 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Privacy and Security of Autonomous UAV Navigation
Apr 26, 2024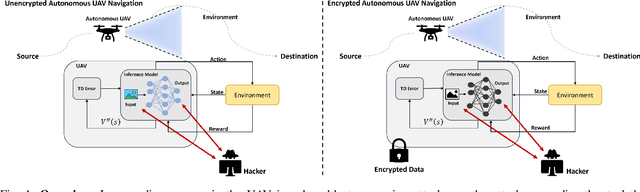
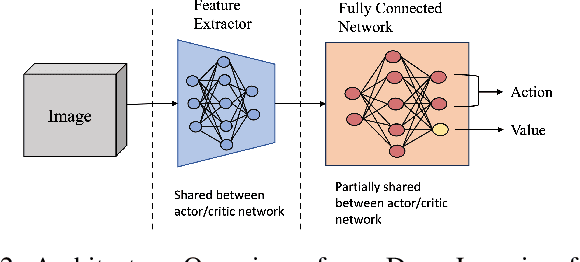
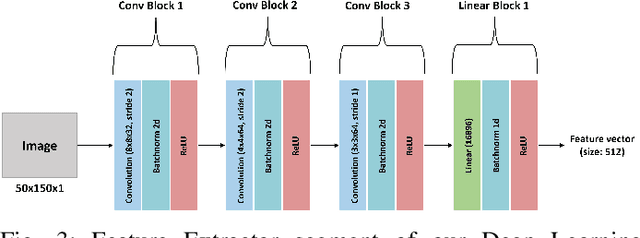
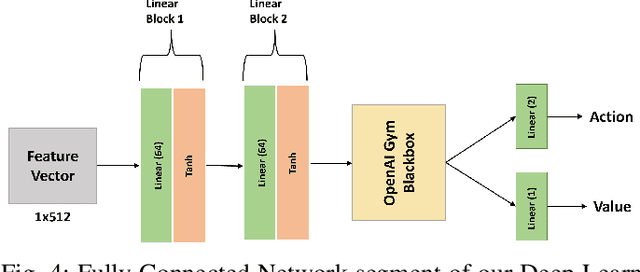
Autonomous Unmanned Aerial Vehicles (UAVs) have become essential tools in defense, law enforcement, disaster response, and product delivery. These autonomous navigation systems require a wireless communication network, and of late are deep learning based. In critical scenarios such as border protection or disaster response, ensuring the secure navigation of autonomous UAVs is paramount. But, these autonomous UAVs are susceptible to adversarial attacks through the communication network or the deep learning models - eavesdropping / man-in-the-middle / membership inference / reconstruction. To address this susceptibility, we propose an innovative approach that combines Reinforcement Learning (RL) and Fully Homomorphic Encryption (FHE) for secure autonomous UAV navigation. This end-to-end secure framework is designed for real-time video feeds captured by UAV cameras and utilizes FHE to perform inference on encrypted input images. While FHE allows computations on encrypted data, certain computational operators are yet to be implemented. Convolutional neural networks, fully connected neural networks, activation functions and OpenAI Gym Library are meticulously adapted to the FHE domain to enable encrypted data processing. We demonstrate the efficacy of our proposed approach through extensive experimentation. Our proposed approach ensures security and privacy in autonomous UAV navigation with negligible loss in performance.
BOFFIN TTS: Few-Shot Speaker Adaptation by Bayesian Optimization
Feb 04, 2020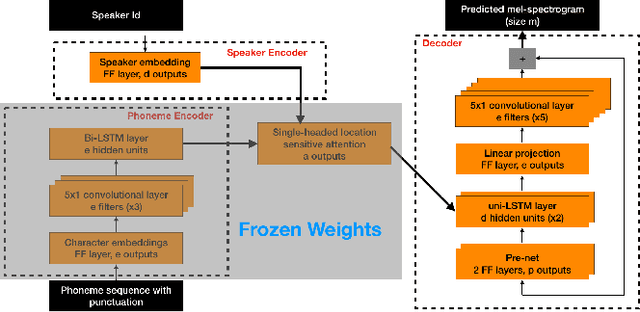

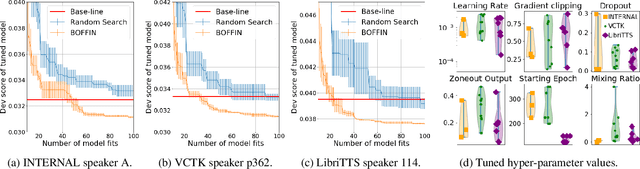
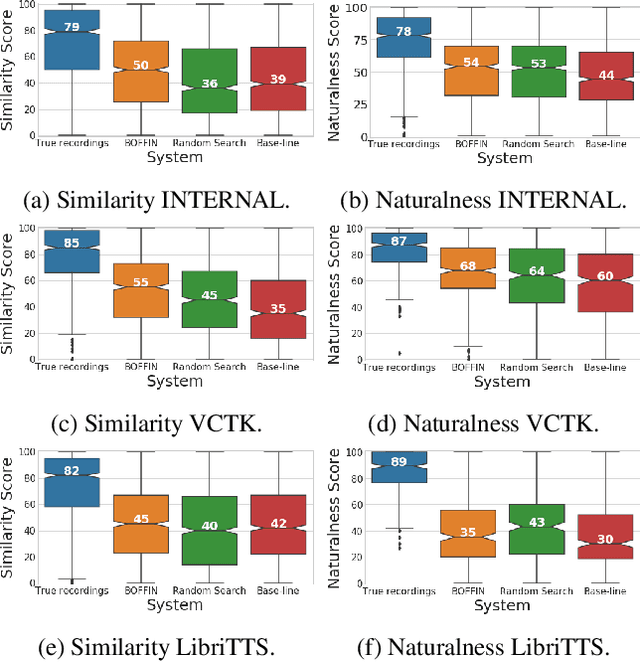
We present BOFFIN TTS (Bayesian Optimization For FIne-tuning Neural Text To Speech), a novel approach for few-shot speaker adaptation. Here, the task is to fine-tune a pre-trained TTS model to mimic a new speaker using a small corpus of target utterances. We demonstrate that there does not exist a one-size-fits-all adaptation strategy, with convincing synthesis requiring a corpus-specific configuration of the hyper-parameters that control fine-tuning. By using Bayesian optimization to efficiently optimize these hyper-parameter values for a target speaker, we are able to perform adaptation with an average 30% improvement in speaker similarity over standard techniques. Results indicate, across multiple corpora, that BOFFIN TTS can learn to synthesize new speakers using less than ten minutes of audio, achieving the same naturalness as produced for the speakers used to train the base model.
Using VAEs and Normalizing Flows for One-shot Text-To-Speech Synthesis of Expressive Speech
Nov 28, 2019
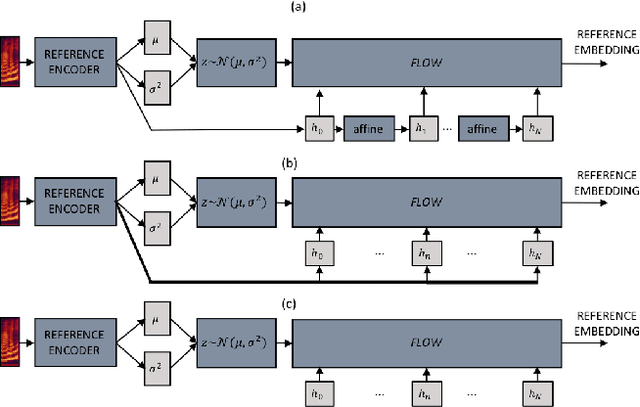


We propose a Text-to-Speech method to create an unseen expressive style using one utterance of expressive speech of around one second. Specifically, we enhance the disentanglement capabilities of a state-of-the-art sequence-to-sequence based system with a Variational AutoEncoder (VAE) and a Householder Flow. The proposed system provides a 22% KL-divergence reduction while jointly improving perceptual metrics over state-of-the-art. At synthesis time we use one example of expressive style as a reference input to the encoder for generating any text in the desired style. Perceptual MUSHRA evaluations show that we can create a voice with a 9% relative naturalness improvement over standard Neural Text-to-Speech, while also improving the perceived emotional intensity (59 compared to the 55 of neutral speech).