 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOFFIN TTS: Few-Shot Speaker Adaptation by Bayesian Optimization
Feb 04, 2020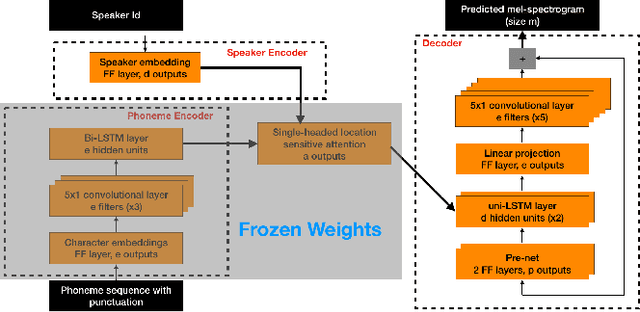

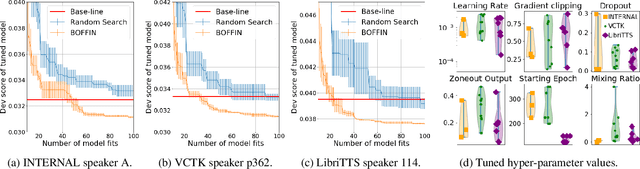
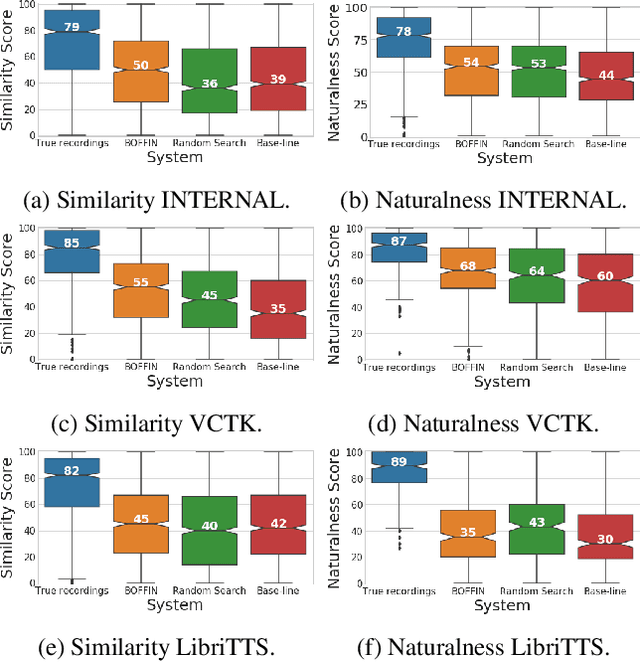
We present BOFFIN TTS (Bayesian Optimization For FIne-tuning Neural Text To Speech), a novel approach for few-shot speaker adaptation. Here, the task is to fine-tune a pre-trained TTS model to mimic a new speaker using a small corpus of target utterances. We demonstrate that there does not exist a one-size-fits-all adaptation strategy, with convincing synthesis requiring a corpus-specific configuration of the hyper-parameters that control fine-tuning. By using Bayesian optimization to efficiently optimize these hyper-parameter values for a target speaker, we are able to perform adaptation with an average 30% improvement in speaker similarity over standard techniques. Results indicate, across multiple corpora, that BOFFIN TTS can learn to synthesize new speakers using less than ten minutes of audio, achieving the same naturalness as produced for the speakers used to train the base model.
Using VAEs and Normalizing Flows for One-shot Text-To-Speech Synthesis of Expressive Speech
Nov 28, 2019
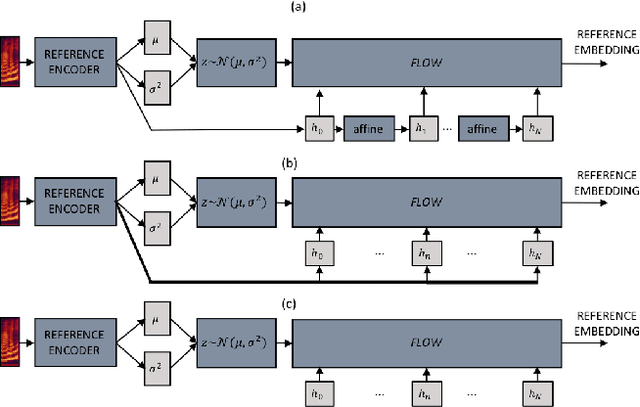


We propose a Text-to-Speech method to create an unseen expressive style using one utterance of expressive speech of around one second. Specifically, we enhance the disentanglement capabilities of a state-of-the-art sequence-to-sequence based system with a Variational AutoEncoder (VAE) and a Householder Flow. The proposed system provides a 22% KL-divergence reduction while jointly improving perceptual metrics over state-of-the-art. At synthesis time we use one example of expressive style as a reference input to the encoder for generating any text in the desired style. Perceptual MUSHRA evaluations show that we can create a voice with a 9% relative naturalness improvement over standard Neural Text-to-Speech, while also improving the perceived emotional intensity (59 compared to the 55 of neutral speech).
In Other News: A Bi-style Text-to-speech Model for Synthesizing Newscaster Voice with Limited Data
Apr 04, 2019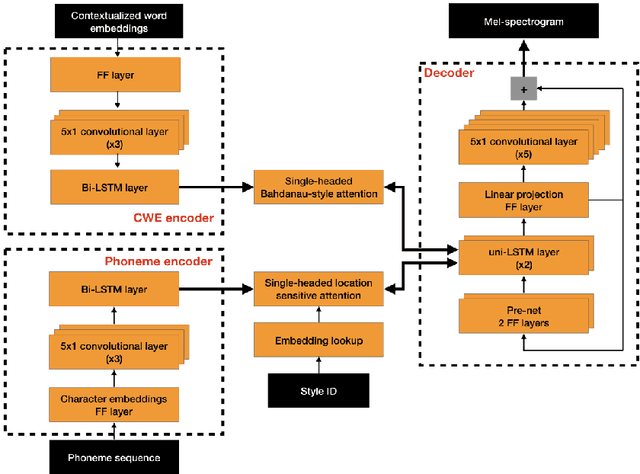
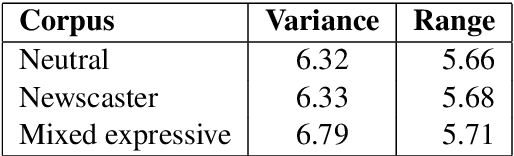

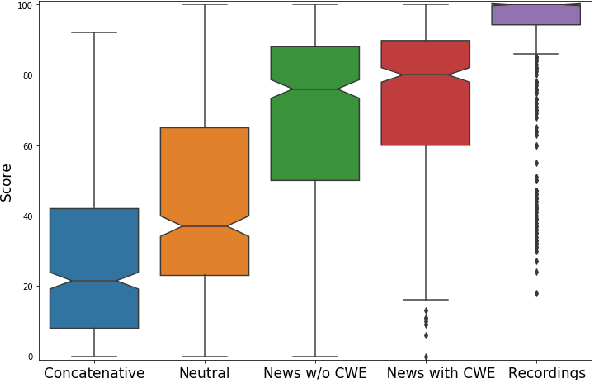
Neural text-to-speech synthesis (NTTS) models have shown significant progress in generating high-quality speech, however they require a large quantity of training data. This makes creating models for multiple styles expensive and time-consuming. In this paper different styles of speech are analysed based on prosodic variations, from this a model is proposed to synthesise speech in the style of a newscaster, with just a few hours of supplementary data. We pose the problem of synthesising in a target style using limited data as that of creating a bi-style model that can synthesise both neutral-style and newscaster-style speech via a one-hot vector which factorises the two styles. We also propose conditioning the model on contextual word embeddings, and extensively evaluate it against neutral NTTS, and neutral concatenative-based synthesis. This model closes the gap in perceived style-appropriateness between natural recordings for newscaster-style of speech, and neutral speech synthesis by approximately two-thirds.