 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
Feb 15, 2024



We introduce a text-to-speech (TTS) model called BASE TTS, which stands for $\textbf{B}$ig $\textbf{A}$daptive $\textbf{S}$treamable TTS with $\textbf{E}$mergent abilities. BASE TTS is the largest TTS model to-date, trained on 100K hours of public domain speech data, achieving a new state-of-the-art in speech naturalness. It deploys a 1-billion-parameter autoregressive Transformer that converts raw texts into discrete codes ("speechcodes") followed by a convolution-based decoder which converts these speechcodes into waveforms in an incremental, streamable manner. Further, our speechcodes are built using a novel speech tokenization technique that features speaker ID disentanglement and compression with byte-pair encoding. Echoing the widely-reported "emergent abilities" of large language models when trained on increasing volume of data, we show that BASE TTS variants built with 10K+ hours and 500M+ parameters begin to demonstrate natural prosody on textually complex sentences. We design and share a specialized dataset to measure these emergent abilities for text-to-speech. We showcase state-of-the-art naturalness of BASE TTS by evaluating against baselines that include publicly available large-scale text-to-speech systems: YourTTS, Bark and TortoiseTTS. Audio samples generated by the model can be heard at https://amazon-ltts-paper.com/.
Simple and Effective Multi-sentence TTS with Expressive and Coherent Prosody
Jun 29, 2022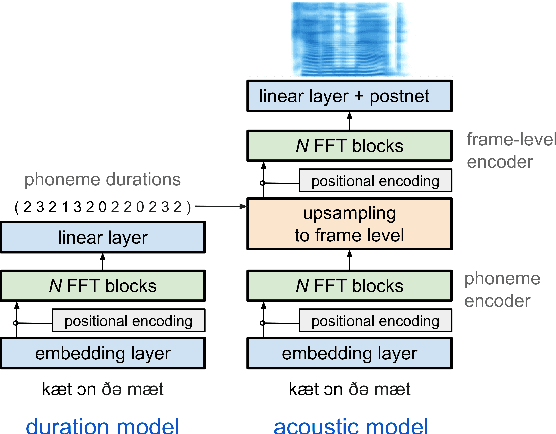

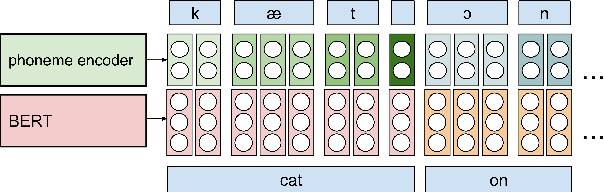
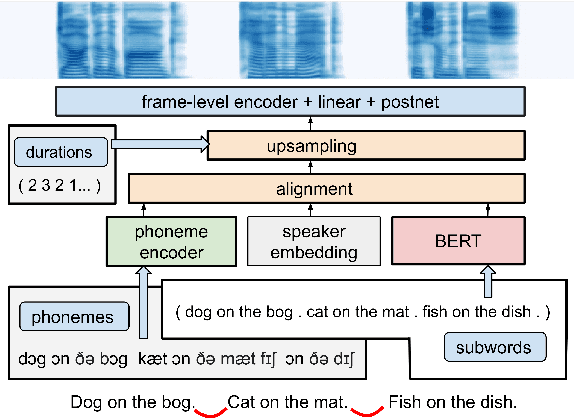
Generating expressive and contextually appropriate prosody remains a challenge for modern text-to-speech (TTS) systems. This is particularly evident for long, multi-sentence inputs. In this paper, we examine simple extensions to a Transformer-based FastSpeech-like system, with the goal of improving prosody for multi-sentence TTS. We find that long context, powerful text features, and training on multi-speaker data all improve prosody. More interestingly, they result in synergies. Long context disambiguates prosody, improves coherence, and plays to the strengths of Transformers. Fine-tuning word-level features from a powerful language model, such as BERT, appears to profit from more training data, readily available in a multi-speaker setting. We look into objective metrics on pausing and pacing and perform thorough subjective evaluations for speech naturalness. Our main system, which incorporates all the extensions, achieves consistently strong results, including statistically significant improvements in speech naturalness over all its competitors.
Discrete acoustic space for an efficient sampling in neural text-to-speech
Oct 24, 2021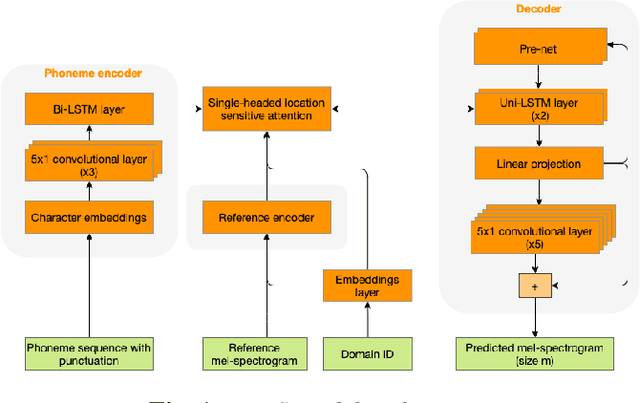
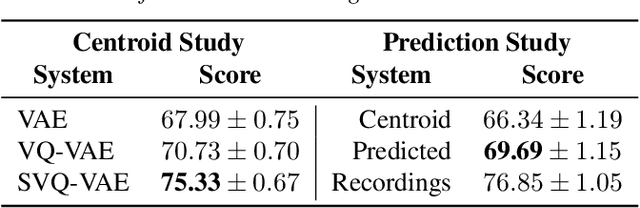
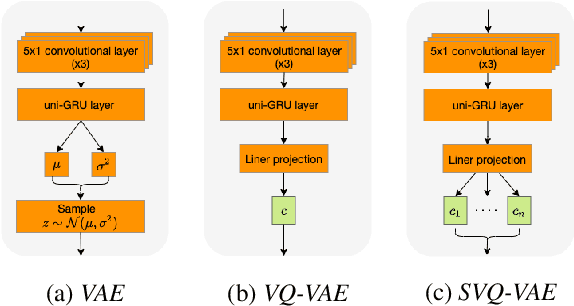
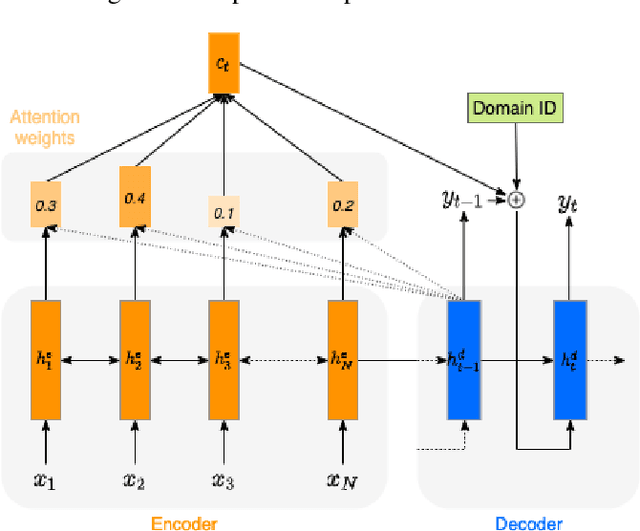
We present an SVQ-VAE architecture using a split vector quantizer for NTTS, as an enhancement to the well-known VAE and VQ-VAE architectures. Compared to these previous architectures, our proposed model retains the benefits of using an utterance-level bottleneck, while reducing the associated loss of representation power. We train the model on recordings in the highly expressive task-oriented dialogues domain and show that SVQ-VAE achieves a statistically significant improvement in naturalness over the VAE and VQ-VAE models. Furthermore, we demonstrate that the SVQ-VAE acoustic space is predictable from text, reducing the gap between the standard constant vector synthesis and vocoded recordings by 32%.
In Other News: A Bi-style Text-to-speech Model for Synthesizing Newscaster Voice with Limited Data
Apr 04, 2019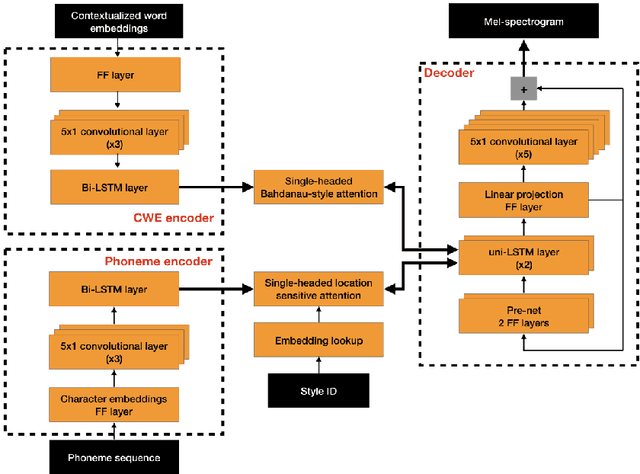
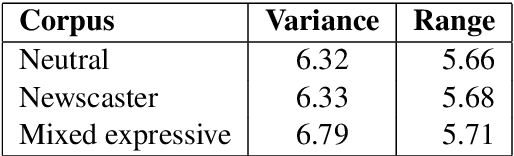

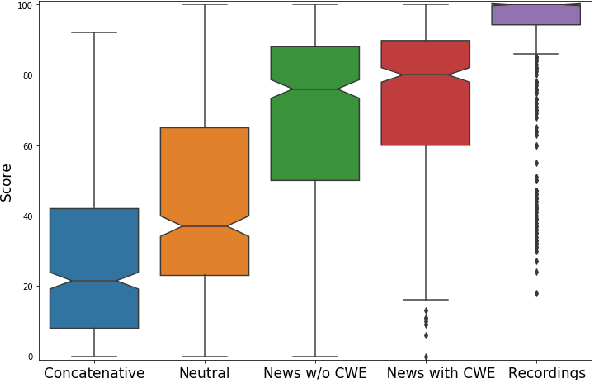
Neural text-to-speech synthesis (NTTS) models have shown significant progress in generating high-quality speech, however they require a large quantity of training data. This makes creating models for multiple styles expensive and time-consuming. In this paper different styles of speech are analysed based on prosodic variations, from this a model is proposed to synthesise speech in the style of a newscaster, with just a few hours of supplementary data. We pose the problem of synthesising in a target style using limited data as that of creating a bi-style model that can synthesise both neutral-style and newscaster-style speech via a one-hot vector which factorises the two styles. We also propose conditioning the model on contextual word embeddings, and extensively evaluate it against neutral NTTS, and neutral concatenative-based synthesis. This model closes the gap in perceived style-appropriateness between natural recordings for newscaster-style of speech, and neutral speech synthesis by approximately two-thirds.