 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
Feb 15, 2024



We introduce a text-to-speech (TTS) model called BASE TTS, which stands for $\textbf{B}$ig $\textbf{A}$daptive $\textbf{S}$treamable TTS with $\textbf{E}$mergent abilities. BASE TTS is the largest TTS model to-date, trained on 100K hours of public domain speech data, achieving a new state-of-the-art in speech naturalness. It deploys a 1-billion-parameter autoregressive Transformer that converts raw texts into discrete codes ("speechcodes") followed by a convolution-based decoder which converts these speechcodes into waveforms in an incremental, streamable manner. Further, our speechcodes are built using a novel speech tokenization technique that features speaker ID disentanglement and compression with byte-pair encoding. Echoing the widely-reported "emergent abilities" of large language models when trained on increasing volume of data, we show that BASE TTS variants built with 10K+ hours and 500M+ parameters begin to demonstrate natural prosody on textually complex sentences. We design and share a specialized dataset to measure these emergent abilities for text-to-speech. We showcase state-of-the-art naturalness of BASE TTS by evaluating against baselines that include publicly available large-scale text-to-speech systems: YourTTS, Bark and TortoiseTTS. Audio samples generated by the model can be heard at https://amazon-ltts-paper.com/.
Controllable Emphasis with zero data for text-to-speech
Jul 13, 2023We present a scalable method to produce high quality emphasis for text-to-speech (TTS) that does not require recordings or annotations. Many TTS models include a phoneme duration model. A simple but effective method to achieve emphasized speech consists in increasing the predicted duration of the emphasised word. We show that this is significantly better than spectrogram modification techniques improving naturalness by $7.3\%$ and correct testers' identification of the emphasized word in a sentence by $40\%$ on a reference female en-US voice. We show that this technique significantly closes the gap to methods that require explicit recordings. The method proved to be scalable and preferred in all four languages tested (English, Spanish, Italian, German), for different voices and multiple speaking styles.
Whole-body PET image denoising for reduced acquisition time
Mar 28, 2023

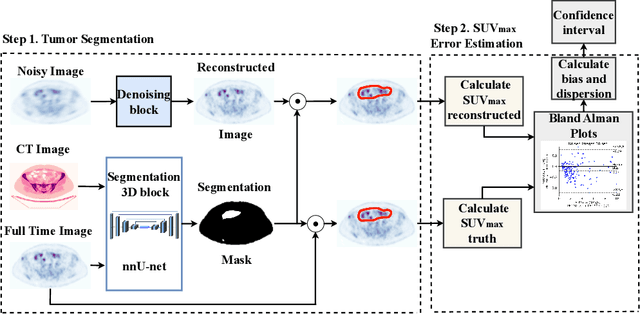
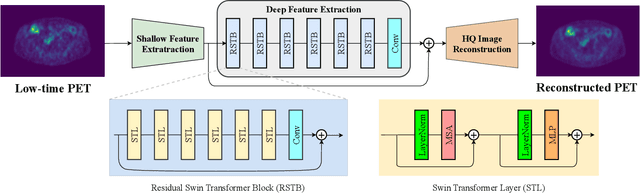
This paper evaluates the performance of supervised and unsupervised deep learning models for denoising positron emission tomography (PET) images in the presence of reduced acquisition times. Our experiments consider 212 studies (56908 images), and evaluate the models using 2D (RMSE, SSIM) and 3D (SUVpeak and SUVmax error for the regions of interest) metrics. It was shown that, in contrast to previous studies, supervised models (ResNet, Unet, SwinIR) outperform unsupervised models (pix2pix GAN and CycleGAN with ResNet backbone and various auxiliary losses) in the reconstruction of 2D PET images. Moreover, a hybrid approach of supervised CycleGAN shows the best results in SUVmax estimation for denoised images, and the SUVmax estimation error for denoised images is comparable with the PET reproducibility error.
Distribution augmentation for low-resource expressive text-to-speech
Feb 19, 2022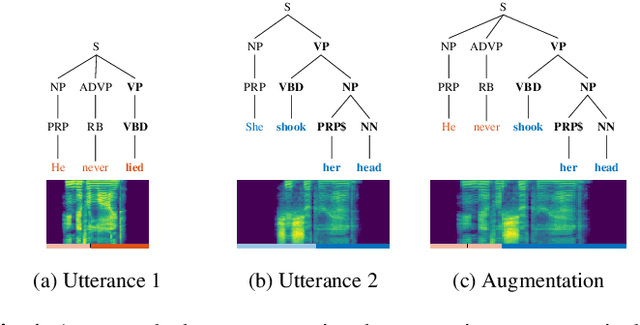
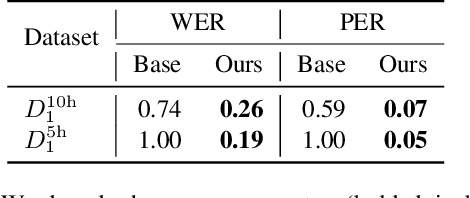
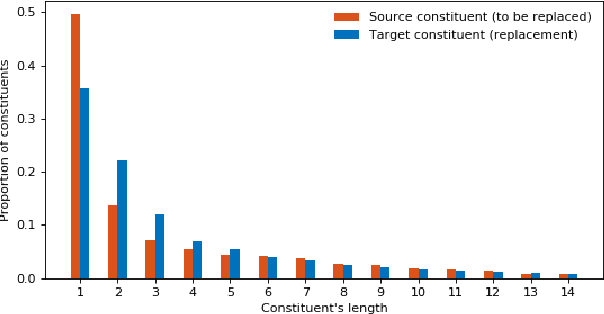
This paper presents a novel data augmentation technique for text-to-speech (TTS), that allows to generate new (text, audio) training examples without requiring any additional data. Our goal is to increase diversity of text conditionings available during training. This helps to reduce overfitting, especially in low-resource settings. Our method relies on substituting text and audio fragments in a way that preserves syntactical correctness. We take additional measures to ensure that synthesized speech does not contain artifacts caused by combining inconsistent audio samples. The perceptual evaluations show that our method improves speech quality over a number of datasets, speakers, and TTS architectures. We also demonstrate that it greatly improves robustness of attention-based TTS models.
CoRSAI: A System for Robust Interpretation of CT Scans of COVID-19 Patients Using Deep Learning
May 25, 2021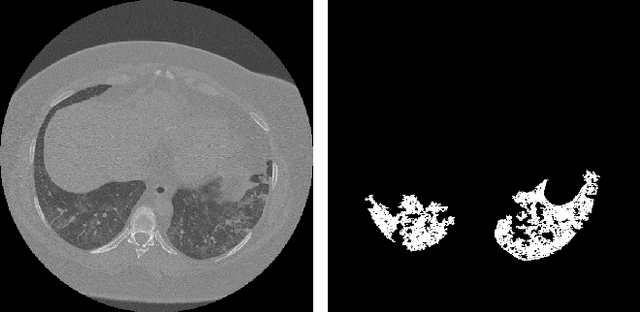


Analysis of chest CT scans can be used in detecting parts of lungs that are affected by infectious diseases such as COVID-19.Determining the volume of lungs affected by lesions is essential for formulating treatment recommendations and prioritizingpatients by severity of the disease. In this paper we adopted an approach based on using an ensemble of deep convolutionalneural networks for segmentation of slices of lung CT scans. Using our models we are able to segment the lesions, evaluatepatients dynamics, estimate relative volume of lungs affected by lesions and evaluate the lung damage stage. Our modelswere trained on data from different medical centers. We compared predictions of our models with those of six experiencedradiologists and our segmentation model outperformed most of them. On the task of classification of disease severity, ourmodel outperformed all the radiologists.
Noise-Resilient Automatic Interpretation of Holter ECG Recordings
Nov 17, 2020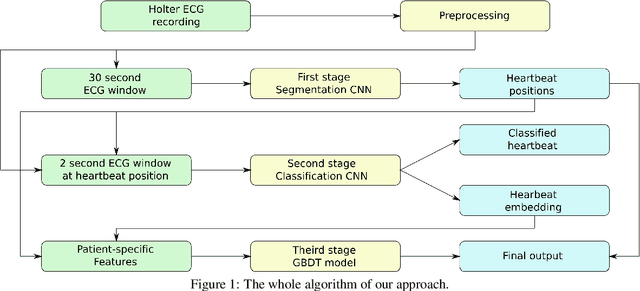
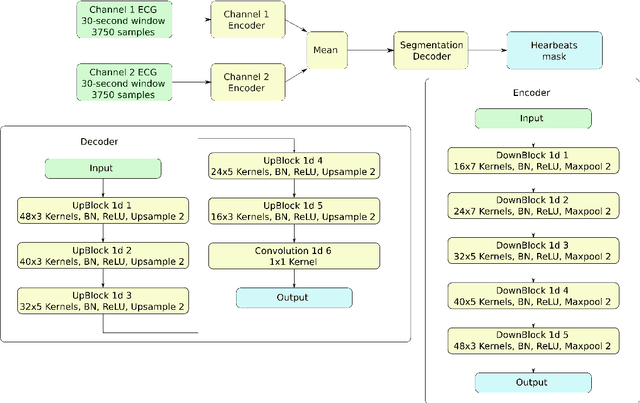
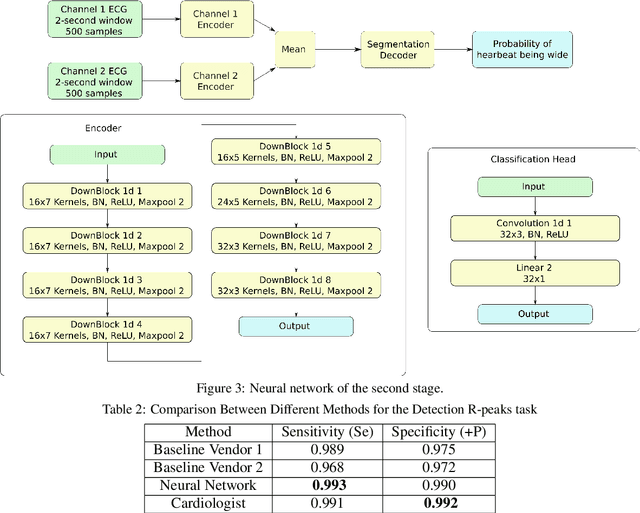
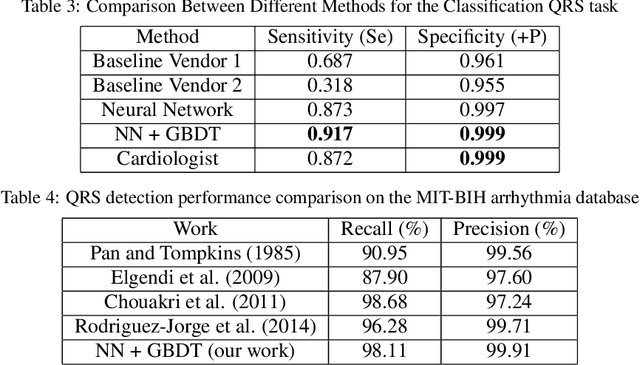
Holter monitoring, a long-term ECG recording (24-hours and more), contains a large amount of valuable diagnostic information about the patient. Its interpretation becomes a difficult and time-consuming task for the doctor who analyzes them because every heartbeat needs to be classified, thus requiring highly accurate methods for automatic interpretation. In this paper, we present a three-stage process for analysing Holter recordings with robustness to noisy signal. First stage is a segmentation neural network (NN) with encoderdecoder architecture which detects positions of heartbeats. Second stage is a classification NN which will classify heartbeats as wide or narrow. Third stage in gradient boosting decision trees (GBDT) on top of NN features that incorporates patient-wise features and further increases performance of our approach. As a part of this work we acquired 5095 Holter recordings of patients annotated by an experienced cardiologist. A committee of three cardiologists served as a ground truth annotators for the 291 examples in the test set. We show that the proposed method outperforms the selected baselines, including two commercial-grade software packages and some methods previously published in the literature.