Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Methods to Leverage Monolingual Data in Low-resource Neural Machine Translation
Paper and Code
Oct 01, 2019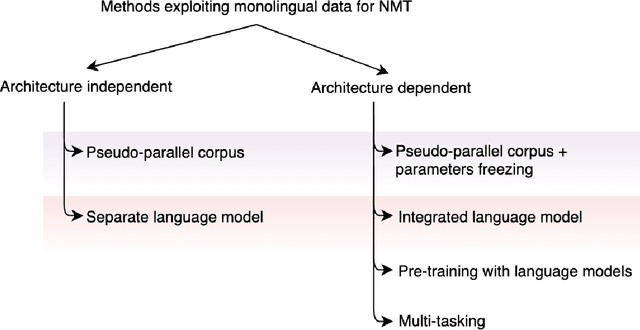
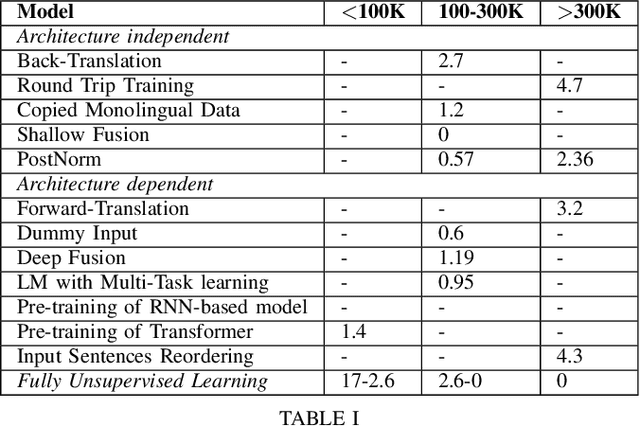
Neural machine translation has become the state-of-the-art for language pairs with large parallel corpora. However, the quality of machine translation for low-resource languages leaves much to be desired. There are several approaches to mitigate this problem, such as transfer learning, semi-supervised and unsupervised learning techniques. In this paper, we review the existing methods, where the main idea is to exploit the power of monolingual data, which, compared to parallel, is usually easier to obtain and significantly greater in amount.
* Presented in ICATHS'19
View paper on