Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Low-resource Machine Translation Techniques to Russian-Tatar Language Pair
Paper and Code
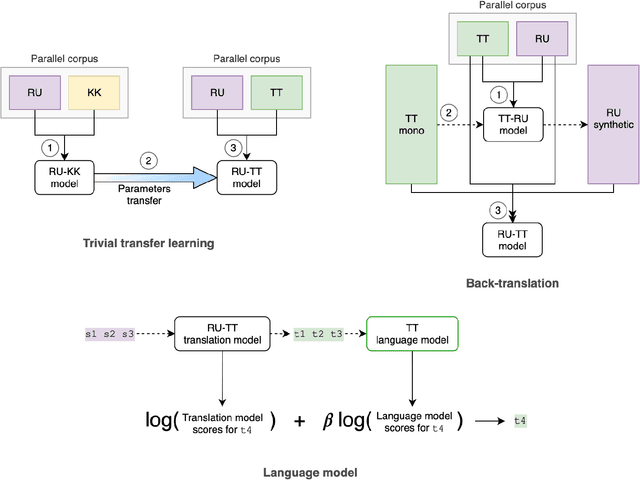
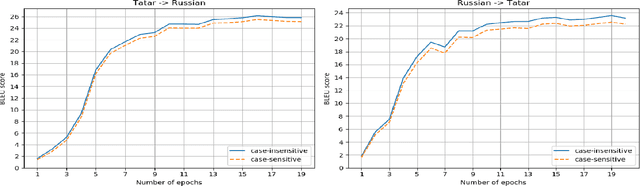
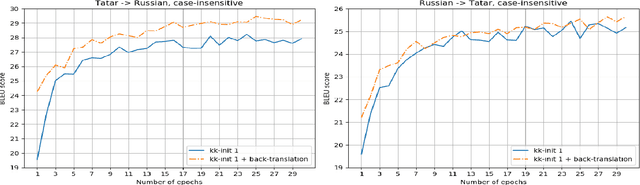
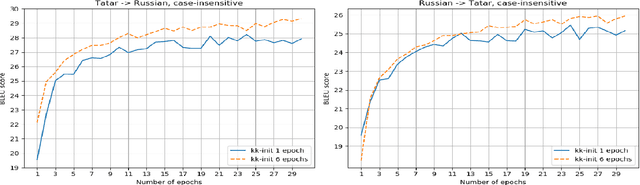
Neural machine translation is the current state-of-the-art in machine translation. Although it is successful in a resource-rich setting, its applicability for low-resource language pairs is still debatable. In this paper, we explore the effect of different techniques to improve machine translation quality when a parallel corpus is as small as 324 000 sentences, taking as an example previously unexplored Russian-Tatar language pair. We apply such techniques as transfer learning and semi-supervised learning to the base Transformer model, and empirically show that the resulting models improve Russian to Tatar and Tatar to Russian translation quality by +2.57 and +3.66 BLEU, respectively.
* Presented on ICATHS'19
View paper on