 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOFFIN TTS: Few-Shot Speaker Adaptation by Bayesian Optimization
Paper and Code
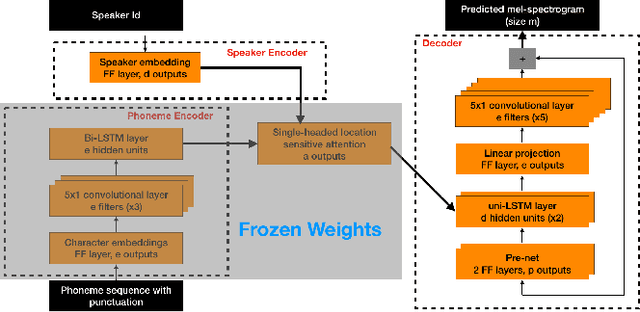

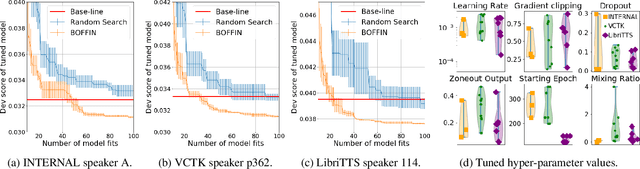
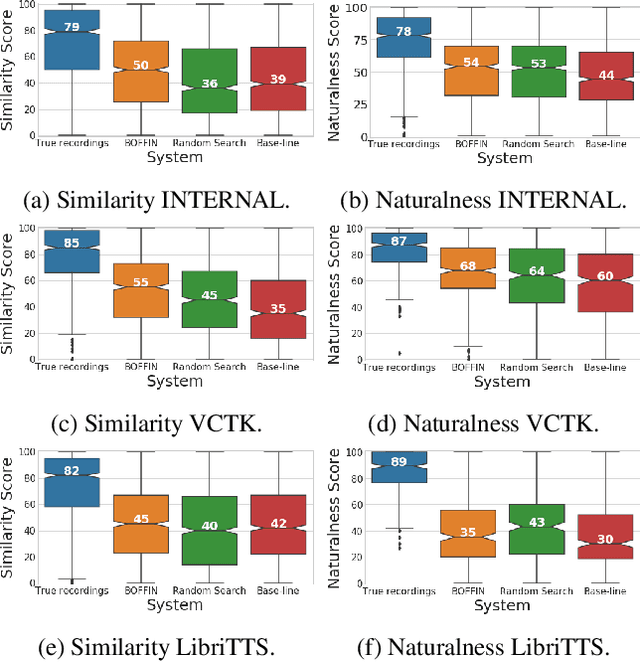
We present BOFFIN TTS (Bayesian Optimization For FIne-tuning Neural Text To Speech), a novel approach for few-shot speaker adaptation. Here, the task is to fine-tune a pre-trained TTS model to mimic a new speaker using a small corpus of target utterances. We demonstrate that there does not exist a one-size-fits-all adaptation strategy, with convincing synthesis requiring a corpus-specific configuration of the hyper-parameters that control fine-tuning. By using Bayesian optimization to efficiently optimize these hyper-parameter values for a target speaker, we are able to perform adaptation with an average 30% improvement in speaker similarity over standard techniques. Results indicate, across multiple corpora, that BOFFIN TTS can learn to synthesize new speakers using less than ten minutes of audio, achieving the same naturalness as produced for the speakers used to train the base model.