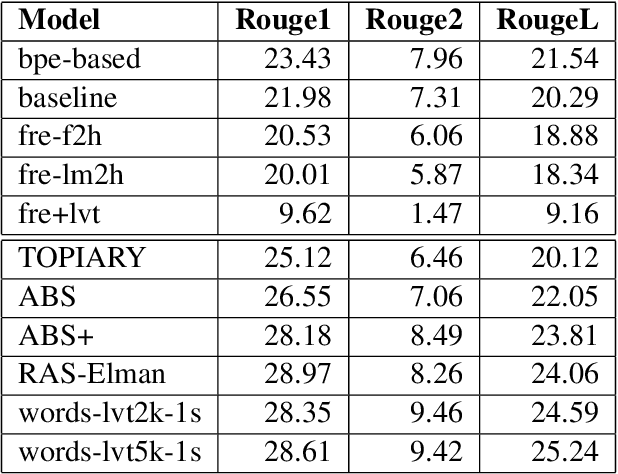
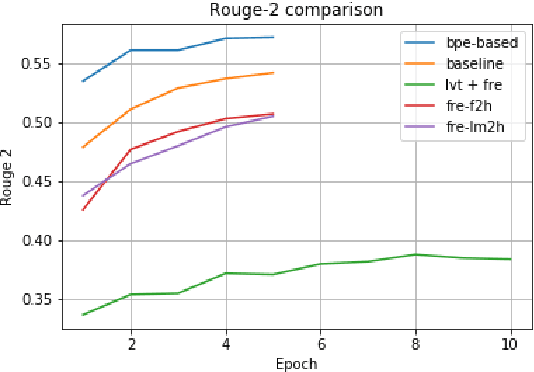
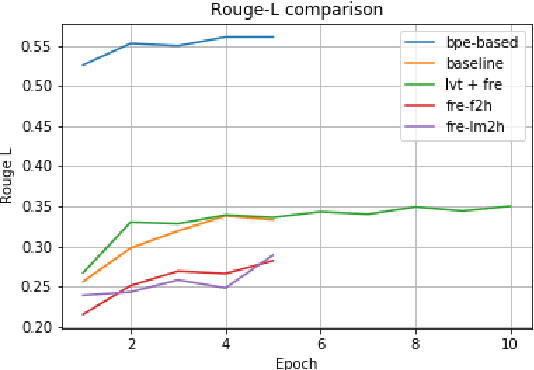
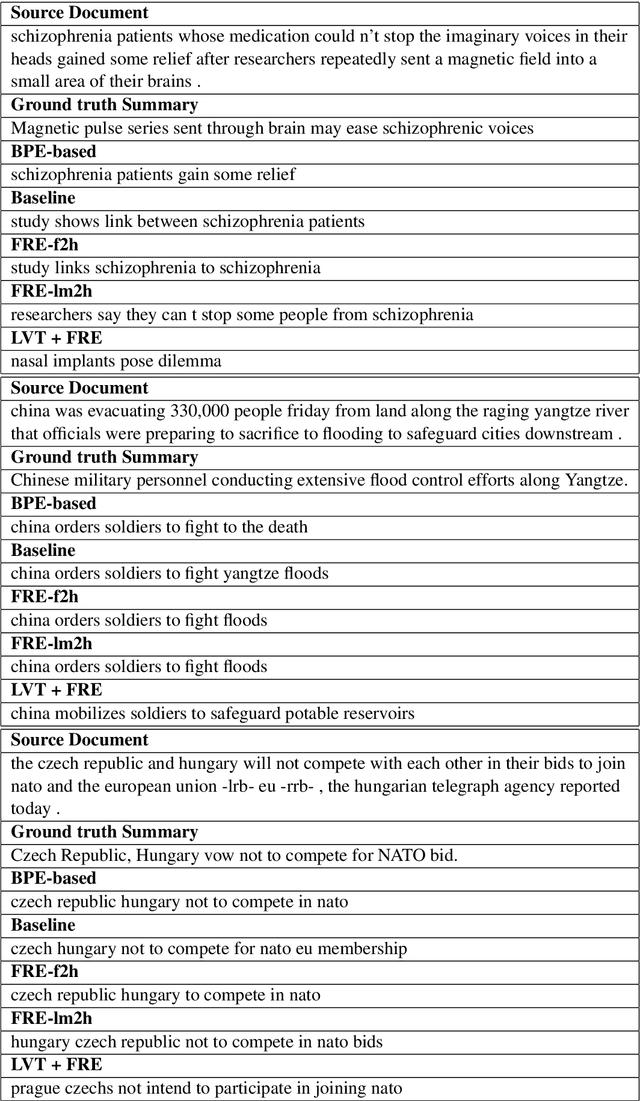
In this paper, we experiment with Large Vocabulary Trick and Feature-rich encoding applied to the Transformer model for Text Summarization. We could not achieve better results, than the analogous RNN-based sequence-to-sequence model, so we tried more models to find out, what improves the results and what deteriorates them.
A Survey of Methods to Leverage Monolingual Data in Low-resource Neural Machine Translation
Oct 01, 2019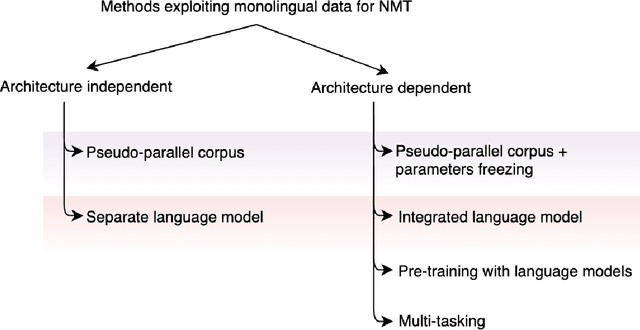
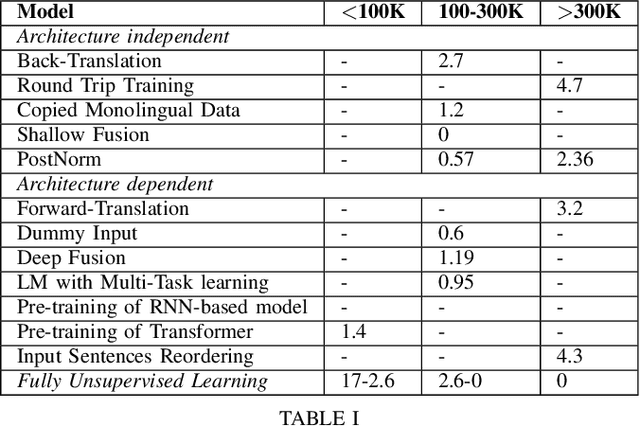
Neural machine translation has become the state-of-the-art for language pairs with large parallel corpora. However, the quality of machine translation for low-resource languages leaves much to be desired. There are several approaches to mitigate this problem, such as transfer learning, semi-supervised and unsupervised learning techniques. In this paper, we review the existing methods, where the main idea is to exploit the power of monolingual data, which, compared to parallel, is usually easier to obtain and significantly greater in amount.
Application of Low-resource Machine Translation Techniques to Russian-Tatar Language Pair
Oct 01, 2019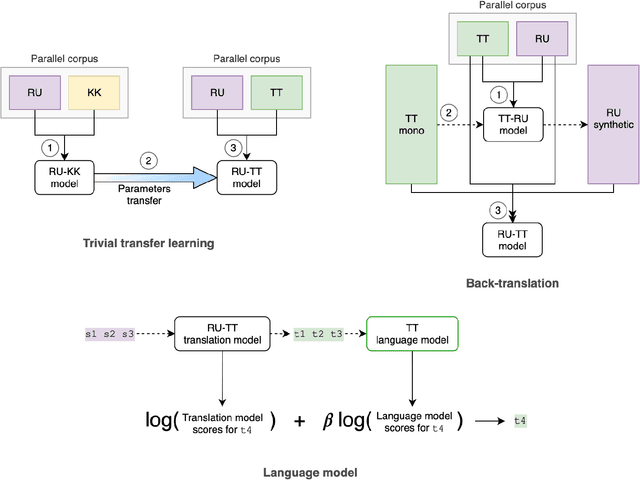
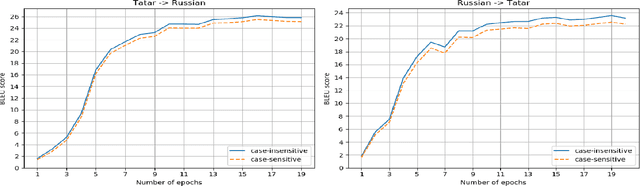
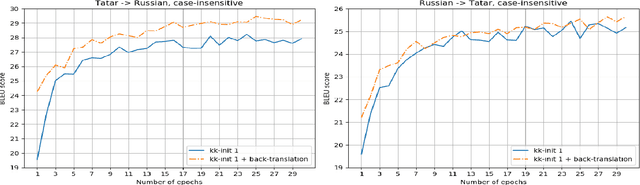
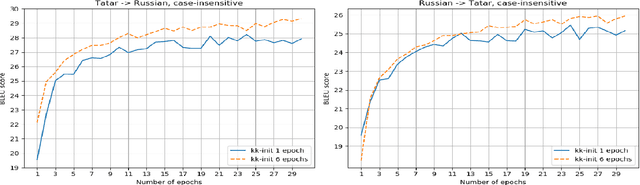
Neural machine translation is the current state-of-the-art in machine translation. Although it is successful in a resource-rich setting, its applicability for low-resource language pairs is still debatable. In this paper, we explore the effect of different techniques to improve machine translation quality when a parallel corpus is as small as 324 000 sentences, taking as an example previously unexplored Russian-Tatar language pair. We apply such techniques as transfer learning and semi-supervised learning to the base Transformer model, and empirically show that the resulting models improve Russian to Tatar and Tatar to Russian translation quality by +2.57 and +3.66 BLEU, respectively.